Publications
- Selected Papers only
- All Papers (by year)
- AI (Artificial Intelligence)
- Robotics
- Vision
-

Wikipedia for Robots. A View from Ashutosh Saxena. In MIT Technology Review about one of ten innovative technologies in 2016. [article]
@inproceedings{wikipediaforrobots-saxena-2016,
title={Wikipedia for Robots},
author={Ashutosh Saxena},
year={2016},
booktitle={MIT Technoogy Review}
}Humans have gained a lot of value by organizing all their knowledge and making it widely accessible—in textbooks, libraries, Wikipedia, and YouTube, to name a few examples.
However, the organized collections of knowledge that work for humans aren’t so great for robots. A robot wouldn’t get much useful information if it queried a search engine for how to “bring sweet tea from the kitchen.” Robots require something different—access to finer details for planning, control, and natural language understanding. -

Recurrent Neural Networks for Driver Activity Anticipation via Sensory-Fusion Architecture. Ashesh Jain, Avi Singh, Hema S Koppula, Shane Soh, and Ashutosh Saxena. In International Conference on Robotics and Automation (ICRA), 2016. [project page, arxiv]
@inproceedings{rnn-brain4cars-saxena-2016,
title={Recurrent Neural Networks for Driver Activity Anticipation via Sensory-Fusion Architecture},
author={Ashesh Jain and Avi Singh and Hema S Koppula and Shane Soh and Ashutosh Saxena},
year={2016},
booktitle={International Conference on Robotics and Automation (ICRA)}
}Abstract: Anticipating the future actions of a human is a widely studied problem in robotics that requires spatio-temporal reasoning. In this work we propose a deep learning approach for anticipation in sensory-rich robotics applications. We introduce a sensory-fusion architecture which jointly learns to anticipate and fuse information from multiple sensory streams. Our architecture consists of Recurrent Neural Networks (RNNs) that use Long Short-Term Memory (LSTM) units to capture long temporal dependencies. We train our architecture in a sequence-to-sequence prediction manner, and it explicitly learns to predict the future given only a partial temporal context. We further introduce a novel loss layer for anticipation which prevents over-fitting and encourages early anticipation. We use our architecture to anticipate driving maneuvers several seconds before they happen on a natural driving data set of 1180 miles. The context for maneuver anticipation comes from multiple sensors installed on the vehicle. Our approach shows significant improvement over the state-of-the-art in maneuver anticipation by increasing the precision from 77.4% to 90.5% and recall from 71.2% to 87.4%.
-

Deep Multimodal Embedding: Manipulating Novel Objects with Point-clouds, Language and Trajectories, Jaeyong Sung, Ian Lenz, and Ashutosh Saxena. International Conference on Robotics and Automation (ICRA), 2017. (finalist for ICRA Best cognitive robotics paper award) [PDF, arxiv, project page]
@inproceedings{robobarista_deepmultimodalembedding_2015,
title={Deep Multimodal Embedding: Manipulating Novel Objects with Point-clouds, Language and Trajectories},
author={Jaeyong Sung and Ian Lenz and Ashutosh Saxena},
year={2017},
booktitle={International Conference on Robotics and Automation (ICRA)}
}Abstract: A robot operating in a real-world environment needs to perform reasoning with a variety of sensing modalities. However, manually designing features that allow a learning algorithm to relate these different modalities can be extremely challenging. In this work, we consider the task of manipulating novel objects and appliances. To this end, we learn to embed point-cloud, natural language, and manipulation trajectory data into a shared embedding space using a deep neural network. In order to learn semantically meaningful spaces throughout our network, we introduce a method for pre-training its lower layers for multimodal feature embedding and a method for fine- tuning this embedding space using a loss-based margin. We test our model on the Robobarista dataset, where we achieve significant improvements in both accuracy and inference time over the previous state of the art.
-

Home as a Caregiver: How AI-Enabled Apartments and Homes Can Change Senior Living. Caspar.AI. Senior Housing News, Jan 2021. [article]
@inproceedings{home-as-a-caregiver-2020,
title={Home as a Caregiver: How AI-Enabled Apartments and Homes Can Change Senior Living},
author={Caspar.AI},
year={2021},
booktitle={Senior Housing News}
}For senior housing, 2020 has been a year of challenges. Some were known entering the year, namely the staffing shortage. The one that has defined the year — the COVID-19 pandemic — was a surprise.
This leaves vulnerable seniors without the support they need, despite senior housing staff’s best efforts. To solve this, one technology innovator is taking the next step in senior housing of delivering artificial intelligence to homes: AI homes. These easy-to-install AI-enabled spaces address several of today’s senior living problems, creating a new living experience suited for 2021, with a return on investment crucial for bottom line health.
This white paper shows how Caspar.AI is delivering safety, wellness and increased work efficiency, while evolving community living from high-touch to touch-free — all in a package overwhelmingly popular with residents. In short, helping turn the home into another caregiver. -
Senior Living Communities: Made Safer by AI. Ashutosh Saxena, David Cheriton. Tech report, July 2020. (Top 100 AI by CB Insights) [article]
@inproceedings{safe-senior-living-2020,
title={Senior Living Communities: Made Safer by AI},
author={Ashutosh Saxena and David Cheriton},
year={2020},
booktitle={Tech report}
}There is a historically unprecedented shift in demographics towards seniors, which will result in significant housing development over the coming decade. This is an enormous opportunity for real-estate operators to innovate and address the demand in this growing market.
However investments in this area are fraught with risk. Seniors often have more health issues, and Covid-19 has exposed just how vulnerable they are – especially those living in close proximity. Conventionally, most services for seniors are “high-touch”, requiring close physical contact with trained caregivers. Not only are trained caregivers short in supply, but the pandemic has made it evident that conventional high-touch approaches to senior care are high-cost and greater risk. There are not enough caregivers to meet the needs of this emerging demographic, and even fewer who want to undertake the additional training and risk of working in a senior facility, especially given the current pandemic.
In this article, we rethink the design of senior living facilities to mitigate the risks and costs using automation. With AI-enabled pervasive automation, we claim there is an opportunity, if not an urgency, to go from high-touch to almost "no touch" while dramatically reducing risk and cost. Although our vision goes beyond the current reality, we cite measurements from Caspar-enabled senior properties that show the potential benefit of this approach. -

Privacy-Preserving Distributed AI for Smart Homes. Caspar AI with David Cheriton and Ken Birman. Tech report, 2020. [article]
@inproceedings{privacy-preserving-distributed-ai-2020,
title={Privacy-Preserving Distributed AI for Smart Homes},
author={Caspar AI and David Cheriton and Ken Birman},
year={2020},
booktitle={Tech report}
}Distributed AI (D-AI) is enabling rapid progress on smart IoT systems, homes, and cities. D-AI refers to any AI system with discrete AI subsystems that can be combined to create ensemble-intelligences. Here, we take the next step and introduce the concept of a Privacy-Preserving IoT Cloud (PPIC) optimized to host D-AI applications close to the devices. Caspar.ai, which adopts this approach, is currently providing cost-efficient smart- home solutions for multi-family residential communities.
-
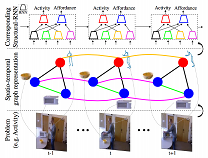
Structural-RNN: Deep Learning on Spatio-Temporal Graphs. Ashesh Jain, Amir R. Zamir, Silvio Savarese, and Ashutosh Saxena. In Computer Vision and Pattern Recognition (CVPR) oral, 2016. (best student paper) [PDF, project page, arxiv]
@inproceedings{rnn-brain4cars-saxena-2016,
title={Structural-RNN: Deep Learning on Spatio-Temporal Graphs},
author={Ashesh Jain and Amir R. Zamir and Silvio Savarese and Ashutosh Saxena},
year={2016},
booktitle={Computer Vision and Pattern Recognition (CVPR)}
}Abstract: Deep Recurrent Neural Network architectures, though remarkably capable at modeling sequences, lack an intuitive high-level spatio-temporal structure. That is while many problems in computer vision inherently have an underlying high-level structure and can benefit from it. Spatio-temporal graphs are a popular flexible tool for imposing such high-level intuitions in the formulation of real world problems. In this paper, we propose an approach for combining the power of high-level spatio-temporal graphs and sequence learning success of Recurrent Neural Networks (RNNs). We develop a scalable method for casting an arbitrary spatio-temporal graph as a rich RNN mixture that is feedforward, fully differentiable, and jointly trainable. The proposed method is generic and principled as it can be used for transforming any spatio-temporal graph through employing a certain set of well defined steps. The evaluations of the proposed approach on a diverse set of problems, ranging from modeling human motion to object interactions, shows improvement over the state-of-the-art with a large margin. We expect this method to empower a new convenient approach to problem formulation through high-level spatio-temporal graphs and Recurrent Neural Networks, and be of broad interest to the community.
-
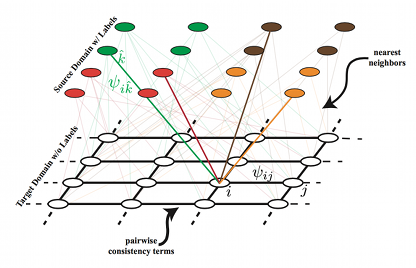
Learning Transferrable Representations for Unsupervised Domain Adaptation. Ozan Sener, Hyun Oh Song, Ashutosh Saxena, and Silvio Savarese. In Neural Information Processing Systems (NIPS) , 2016. [PDF]
@inproceedings{sener-saxena-transfer-nips-2016,
title={Learning Transferrable Representations for Unsupervised Domain Adaptation},
author={Ozan Sener and Hyun Oh Song and Ashutosh Saxena and Silvio Savarese},
year={2016},
booktitle={Neural Information Processing Systems (NIPS)}
}Abstract: Supervised learning with large scale labeled datasets and deep layered models has made a paradigm shift in diverse areas in learning and recognition. However, this approach still suffers generalization issues under the presence of a domain shift between the training and the test data distribution. In this regard, unsupervised domain adaptation algorithms have been proposed to directly address the domain shift problem. In this paper, we approach the problem from a transductive perspective. We incorporate the domain shift and the transductive target inference into our framework by jointly solving for an asymmetric similarity metric and the optimal transductive target label assignment. We also show that our model can easily be extended for deep feature learning in order to learn features which are discriminative in the target domain. Our experiments show that the proposed method significantly outperforms state-of-the-art algorithms in both object recognition and digit classification experiments by a large margin.
-

Watch-Bot: Unsupervised Learning for Reminding Humans of Forgotten Actions, Chenxia Wu, Jiemi Zhang, Bart Selman, Silvio Savarese, Ashutosh Saxena. In International Conference on Robotics and Automation (ICRA), 2016. [ArXiv PDF, PDF, journal version, project page]
@article{chenxiawu_watchnbots_icra2016,
title={Watch-Bot: Unsupervised Learning for Reminding Humans of Forgotten Actions},
author={Chenxia Wu and Jiemi Zhang and Bart Selman and Silvio Savarese and Ashutosh Saxena},
year={2016},
booktitle={International Conference on Robotics and Automation (ICRA)}
}We present a robotic system that watches a human using a Kinect v2 RGB-D sensor, detects what he forgot to do while performing an activity, and if necessary reminds the person using a laser pointer to point out the related object. Our simple setup can be easily deployed on any assistive robot.
Our approach is based on a learning algorithm trained in a purely unsupervised setting, which does not require any human annotations. This makes our approach scalable and applicable to variant scenarios. Our model learns the action/object co-occurrence and action temporal relations in the activity, and uses the learned rich relationships to infer the forgotten action and the related object. We show that our approach not only improves the unsupervised action segmentation and action cluster assignment performance, but also effectively detects the forgotten actions on a challenging human activity RGB-D video dataset. In robotic experiments, we show that our robot is able to remind people of forgotten actions successfully.
-
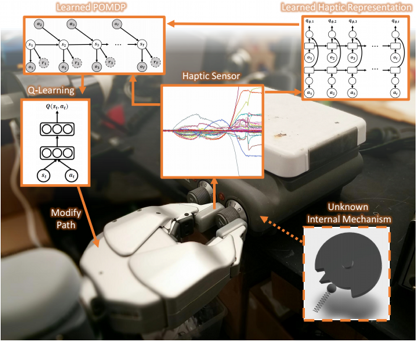
Learning to Represent Haptic Feedback for Partially-Observable Tasks, Jaeyong Sung, J. Kenneth Salisbury, Ashutosh Saxena. International Conference on Robotics and Automation (ICRA), 2017. (finalist for ICRA Best cognitive robotics paper award) [PDF]
@inproceedings{robobarista_haptic_2017,
title={Learning to Represent Haptic Feedback for Partially-Observable Tasks},
author={Jaeyong Sung and J. Kenneth Salisbury and Ashutosh Saxena},
year={2017},
booktitle={International Conference on Robotics and Automation (ICRA)}
}Abstract: coming soon
-

Robobarista: Learning to Manipulate Novel Objects via Deep Multimodal Embedding, Jaeyong Sung, Seok H Jin, Ian Lenz and Ashutosh Saxena. Cornell Tech Report, 2016. [ArXiv, project page]
@inproceedings{sung2016_robobarista_deepembedding,
title={Robobarista: Learning to Manipulate Novel Objects via Deep Multimodal Embedding},
author={Jaeyong Sung and Seok H Jin and Ian Lenz and Ashutosh Saxena},
year={2016},
booktitle={Cornell Tech Report}
}Abstract: There is a large variety of objects and appliances in human environments, such as stoves, coffee dispensers, juice extractors, and so on. It is challenging for a roboticist to program a robot for each of these object types and for each of their instantiations. In this work, we present a novel approach to manipulation planning based on the idea that many household objects share similarly-operated object parts. We formulate the manipulation planning as a structured prediction problem and learn to transfer manipulation strategy across different objects by embedding point-cloud, natural language, and manipulation trajectory data into a shared embedding space using a deep neural network. In order to learn semantically meaningful spaces throughout our network, we introduce a method for pre-training its lower layers for multimodal feature embedding and a method for fine-tuning this embedding space using a loss-based margin. In order to collect a large number of manipulation demonstrations for different objects, we develop a new crowd-sourcing platform called Robobarista. We test our model on our dataset consisting of 116 objects and appliances with 249 parts along with 250 language instructions, for which there are 1225 crowd-sourced manipulation demonstrations. We further show that our robot with our model can even prepare a cup of a latte with appliances it has never seen before.
-

Brain4Cars: Car That Knows Before You Do via Sensory-Fusion Deep Learning Architecture, Ashesh Jain, Hema S Koppula, Shane Soh, Bharad Raghavan, Avi Singh, Ashutosh Saxena. Cornell Tech Report (journal version), Jan 2016. (Earlier presented at ICCV'15.) [Arxiv PDF, project+video]
@inproceedings{misra_sung_lee_saxena_ijrr2015_groundingnlp,
title="Brain4Cars: Car That Knows Before You Do via Sensory-Fusion Deep Learning Architecture",
author="Ashesh Jain and Hema S Koppula and Shane Soh and Bharad Raghavan and Avi Singh and Ashutosh Saxena",
year="2016",
booktitle="Cornell Tech Report",
}Abstract: Advanced Driver Assistance Systems (ADAS) have made driving safer over the last decade. They prepare vehicles for unsafe road conditions and alert drivers if they perform a dangerous maneuver. However, many accidents are unavoidable because by the time drivers are alerted, it is already too late. Anticipating maneuvers beforehand can alert drivers before they perform the maneuver and also give ADAS more time to avoid or prepare for the danger.
In this work we propose a vehicular sensor-rich platform and learning algorithms for maneuver anticipation. For this purpose we equip a car with cameras, Global Positioning System (GPS), and a computing device to capture the driving context from both inside and outside of the car. In order to anticipate maneuvers, we propose a sensory-fusion deep learning architecture which jointly learns to anticipate and fuse multiple sensory streams. Our architecture consists of Recurrent Neural Networks (RNNs) that use Long Short-Term Memory (LSTM) units to capture long temporal dependencies. We propose a novel training procedure which allows the network to predict the future given only a partial temporal context. We introduce a diverse data set with 1180 miles of natural freeway and city driving, and show that we can anticipate maneuvers 3.5 seconds before they occur in real-time with a precision and recall of 90.5% and 87.4% respectively. -

Tell Me Dave: Context-Sensitive Grounding of Natural Language to Manipulation Instructions, Dipendra K Misra, Jaeyong Sung, Kevin Lee, Ashutosh Saxena. International Journal of Robotics Research (IJRR), Jan 2016. (Earlier presented at RSS'14.) [PDF, project+video]
@inproceedings{misra_sung_lee_saxena_ijrr2015_groundingnlp,
title="Tell Me Dave: Context-Sensitive Grounding of Natural Language to Manipulation Instructions",
author="Dipendra K Misra and Jaeyong Sung and Kevin Lee and Ashutosh Saxena",
year="2016",
booktitle="International Journal of Robotics Research (IJRR)",
}Abstract: It is important for a robot to be able to interpret natural language commands given by a human. In this paper, we consider performing a sequence of mobile manipulation tasks with instructions described in natural language (NL). Given a new environment, even a simple task such as of boiling water would be performed quite differently depending on the presence, location and state of the objects. We start by collecting a dataset of task descriptions in free-form natural language and the corresponding grounded task-logs of the tasks performed in an online robot simulator. We then build a library of verb-environment-instructions that represents the possible instructions for each verb in that environment - these may or may not be valid for a different environment and task context.
We present a model that takes into account the variations in natural language, and ambiguities in grounding them to robotic instructions with appropriate environment context and task constraints. Our model also handles incomplete or noisy NL instructions. Our model is based on an energy function that encodes such properties in a form isomorphic to a conditional random field. We evaluate our model on tasks given in a robotic simulator and show that it successfully outperforms the state-of-the-art with 61.8% accuracy. We also demonstrate several of grounded robotic instruction sequences on a PR2 robot through Learning from Demonstration approach. -

Learning from Large Scale Visual Data for Robots, Ozan Sener. PhD Thesis, Cornell University, 2016. [PDF, webpage]
@phdthesis{ozansener_phdthesis,
title={Learning from Large Scale Visual Data for Robots},
author={Ozan Sener},
year={2016},
school={Cornell University}
}Abstract: Humans created a tremendous value by collecting and organizing all their knowl- edge in publicly accessible forms, as in Wikipedia and YouTube. The availability of such large knowledge-bases not only changed the way we learn, it also changed how we design artificial intelligence algorithms. Recently, propelled by the avail- able data and expressive models, many successful computer vision and natural language processing algorithms have emerged. However, we did not see a simi- lar shift in robotics. Our robots are still having trouble recognizing basic objects, detecting humans, and even performing simple tasks like how to make an omelette.
In this thesis, we study the type of knowledge robots need. Our initial anal- ysis suggests that robots need a very unique type of knowledge base with many requirements like multi-modal data and physical grounding of concepts. We fur- ther design such a large-scale knowledge base and show how can it be used in many robotics tasks. Given this knowledge base, robots need to handle many challenges like scarcity of the supervision and the shift between different modali- ties and domains. We propose machine learning algorithms which can handle lack of supervision and domain shift relying only on the latent structure of the available knowledge. Although we have large-scale knowledge, it is still missing some of the cases robots can encounter. Hence, we also develop algorithms which can explic- itly model, learn and estimate the uncertainty in the robot perception again using underlying latent structure. Our algorithms show state-of-the-art performance in many robotics and computer vision benchmarks. -
Learning from Natural Human Interactions for Assistive Robots, Ashesh Jain. PhD Thesis, Cornell University, 2016. [PDF, webpage]
@phdthesis{ashesh_phdthesis,
title={Learning from Natural Human Interactions for Assistive Robots},
author={Ashesh Jain},
year={2016},
school={Cornell University}
}Abstract: Leveraging human knowledge to train robots is a core problem in robotics. In the near future we will see humans interacting with agents such as, assistive robots, cars, smart houses, etc. Agents that can elicit and learn from such interactions will find use in many applications. Previous works have proposed methods for learning low-level robotic controls or motion primitives from (near) optimal human signals. In many applications such signals are not naturally available. Furthermore, optimal human signals are also difficult to elicit from non-expert users at a large scale.
Understanding and learning user preferences from weak signals is therefore of great emphasis. To this end, in this dissertation we propose interactive learning systems which allow robots to learn by interacting with humans. We develop interaction methods that are natural to the end-user, and algorithms to learn from sub-optimal interactions. Furthermore, the interactions between humans and robots have complex spatio-temporal structure. Inspired by the recent success of powerful function approximators based on deep neural networks, we propose a generic framework for modeling interactions with structure of Recurrent Neural Networks. We demonstrate applications of our work on real-world scenarios on assistive robots and cars. This work also established state-of-the-art on several existing benchmarks. -
Learning from Natural Human Interactions for Assistive Robots, Jaeyong Sung. PhD Thesis, Cornell University, 2017. [PDF, webpage]
@phdthesis{jaeyongsung_phdthesis,
title={Learning to Manipulate Novel Objects for Assistive Robots},
author={Jaeyong Sung},
year={2017},
school={Cornell University}
}Abstract: coming soon
-
Unsupervised Structured Learning of Human Activities for Robot Perception, Chenxia Wu. PhD Thesis, Cornell University, 2016. [PDF, webpage]
@phdthesis{ozansener_phdthesis,
title={Unsupervised Structured Learning of Human Activities for Robot Perception},
author={Chenxia Wu},
year={2016},
school={Cornell University}
}Abstract: Despite structure models in the supervised settings have been well studied and widely used in different domains, discovering latent structures is still a challenging problem in the unsupervised learning. The existing works usually require more independence assumptions. In this work, we propose unsuper- vised structured learning models including causal topic model, fully connected CRF autoencoder, which have the ability of modeling more complex relations with less independence. We also design efficient learning and inference opti- mizations that makes the computations still tractable. As a result, we make more flexible and accurate robot perceptions in more interesting applications.
We first note that modeling the hierarchical semantic relations of objects as well as how objects are interacting with humans is very important to making flexible and reliable robotic perception. So we propose a hierarchical semantic labeling algorithm to producing scene labels in different levels of abstraction for specific robot tasks. We also propose an unsupervised learning algorithms to leverage the interactions between humans and objects, so that it automatically discovers the useful common object regions from a set of images.
Second, we note that it is important for a robot to be able to detect not only what a human is currently doing but also more complex relations such as action temporal relations, human-object relations. Then the robot is able to achieve better perception performance and more flexible tasks. So we propose a causal topic model to incorporating both short-term and long-term temporal relations between human actions as well as human-object relations, and we develop a new robotic system thats watches not only what a human is currently doing but also what he forgot to do, and if necessary reminds the person.
In the domain of human activities and environments, we show how to build models that can learn the semantic, spatial and temporal structures in the unsu-pervised setting. We show that these approaches are useful in multiple domains including robotics, object recognition, human activity modeling, image/video data mining, visual summarization. Since our techniques are unsupervised and structured modeled, they are easily extended and scaled to other areas, such as natural language processing, robotic planning/manipulation, or multimedia analysis, etc. -

MDPs with Unawareness in Robotics. Nan Rong, Joseph Halpern, and Ashutosh Saxena. In Uncertainty in Artificial Intelligence (UAI), 2016. [pdf]
@inproceedings{mdpu-robotics-2016,
title={MDPs with Unawareness in Robotics},
author={Nan Rong and Joseph Halpern and Ashutosh Saxena},
year={2016},
booktitle={Uncertainty in Artificial Intelligence (UAI)}
}We formalize decision-making problems in robotics and automated control using continuous MDPs and actions that take place over continuous time intervals. We then approximate the continuous MDP using finer and finer discretizations. Doing this results in a family of systems, each of which has an extremely large action space, although only a few actions are "interesting". In this sense, we say the decision maker is unaware of which actions are “interesting”. This can be modeled using MDPUs - MDPs with unawareness - where the action space is much smaller. As we show, MDPUs can be used as a general framework for learning tasks in robotic problems. We prove results on the difficulty of learning a near-optimal policy in an an MDPU for a continuous task. We apply these ideas to the problem of having a humanoid robot learn on its own how to walk.
-

Human Centred Object Co-Segmentation. Chenxia Wu, Jiemi Zhang, Ashutosh Saxena, Silvio Savarese. Cornell Tech Report, 2016. [pdf coming soon, Arxiv]
@inproceedings{mdpu-robotics-2016,
title={Human Centred Object Co-Segmentation},
author={Chenxia Wu and Jiemi Zhang and Ashutosh Saxena and Silvio Savarese},
year={2016},
booktitle={Cornell Tech Report}
}Co-segmentation is the automatic extraction of the common semantic regions given a set of images. Different from previous approaches mainly based on object visuals, in this paper, we propose a human centred object co-segmentation approach, which uses the human as another strong evidence. In order to discover the rich internal structure of the objects reflecting their human-object interactions and visual similarities, we propose an unsupervised fully connected CRF auto-encoder incorporating the rich object features and a novel human-object interaction representation. We propose an efficient learning and inference algorithm to allow the full connectivity of the CRF with the auto-encoder, that establishes pairwise relations on all pairs of the object proposals in the dataset. Moreover, the auto-encoder learns the parameters from the data itself rather than supervised learning or manually assigned parameters in the conventional CRF. In the extensive experiments on four datasets, we show that our approach is able to extract the common objects more accurately than the state-of-the-art co-segmentation algorithms.
-
Understanding People from Visual Data for Assistive Robots, Hema S Koppula. PhD Thesis, Cornell University, 2015. [PDF, webpage]
@phdthesis{hema_phdthesis,
title={Understanding People from Visual Data for Assistive Robots},
author={Hema S Koppula},
year={2015},
school={Cornell University}
}Abstract: Understanding people in complex dynamic environments is important for many applications such as robotic assistants, health-care monitoring systems, self driving cars, etc. This is a challenging problem as human actions and in- tents are not always observable and often contain large amounts of ambiguity. Moreover, human environments are complex with lots of objects and many pos- sible ways of interacting with them. This leads to a huge variation in the way people perform various tasks.
The focus of this dissertation is to develop learning algorithms for under- standing people and their environments from RGB-D data. We address the problems of labeling environments, detecting past activities and anticipating what will happen in the future. In order to enable agents operating in human environments to perform holistic reasoning, we need to jointly model the hu- mans, objects and environments and capture the rich context between them.
We propose graphical models that naturally capture the rich spatio-temporal relations between human poses and objects in a 3D scene. We propose an effi- cient method to sample multiple possible graph structures and reason about the many alternate future possibilities. Our models also provide a functional rep- resentation of the environments, allowing agents to reactively plan their own actions to assist in the activities. We applied these algorithms successfully on our robot for performing various assistive tasks ranging from finding objects in large cluttered rooms to working alongside humans in collaborative tasks. -
Deep Learning for Robotics, Ian Lenz. PhD Thesis, Cornell University, 2015. [PDF, webpage]
@phdthesis{ianlenz_phdthesis,
title={Deep Learning for Robotics},
author={Ian Lenz},
year={Dec 2015},
school={Cornell University}
}Abstract: Robotics faces many unique challenges as robotic platforms move out of the lab and into the real world. In particular, the huge amount of variety encountered in real-world environments is extremely challenging for existing robotic control algorithms to handle. This necessistates the use of machine learning algorithms, which are able to learn controls given data. However, most conventional learning algorithms require hand-designed parameterized models and features, which are infeasible to design for many robotic tasks. Deep learning algorithms are general non-linear models which are able to learn features directly from data, making them an excellent choice for such robotics applications. However, care must be taken to design deep learning algorithms and supporting systems appropriate for the task at hand. In this work, I describe two applications of deep learning algorithms and one application of hardware neural networks to difficult robotics problems. The problems addressed are robotic grasping, food cutting, and aerial robot obstacle avoidance, but the algorithms presented are designed to be generalizable to related tasks.
-
Hallucinated Humans: Learning Latent Factors to Model 3D Environments, Yun Jiang. PhD Thesis, Cornell University, 2015. [PDF, webpage]
@phdthesis{yunjiang_phdthesis,
title={Hallucinated Humans: Learning Latent Factors to Model 3D Environments},
author={Yun Jiang},
year={2015},
school={Cornell University}
}Abstract: The ability to correctly reason human environment is critical for personal robots. For example, if a robot is asked to tidy a room, it needs to detect object types, such as shoes and books, and then decides where to place them properly. Some- times being able to anticipate human-environment interactions is also desirable. For example, the robot would not put any object on the chair if it understands that humans would sit on it.
The idea of modeling object-object relations has been widely leveraged in many scene understanding applications. For instance, the object found in front of a monitor is more likely to be a keyboard because of the high correlation of the two objects. However, as the objects are designed by humans and for human usage, when we reason about a human environment, we reason about it through an interplay between the environment, objects and humans. For example, the objects, monitor and keyboard, are strongly spatially correlated only because a human types on the keyboard while watching the monitor. The key idea of this thesis is to model environments not only through objects, but also through latent human poses and human-object interactions.
We start by designing a generic form of human-object interaction, also re- ferred as ‘object affordance’. Human-object relations can thus be quantified through a function of object affordance, human configuration and object con-figuration. Given human poses and object affordances, we can capture the rela- tions among humans, objects and the scene through Conditional Random Fields (CRFs). For scenarios where no humans present, our idea is to still leverage the human-object relations by hallucinating potential human poses.
In order to handle the large number of latent human poses and a large va- riety of their interactions with objects, we present Infinite Latent Conditional Random Field (ILCRF) that models a scene as a mixture of CRFs generated from Dirichlet processes. In each CRF, we model objects and object-object relations as existing nodes and edges, and hidden human poses and human-object rela- tions as latent nodes and edges. ILCRF generatively models the distribution of different CRF structures over these latent nodes and edges.
We apply the model to the challenging applications of 3D scene labeling and robotic scene arrangement. In extensive experiments, we show that our model significantly outperforms the state-of-the-art results in both applications. We test our algorithm on a robot for arranging objects in a new scene using the two applications aforementioned. We further extend the idea of hallucinating static human poses to anticipating human activities. We also present learning-based grasping and placing approaches for low-level manipulation tasks in compli- mentary to the high-level scene understanding tasks. -

Unsupervised Semantic Parsing of Video Collections, Ozan Sener, Amir Zamir, Silvio Savarese, and Ashutosh Saxena. In International Conference on Computer Vision (ICCV), 2015. [project page, arxiv, PDF]
@inproceedings{sener2015_unsupervisedvideo,
title={Unsupervised Semantic Parsing of Video Collections},
author={Ozan Sener and Amir Zamir and Silvio Savarese and Ashutosh Saxena},
year={2015},
booktitle={International Conference on Computer Vision (ICCV)}
}Abstract: Human communication typically has an underlying structure. This is reflected in the fact that in many user generated videos, a starting point, ending, and certain objective steps between these two can be identified. In this paper, we propose a method for parsing a video into such semantic steps in an unsupervised way. The proposed method is capable of providing a semantic “storyline” of the video composed of its objective steps. We accomplish this using both visual and language cues in a joint generative model. The proposed method can also provide a textual description for each of the identified semantic steps and video segments. We evaluate this method on a large number of complex YouTube videos and show results of unprecedented quality for this intricate and impactful problem.
-
Robobarista: Object Part based Transfer of Manipulation Trajectories from Crowd-sourcing in 3D Pointclouds, Jaeyong Sung, Seok H Jin, and Ashutosh Saxena. International Symposium on Robotics Research (ISRR), 2015. [PDF, arxiv, project page]
@inproceedings{sung2015_robobarista,
title={Robobarista: Object Part based Transfer of Manipulation Trajectories from Crowd-sourcing in 3D Pointclouds},
author={Jaeyong Sung and Seok H Jin and Ashutosh Saxena},
year={2015},
booktitle={International Symposium on Robotics Research (ISRR)}
}Abstract: There is a large variety of objects and appliances in human environments, such as stoves, coffee dispensers, juice extractors, and so on. It is challenging for a roboticist to program a robot for each of these object types and for each of their instantiations. In this work, we present a novel approach to manipulation planning based on the idea that many household objects share similarly-operated object parts. We formulate the manipulation planning as a structured prediction problem and design a deep learning model that can handle large noise in the manipulation demonstrations and learns features from three different modalities: point-clouds, language and trajectory. In order to collect a large number of manipulation demonstrations for different objects, we developed a new crowd-sourcing platform called Robobarista. We test our model on our dataset consisting of 116 objects with 249 parts along with 250 language instructions, for which there are 1225 crowd-sourced manipulation demonstrations. We further show that our robot can even manipulate objects it has never seen before.
-
Car that Knows Before You Do: Anticipating Maneuvers via Learning Temporal Driving Models. Ashesh Jain, Hema S Koppula, Bharad Raghavan, and Ashutosh Saxena. In International Conference on Computer Vision (ICCV), 2015. [PDF, Arxiv, project page]
@inproceedings{jain2015_brain4cars,
title={Know Before You Do: Anticipating Maneuvers via Learning Temporal Driving Models},
author={Ashesh Jain and Hema S Koppula and Bharad Raghavan and Ashutosh Saxena},
year={2015},
booktitle={Cornell Tech Report}
}Abstract: Advanced Driver Assistance Systems (ADAS) have made driving safer over the last decade. They prepare vehicles for unsafe road conditions and alert drivers if they perform a dangerous maneuver. However, many accidents are unavoidable because by the time drivers are alerted, it is already too late. Anticipating maneuvers a few seconds beforehand can alert drivers before they perform the maneuver and also give ADAS more time to avoid or prepare for the danger. Anticipation requires modeling the driver’s action space, events inside the vehicle such as their head movements, and also the outside environment. Performing this joint modeling makes anticipation a challenging problem.
In this work we anticipate driving maneuvers a few seconds before they occur. For this purpose we equip a car with cameras and a computing device to capture the context from both inside and outside of the car. We represent the context with expressive features and propose an Autoregressive Input-Output HMM to model the contextual information. We evaluate our approach on a diverse data set with 1180 miles of natural freeway and city driving and show that we can anticipate maneuvers 3.5 seconds before they occur with over 80% F1-score. Our computation time during inference is under 3.6 milliseconds.
-

DeepMPC: Learning Deep Latent Features for Model Predictive Control. Ian Lenz, Ross Knepper, and Ashutosh Saxena. In Robotics Science and Systems (RSS), 2015. (full oral) [PDF, extended version PDF, project page]
@inproceedings{deepmpc-lenz-knepper-saxena-rss2015,
title={DeepMPC: Learning Deep Latent Features for Model Predictive Control},
author={Ian Lenz and Ross Knepper and Ashutosh Saxena},
year={2015},
booktitle={Robotics Science and Systems (RSS)}
}Abstract: Designing controllers for tasks with complex non-linear dynamics is extremely challenging, time-consuming, and in many cases, infeasible. This difficulty is exacerbated in tasks such as robotic food-cutting, in which dynamics might vary both with environmental properties, such as material and tool class, and with time while acting. In this work, we present DeepMPC, an online real-time model-predictive control approach designed to handle such difficult tasks. Rather than hand-design a dynamics model for the task, our approach uses a novel deep architecture and learning algorithm, learning controllers for complex tasks directly from data. We validate our method in experiments on a large-scale dataset of 1488 material cuts for 20 diverse classes, and in 450 real-world robotic experiments, demonstrating significant improvement over several other approaches.
-

rCRF: Recursive Belief Estimation over CRFs in RGB-D Activity Videos. Ozan Sener, Ashutosh Saxena. In Robotics Science and Systems (RSS), 2015. [PDF]
@inproceedings{rcrf-sener-saxena-rss2015,
title={rCRF: Recursive Belief Estimation over CRFs in RGB-D Activity Videos},
author={Ozan Sener and Ashutosh Saxena},
year={2015},
booktitle={Robotics Science and Systems (RSS)}
}Abstract: For assistive robots, anticipating the future actions of humans is an essential task. This requires modelling both the evolution of the activities over time and the rich relationships between humans and the objects. Since the future activities of humans are quite ambiguous, robots need to assess all the future possibilities in order to choose an appropriate action. Therefore, a successful anticipation algorithm needs to compute all plausible future activities and their corresponding probabilities.
In this paper, we address the problem of efficiently computing beliefs over future human activities from RGB-D videos. We present a new recursive algorithm that we call Recursive Conditional Random Field (rCRF) which can compute an accurate belief over a temporal CRF model. We use the rich modelling power of CRFs and describe a computationally tractable inference algorithm based on Bayesian filtering and structured diversity. In our experiments, we show that incorporating belief, computed via our approach, significantly outperforms the state-of-the-art methods, in terms of accuracy and computation time.
-
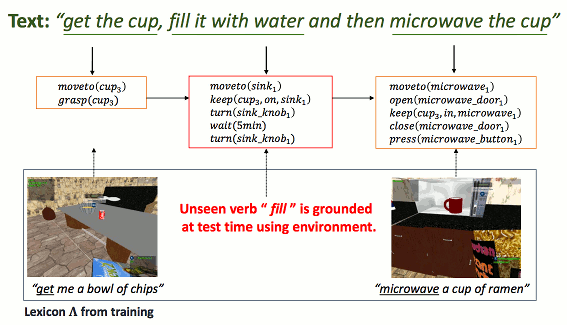
Environment-Driven Lexicon Induction for High-Level Instructions. Dipendra K Misra, Kejia Tao, Percy Liang, and Ashutosh Saxena. Association for Computational Linguistics (ACL), 2015. [PDF, supplementary material, project page]
@inproceedings{misra_acl2015_environmentdrivenlexicon,
title={Environment-Driven Lexicon Induction for High-Level Instructions},
author={Dipendra K Misra and Kejia Tao and Percy Liang and Ashutosh Saxena},
year={2015},
booktitle={Association for Computational Linguistics (ACL)}
}Abstract: We focus on the task of interpreting complex natural language instructions to a robot, in which we must ground high-level commands such as microwave the cup to low-level actions such as grasping. Previous approaches that learn a lexicon during training have inadequate coverage at test time, and pure search strategies cannot handle the exponential search space. We propose a new hybrid approach that leverages the environment to induce new lexical entries at test time, even for new verbs. Our semantic parsing model jointly reasons about the text, logical forms, and environment over multi-stage instruction sequences. We introduce a new dataset and show that our approach is able to successfully ground new verbs such as distribute, mix, arrange to complex logical forms, each containing up to four predicates.
-

Anticipating Human Activities using Object Affordances for Reactive Robotic Response, Hema S Koppula, Ashutosh Saxena. IEEE Transactions in Pattern Analysis and Machine Intelligence (PAMI), 2015. (Earlier best student paper award in RSS'13) [PDF, project page]
@inproceedings{koppula2015_anticipatingactivities,
title={Anticipating Human Activities using Object Affordances for Reactive Robotic Response},
author={Hema Koppula and Ashutosh Saxena},
year={2015},
booktitle={IEEE Trans PAMI}
}Abstract: An important aspect of human perception is anticipation, which we use extensively in our day-to-day activities when interacting with other humans as well as with our surroundings. Anticipating which activities will a human do next (and how) can enable an assistive robot to plan ahead for reactive responses. Furthermore, anticipation can even improve the detection accuracy of past activities. The challenge, however, is two-fold: We need to capture the rich context for modeling the activities and object affordances, and we need to anticipate the distribution over a large space of future human activities. In this work, we represent each possible future using an anticipatory temporal conditional random field (ATCRF) that models the rich spatial-temporal relations through object affordances. We then consider each ATCRF as a particle and represent the distribution over the potential futures using a set of particles. In extensive evaluation on CAD-120 human activity RGB-D dataset, we first show that anticipation improves the state-of-the-art detection results. We then show that for new subjects (not seen in the training set), we obtain an activity anticipation accuracy (defined as whether one of top three predictions actually happened) of 84.1%, 74.4% and 62.2% for an anticipation time of 1, 3 and 10 seconds respectively. Finally, we also show a robot using our algorithm for performing a few reactive responses.
-

Deep Learning for Detecting Robotic Grasps, Ian Lenz, Honglak Lee, Ashutosh Saxena. International Journal on Robotics Research (IJRR), 2015. [IJRR link, PDF, more]
@article{lenz2015_deeplearning_roboticgrasp_ijrr,
title={Deep Learning for Detecting Robotic Grasps},
author={Ian Lenz and Honglak Lee and Ashutosh Saxena},
year={2015},
journal={IJRR}
}Abstract: We consider the problem of detecting robotic grasps in an RGBD view of a scene containing objects. In this work, we apply a deep learning approach to solve this problem, which avoids time-consuming hand-design of features. This presents two main challenges. First, we need to evaluate a huge number of candidate grasps. In order to make detection fast and robust, we present a two-step cascaded system with two deep networks, where the top detections from the first are re-evaluated by the second. The first network has fewer features, is faster to run, and can effectively prune out unlikely candidate grasps. The second, with more features, is slower but has to run only on the top few detections. Second, we need to handle multimodal inputs effectively, for which we present a method that applies structured regularization on the weights based on multimodal group regularization. We show that our method improves performance on an RGBD robotic grasping dataset, and can be used to successfully execute grasps on two different robotic platforms.
(An earlier version was presented in Robotics Science and Systems (RSS) 2013.)
-

Learning Preferences for Manipulation Tasks from Online Coactive Feedback, Ashesh Jain, Shikhar Sharma, Thorsten Joachims, Ashutosh Saxena. In International Journal of Robotics Research (IJRR), 2015. [PDF, project+video]
@inproceedings{jainsaxena2015_learningpreferencesmanipulation,
title="Learning Preferences for Manipulation Tasks from Online Coactive Feedback",
author="Ashesh Jain and Shikhar Sharma and Thorsten Joachims and Ashutosh Saxena",
year="2015",
booktitle="International Journal of Robotics Research (IJRR)",
}Abstract: We consider the problem of learning preferences over trajectories for mobile manipulators such as personal robots and assembly line robots. The preferences we learn are more intricate than simple geometric constraints on trajectories; they are rather governed by the surrounding context of various objects and human interactions in the environment. We propose a coactive online learning framework for teaching preferences in contextually rich environments. The key novelty of our approach lies in the type of feedback expected from the user: the human user does not need to demonstrate optimal trajectories as training data, but merely needs to iteratively provide trajectories that slightly improve over the trajectory currently proposed by the system. We argue that this coactive preference feedback can be more easily elicited than demonstrations of optimal trajectories. Nevertheless, theoretical regret bounds of our algorithm match the asymptotic rates of optimal trajectory algorithms. We implement our algorithm on two high-degree-of-freedom robots, PR2 and Baxter, and present three intuitive mechanisms for providing such incremental feedback. In our experimental evaluation we consider two context rich settings, household chores and grocery store checkout, and show that users are able to train the robot with just a few feedbacks (taking only a few minutes).
Earlier version of this work was presented at the NIPS'13 and ISRR'13.
-

Modeling 3D Environments through Hidden Human Context. Yun Jiang, Hema S Koppula, Ashutosh Saxena. IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2015. [PDF]
@article{jiang-modeling3denvironemnts-hiddenhumans-2015,
title={Modeling 3D Environments through Hidden Human Context},
author={Yun Jiang and Hema S Koppula and Ashutosh Saxena},
year={2015},
journal={Tech Report}
}Abstract: The idea of modeling object-object relations has been widely leveraged in many scene understanding applications. However, as the objects are designed by humans and for human usage, when we reason about a human environment, we reason about it through an interplay between the environment, objects and humans. In this paper, we model environments not only through objects, but also through latent human poses and human-object interactions.
In order to handle the large number of latent human poses and a large variety of their interactions with objects, we present Infinite Latent Conditional Random Field (ILCRF) that models a scene as a mixture of CRFs generated from Dirichlet processes. In each CRF, we model objects and object-object relations as existing nodes and edges, and hidden human poses and human-object relations as latent nodes and edges. ILCRF generatively models the distribution of different CRF structures over these latent nodes and edges. We apply the model to the challenging applications of 3D scene labeling and robotic scene arrangement. In extensive experiments, we show that our model significantly outperforms the state-of-the-art results in both applications. We further use our algorithm on a robot for arranging objects in a new scene using the two applications aforementioned.
Parts of this journal submission have been published as the following conference papers: ICML'12 (scene arrangement), ISER'12 (robotics scene arrangement), CVPR'13 (oral, 3D scene labeling), and RSS'13 (ILCRF algorithm for scene arrangement)
-

Watch-n-Patch: Unsupervised Understanding of Actions and Relations, Chenxia Wu, Jiemi Zhang, Silvio Savarese, Ashutosh Saxena. In Computer Vision and Pattern Recognition (CVPR), 2015. [PDF, journal version, project page]
@article{chenxiawu_watchnpatch_2015,
title={Watch-n-Patch: Unsupervised Understanding of Actions and Relations},
author={Chenxia Wu and Jiemi Zhang and Silvio Savarese and Ashutosh Saxena},
year={2015},
booktitle={Computer Vision and Pattern Recognition (CVPR)}
}We focus on modeling human activities comprising multiple actions in a completely unsupervised setting. Our model learns the high-level action co-occurrence and temporal relations between the actions in the activity video. We consider the video as a sequence of short-term action clips, called action-words, and an activity is about a set of action-topics indicating which actions are present in the video. Then we propose a new probabilistic model relating the action-words and the action-topics. It allows us to model long-range action relations that commonly exist in the complex activity, which is challenging to capture in the previous works.
We apply our model to unsupervised action segmentation and recognition, and also to a novel application that detects forgotten actions, which we call action patching. For evaluation, we also contribute a new challenging RGB-D activity video dataset recorded by the new Kinect v2, which contains several human daily activities as compositions of multiple actions interacted with different objects. The extensive experiments show the effectiveness of our model.
-

PlanIt: A Crowdsourcing Approach for Learning to Plan Paths from Large Scale Preference Feedback. Ashesh Jain, Debarghya Das, Ashutosh Saxena. In International Conference on Robotics and Automation (ICRA), 2015. [PDF, PlanIt website]
@inproceedings{planit-jain-das-saxena-2014,
title={PlanIt: A Crowdsourcing Approach for Learning to Plan Paths from Large Scale Preference Feedback},
author={Ashesh Jain and Debarghya Das and Ashutosh Saxena},
year={2015},
booktitle={ICRA}
}Abstract: We consider the problem of learning user preferences over robot trajectories in environments rich in objects and humans. This is challenging because the criterion defining a good trajectory varies with users, tasks and interactions in the environments. We use a cost function to represent how preferred the trajectory is; the robot uses this cost function to generate a trajectory in a new environment. In order to learn this cost function, we design a system - PlanIt, where non-expert users can see robots motion for different asks and label segments of the video as good/bad/neutral. Using this weak, noisy labels, we learn the parameters of our model. Our model is a generative one, where the preferences are expressed as function of grounded object affordances. We test our approach on 112 different environments, and our extensive experiments show that we can learn meaningful preferences in the form of grounded planning affordances, and then use them to generate preferred trajectories in human environments.
-

Robo Brain: Large-Scale Knowledge Engine for Robots, Ashutosh Saxena, Ashesh Jain, Ozan Sener, Aditya Jami, Dipendra K Misra, Hema S Koppula. International Symposium on Robotics Research (ISRR), 2015. [PDF, arxiv, project page] (Earlier Cornell Tech Report, Aug 2014.)
@article{saxena_robobrain2014,
title={Robo Brain: Large-Scale Knowledge Engine for Robots},
author={Ashutosh Saxena and Ashesh Jain and Ozan Sener and Aditya Jami and Dipendra K Misra and Hema S Koppula},
year={2015},
journal={International Symposium on Robotics Research (ISRR)}
}Abstract: In this paper we introduce a knowledge engine, which learns and shares knowledge representations, for robots to carry out a variety of tasks. Building such an engine brings with it the challenge of dealing with multiple data modalities including symbols, natural language, haptic senses, robot trajectories, visual features and many others. The knowledge stored in the engine comes from multiple sources including physical interactions that robots have while performing tasks (perception, planning and control), knowledge bases from the Internet and learned representations from several robotics research groups.
We discuss various technical aspects and associated challenges such as modeling the correctness of knowledge, inferring latent information and formulating different robotic tasks as queries to the knowledge engine. We describe the system architecture and how it supports different mechanisms for users and robots to interact with the engine. Finally, we demonstrate its use in three important research areas: grounding natural language, perception, and planning, which are the key building blocks for many robotic tasks. This knowledge engine is a collaborative effort and we call it RoboBrain: http://www.robobrain.me
-
Tell Me Dave: Context-Sensitive Grounding of Natural Language to Mobile Manipulation Instructions, Dipendra K Misra, Jaeyong Sung, Kevin Lee, Ashutosh Saxena. In Robotics: Science and Systems (RSS), 2014. [PDF, project+video]
@inproceedings{misra_sung_lee_saxena_rss2014_groundingnlp,
title="Tell Me Dave: Context-Sensitive Grounding of Natural Language to Mobile Manipulation Instructions",
author="Dipendra K Misra and Jaeyong Sung and Kevin Lee and Ashutosh Saxena",
year="2014",
booktitle="Robotics: Science and Systems (RSS)",
}Abstract: We consider performing a sequence of mobile manipulation tasks with instructions given in natural language (NL). Given a new environment, even a simple task such as of boiling water would be performed quite differently depending on the presence, location and state of the objects. We start by collecting a dataset of task descriptions in free-form natural language and the corresponding grounded task-logs of the tasks performed in a robot simulator. We then build a library of verb-environment-instructions that represent possible instructions for each verb in that environment---these may or may not be valid for a different environment and task context.
We present a model that takes into account the variations in natural language, and ambiguities in grounding them to robotic instructions with appropriate environment context and task constraints. Our model also handles incomplete or noisy NL instructions. Our model is based on an energy function that encodes such properties in a form isomorphic to a conditional random field. In evaluation, we show that our model produces sequences that perform the task successfully in a simulator and also significantly outperforms the state-of-the-art. We also demonstrate that our output instruction sequences being performed on a PR2 robot.
-

Learning Haptic Representation for Manipulating Deformable Food Objects. Mevlana Gemici, Ashutosh Saxena. In International Conference on Intelligent Robotics and Systems (IROS), 2014. (best cognitive robotics paper award) [PDF, video]
@inproceedings{gemici-saxena-learninghaptic_food_2014,
title={Learning Haptic Representation for Manipulating Deformable Food Objects},
author={Mevlana Gemici and Ashutosh Saxena},
year={2014},
booktitle={IROS}
}Abstract: Manipulation of complex deformable semi-solids such as food objects is an important skill for personal robots to have. In this work, our goal is to model and learn the physical properties of such objects. We design actions involving use of tools such as forks and knives that obtain haptic data containing information about the physical properties of the object. We then design appropriate features and use supervised learning to map these features to certain physical properties (hardness, plasticity, elasticity, tensile strength, brittleness, adhesiveness). Additionally, we present a method to compactly represent the robot's beliefs about the object's properties using a generative model, which we use to plan appropriate manipulation actions. We extensively evaluate our approach on a dataset including haptic data from 12 categories of food (including categories not seen before by the robot) obtained in 941 experiments. Our robot prepared a salad during 60 sequential robotic experiments where it made a mistake in only 4 instances.
-
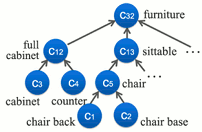
Hierarchical Semantic Labeling for Task-Relevant RGB-D Perception, Chenxia Wu, Ian Lenz, Ashutosh Saxena. In Robotics: Science and Systems (RSS), 2014. [PDF, webpage]
@inproceedings{wulenzsaxena2014_hierarchicalrgbdlabeling,
title="Hierarchical Semantic Labeling for Task-Relevant RGB-D Perception",
author="Chenxia Wu and Ian Lenz and Ashutosh Saxena",
year="2014",
booktitle="Robotics: Science and Systems (RSS)",
}Abstract: Semantic labeling of RGB-D scenes is very important in enabling robots to perform mobile manipulation tasks, but different tasks may require entirely different sets of labels. For example, when navigating to an object, we may need only a single label denoting its class, but to manipulate it, we might need to identify individual parts. In this work, we present an algorithm that produces hierarchical labelings of a scene, following is-part-of and is-type-of relationships. Our model is based on a Conditional Random Field that relates pixel-wise and pair-wise observations to labels. We encode hierarchical labeling constraints into the model while keeping inference tractable. Our model thus predicts different specificities in labeling based on its confidence---if it is not sure whether an object is Pepsi or Sprite, it will predict soda rather than making an arbitrary choice. In extensive experiments, both offline on standard datasets as well as in online robotic experiments, we show that our model outperforms other state-of-the-art methods in labeling performance as well as in success rate for robotic tasks.
-
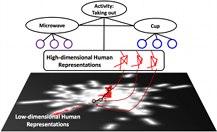
Modeling High-Dimensional Humans for Activity Anticipation using Gaussian Process Latent CRFs, Yun Jiang, Ashutosh Saxena. In Robotics: Science and Systems (RSS), 2014. [PDF]
@inproceedings{jiangsaxena2014_humanmodeling-gplcrf,
title="Modeling High-Dimensional Humans for Activity Anticipation using Gaussian Process Latent CRFs",
author="Yun Jiang and Ashutosh Saxena",
year="2014",
booktitle="Robotics: Science and Systems (RSS)",
}Abstract: For robots, the ability to model human configurations and temporal dynamics is crucial for the task of anticipating future human activities, yet requires conflicting properties: On one hand, we need a detailed high-dimensional description of human configurations to reason about the physical plausibility of the prediction; on the other hand, we need a compact representation to be able to parsimoniously model the relations between the human and the environment.
We therefore propose a new model, GP-LCRF, which admits both the high-dimensional and low-dimensional representation of humans. It assumes that the high-dimensional representation is generated from a latent variable corresponding to its low-dimensional representation using a Gaussian process. The generative process not only defines the mapping function between the high- and low-dimensional spaces, but also models a distribution of humans embedded as a potential function in GP-LCRF along with other potentials to jointly model the rich context among humans, objects and the activity. Through extensive experiments on activity anticipation, we show that our GP-LCRF consistently outperforms the state-of-the-art results and reduces the predicted human trajectory error by 11.6%.
-
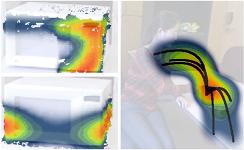
Physically-Grounded Spatio-Temporal Object Affordances. Hema S Koppula, Ashutosh Saxena. In European Conference on Computer Vision (ECCV), 2014. [PDF, webpage]
@article{koppula-anticipatoryplanning-iser2014,
title={Physically-Grounded Spatio-Temporal Object Affordances},
author={Hema Koppula and Ashutosh Saxena},
year={2014},
journal={ECCV}
}Abstract: Objects in human environments support various functionalities which govern how people interact with their environments in order to perform tasks. In this work, we discuss how to represent and learn a functional understanding of an environment in terms of object affordances. Such an understanding is useful for many applications such as activity detection and assistive robotics. Starting with a semantic notion of affordances, we present a generative model that takes a given environment and human intention into account, and grounds the affordances in the form of spatial locations on the object and temporal trajectories in the 3D environment. The probabilistic model also allows uncertainties and variations in the grounded affordances. We apply our approach on RGB-D videos from Cornell Activity Dataset, where we first show that we can successfully ground the affordances, and we then show that learning such affordances improves performance in the labeling tasks.
-

Anticipatory Planning for Human-Robot Teams. Hema S Koppula, Ashesh Jain, Ashutosh Saxena. In 14th International Symposium on Experimental Robotics (ISER), 2014. [PDF, webpage]
@article{koppula-anticipatoryplanning-iser2014,
title={Anticipatory Planning for Human-Robot Teams},
author={Hema Koppula and Ashesh Jain and Ashutosh Saxena},
year={2014},
journal={ISER}
}Abstract: When robots work alongside humans for performing collaborative tasks, they need to be able to anticipate human's future actions and plan appropriate actions. The tasks we consider are performed in contextually-rich environments containing objects, and there is a large variation in the way humans perform these tasks. We use a graphical model to represent the state-space, where we model the humans through their low-level kinematics as well as their high-level intent, and model their interactions with the objects through physically-grounded object affordances. This allows our model to anticipate a belief about possible future human actions, and we model the human's and robot's behavior through an MDP in this rich state-space. We further discuss that due to perception errors and the limitations of the model, the human may not take the optimal action and therefore we present robot's anticipatory planning with different behaviors of the human within the model's scope. In experiments on Cornell Activity Dataset, we show that our method performs better than various baselines for collaborative planning.
-

3D Reasoning from Blocks to Stability. Zhaoyin Jia, Andy Gallagher, Ashutosh Saxena, Tsuhan Chen. In IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2014. [PDF]
@article{jia-3d-stability-pami,
title={3D Reasoning from Blocks to Stability},
author={Zhaoyin Jia and Andy Gallagher and Ashutosh Saxena and Tsuhan Chen},
year={2014},
journal={IEEE Trans PAMI}
}Abstract: Objects occupy physical space and obey physical laws. To truly understand a scene, we must reason about the space that objects in it occupy, and how each objects is supported stably by each other. In other words, we seek to understand which objects would, if moved, cause other objects to fall. This 3D volumetric reasoning is important for many scene understanding tasks, ranging from segmentation of objects to perception of a rich 3D, physically well-founded, interpretations of the scene. In this paper, we propose a new algorithm to parse a single RGB-D image with 3D block units while jointly reasoning about the segments, volumes, supporting relationships and object stability. Our algorithm is based on the intuition that a good 3D representation of the scene is one that fits the depth data well, and is a stable, self-supporting arrangement of objects (i.e., one that does not topple). We design an energy function for representing the quality of the block representation based on these properties. Our algorithm fits 3D blocks to the depth values corresponding to image segments, and iteratively optimizes the energy function. Our proposed algorithm is the first to consider stability of objects in complex arrangements for reasoning about the underlying structure of the scene. Experimental results show that our stability-reasoning framework improves RGB-D segmentation and scene volumetric representation.
-

Synthesizing Manipulation Sequences for Under-Specified Tasks using Unrolled Markov Random Fields. Jaeyong Sung, Bart Selman, Ashutosh Saxena. In International Conference on Intelligent Robotics and Systems (IROS), 2014. [PDF]
@inproceedings{sung-selman-saxena-learningsequenceofcontrollers_2014,
title={Synthesizing Manipulation Sequences for Under-Specified Tasks using Unrolled Markov Random Fields},
author={Jaeyong Sung and Bart Selman and Ashutosh Saxena},
year={2014},
booktitle={IROS}
}Abstract: Many tasks in human environments require performing a sequence of navigation and manipulation steps involving objects. In unstructured human environments, the location and configuration of the objects involved often change in unpredictable ways. This requires a high-level planning strategy that is robust and flexible in an uncertain environment. We propose a novel dynamic planning strategy, which can be trained from a set of example sequences. High level tasks are expressed as a sequence of primitive actions or controllers (with appropriate parameters). Our score function, based on Markov Random Field (MRF), captures the relations between environment, controllers, and their arguments. By expressing the environment using sets of attributes, the approach generalizes well to unseen scenarios. We train the parameters of our MRF using a maximum margin learning method. We provide a detailed empirical validation of our overall framework demonstrating successful plan strategies for a variety of tasks.
-

Special issue on autonomous grasping and manipulation. Heni Ben Amor, Ashutosh Saxena, Nicolas Hudson, Jan Peters. Autonomous Robots, Volume 36, Issue 1-2, January 2014. [PDF, Special issue link]
@book{specialissuemanipulation2013,
title="Special issue on autonomous grasping and manipulation",
editor="Heni Ben Amor and Ashutosh Saxena and Nicolas Hudson and Jan Peters",
year="2014",
publisher="Springer: Autonomous Robots"
} -
Learning Trajectory Preferences for Manipulators via Iterative Improvement, Ashesh Jain, Brian Wojcik, Thorsten Joachims, Ashutosh Saxena. In Neural Information Processing Systems (NIPS), 2013. [PDF, project+video]
@inproceedings{jainsaxena2013_trajectorypreferences,
title="Learning Trajectory Preferences for Manipulators via Iterative Improvement",
author="Ashesh Jain and Brian Wojcik and Thorsten Joachims and Ashutosh Saxena",
year="2013",
booktitle="Neural Information Processing Systems (NIPS)",
}Abstract: We consider the problem of learning good trajectories for manipulation tasks. This is challenging because the criterion defining a good trajectory varies with users, tasks and environments. In this paper, we propose a co-active online learning framework for teaching robots the preferences of its users for object manipulation tasks. The key novelty of our approach lies in the type of feedback expected from the user: the human user does not need to demonstrate optimal trajectories as training data, but merely needs to iteratively provide trajectories that slightly improve over the trajectory currently proposed by the system. We argue that this co-active preference feedback can be more easily elicited from the user than demonstrations of optimal trajectories, which are often challenging and non-intuitive to provide on high degrees of freedom manipulators. Nevertheless, theoretical regret bounds of our algorithm match the asymptotic rates of optimal trajectory algorithms. We demonstrate the generalizability of our algorithm on a variety of grocery checkout tasks, for whom, the preferences were not only influenced by the object being manipulated but also by the surrounding environment.
An earlier version of this work was presented at the ICML workshop on Robot Learning, June 2013. [PDF]
-
Anticipating Human Activities using Object Affordances for Reactive Robotic Response, Hema S Koppula, Ashutosh Saxena. In Robotics: Science and Systems (RSS), 2013. (best student paper award, best paper runner-up) [PDF, project page]
@inproceedings{koppula2013_anticipatingactivities,
title={Anticipating Human Activities using Object Affordances for Reactive Robotic Response},
author={Hema Koppula and Ashutosh Saxena},
year={2013},
booktitle={RSS}
}Abstract: Anticipating which activities will a human do next (and how) can enable an assistive robot to plan ahead for reactive responses in human environments. The challenge, however, is two-fold: We need to capture the rich context for modeling the activities and object affordances, and we need to anticipate the distribution over a large space of future human activities. In this work, we represent each possible future using an anticipatory temporal conditional random field (ATCRF) that models the rich spatial-temporal relations through object affordances. We then consider each ATCRF as a particle and represent the distribution over the potential futures using a set of particles.
-
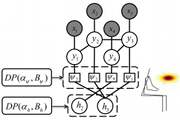
Infinite Latent Conditional Random Fields for Modeling Environments through Humans, Yun Jiang, Ashutosh Saxena. In Robotics: Science and Systems (RSS), 2013. [PDF, project page]
@inproceedings{jiang_2013_ilcrf_modelingenvironment_humans,
title={Infinite Latent Conditional Random Fields for Modeling Environments through Humans},
author={Yun Jiang and Ashutosh Saxena},
year={2013},
booktitle={RSS}
}Abstract: In this paper, we model environments not only through objects, but also through latent human poses and human-object interactions. However, the number of potential human poses is large and unknown, and the human-object interactions vary not only in type but also in which human pose relates to each object. In order to handle such properties, we present Infinite Latent Conditional Random Fields (ILCRFs) that model a scene as a mixture of CRFs generated from Dirichlet processes. Each CRF represents one possible explanation of the scene. In addition to visible object nodes and edges, it generatively models the distribution of different CRF structures over the latent human nodes and corresponding edges.
(Full journal version, under submission: Modeling 3D Environments through Hidden Human Context, 2014.)
-
Deep Learning for Detecting Robotic Grasps, Ian Lenz, Honglak Lee, Ashutosh Saxena. In Robotics: Science and Systems (RSS), 2013. [PDF, arXiv, more]
@inproceedings{lenz2013_deeplearning_roboticgrasp,
title={Deep Learning for Detecting Robotic Grasps},
author={Ian Lenz and Honglak Lee and Ashutosh Saxena},
year={2013},
booktitle={RSS}
}Abstract: We consider the problem of detecting robotic grasps in an RGB-D view of a scene containing objects. In this work, we apply a deep learning approach to solve this problem, which avoids time-consuming hand-design of features. One challenge is that we need to handle multimodal inputs well, for which we present a method to apply structured regularization on the weights based on multimodal group regularization. We demonstrate that our method outperforms the previous state-of-the-art methods in robotic grasp detection, and can be used to successfully execute grasps on a Baxter robot.
(An earlier version was presented in International Conference on Learning Representations (ICLR), 2013.)
-
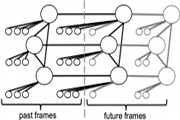
Learning Spatio-Temporal Structure from RGB-D Videos for Human Activity Detection and Anticipation, Hema S. Koppula, Ashutosh Saxena. In International Conference on Machine Learning (ICML), 2013. [PDF, project page]
@inproceedings{koppula-icml2013-learninggraphs-activities,
title={Learning Spatio-Temporal Structure from RGB-D Videos for Human Activity Detection and Anticipation},
author={Hema S. Koppula and Ashutosh Saxena},
year={2013},
booktitle={ICML}
}Abstract: We consider the problem of detecting past activities as well as anticipating which activity will happen in the future and how. We start by modeling the rich spatio-temporal relations between human poses and objects (called affordances) using a conditional random field (CRF). However, because of the ambiguity in the temporal segmentation of the sub-activities that constitute an activity, in the past as well as in the future, multiple graph structures are possible. In this paper, we reason about these alternate possibilities by reasoning over multiple possible graph structures. We obtain them by approximating the graph with only additive features, which lends to efficient dynamic programming. Starting with this proposal graph structure, we then design moves to obtain several other likely graph structures. We then show that our approach improves the state-of-the-art significantly for detecting past activities as well as for anticipating future activities.
-
Hallucinated Humans as the Hidden Context for Labeling 3D Scenes, Yun Jiang, Hema S Koppula, Ashutosh Saxena. In Computer Vision and Pattern Recognition (CVPR), 2013 (oral). [PDF, project page]
@inproceedings{jiang-hallucinatinghumans-labeling3dscenes-cvpr2013,
title={Hallucinated Humans as the Hidden Context for Labeling 3D Scenes},
author={Yun Jiang and Hema Koppula and Ashutosh Saxena},
year={2013},
booktitle={CVPR}
}Abstract: For scene understanding, one popular approach has been to model the object-object relationships. In this paper, we hypothesize that such relationships are only an artifact of certain hidden factors, such as humans. For example, the objects, monitor and keyboard, are strongly spatially correlated only because a human types on the keyboard while watching the monitor. Our goal is to learn this hidden human context (i.e., the human-object relationships), and also use it as a cue for labeling the scenes. We present Infinite Factored Topic Model (IFTM), where we consider a scene as being generated from two types of topics: human configurations and human-object relationships. This enables our algorithm to hallucinate the possible configurations of the humans in the scene parsimoniously.
(Full journal version, under submission: Modeling 3D Environments through Hidden Human Context, 2014.)
-
3D-Based Reasoning with Blocks, Support, and Stability. Zhaoyin Jia, Andy Gallagher, Ashutosh Saxena, Tsuhan Chen. In Computer Vision and Pattern Recognition (CVPR), 2013 (oral). [PDF]
@inproceedings{jia-3d-stability,
title={3D-Based Reasoning with Blocks, Support, and Stability},
author={Zhaoyin Jia and Andy Gallagher and Ashutosh Saxena and Tsuhan Chen},
year={2013},
booktitle={CVPR}
}Abstract: 3D volumetric reasoning is important for truly understanding a scene. We propose a new approach for parsing RGB-D images using 3D block units for volumetric reasoning. We produce a 3D representation of the scene based on jointly optimizing over segmentations, block fitting, supporting relations, and object stability. Our algorithm incorporates the intuition that a good 3D representation of the scene is the one that fits the data well, and is a stable, self-supporting (i.e., one that does not topple) arrangement of objects. We experiment on several datasets including controlled and real indoor scenarios. Results show that our stability-reasoning framework improves RGB-D segmentation and scene volumetric representation.
-

Tangled: Learning to Untangle Ropes with RGB-D Perception, Wen H Lui, Ashutosh Saxena. In International Conference on Intelligent Robots and Systems (IROS), 2013. [PDF]
@inproceedings{hao2013_unentanglingropes,
title={Tangled: Learning to Untangle Ropes with RGB-D Perception},
author={Wen H Lui and Ashutosh Saxena},
year={2013},
booktitle={IROS}
}Abstract: In this paper, we address the problem of manipulating deformable objects such as ropes. Starting with an RGB-D view of a tangled rope, our goal is to infer its knot structure and then choose appropriate manipulation actions that result in the rope getting untangled. We design appropriate features and present an inference algorithm based on particle filters to infer the rope's structure. Our learning algorithm is based on max-margin learning. We then choose an appropriate manipulation action based on the current knot structure and other properties such as slack in the rope. We then repeatedly perform perception and manipulation until the rope is untangled. We evaluate our algorithm extensively on a dataset having five different types of ropes and 10 different types of knots. We then perform robotic experiments, in which our bimanual manipulator (PR2) untangles ropes successfully 76.9% of the time.
-

Beyond geometric path planning: Learning context-driven trajectory preferences via sub-optimal feedback. Ashesh Jain, Shikhar Sharma, Ashutosh Saxena. In International Symposium of Robotics Research (ISRR), 2013. [PDF, project+video]
@inproceedings{jain_contextdrivenpathplanning_2013,
title={Beyond geometric path planning: Learning context-driven trajectory preferences via sub-optimal feedback},
author={Ashesh Jain and Shikhar Sharma and Ashutosh Saxena},
year={2013},
booktitle={ISRR}
}Abstract: We consider the problem of learning preferences over trajectories for mobile manipulators such as personal robots and assembly line robots. The preferences we learn are more intricate than those arising from simple geometric constraints on robot's trajectory, such as distance of the robot from human etc. Our preferences are rather governed by the surrounding context of various objects and human interactions in the environment. Such preferences makes the problem challenging because the criterion of defining a good trajectory now varies with the task, with the environment and across the users. Furthermore, demonstrating optimal trajectories (e.g., learning from expert's demonstrations) is often challenging and non-intuitive on high degrees of freedom manipulators. In this work, we propose an approach that requires a non-expert user to only incrementally improve the trajectory currently proposed by the robot. We implement our algorithm on two high degree-of-freedom robots, PR2 and Baxter, and present three intuitive mechanisms for providing such incremental feedback. In our experimental evaluation we consider two context rich settings - household chores and grocery store checkout - and show that users are able to train the robot with just a few feedbacks (taking only a few minutes). Despite receiving sub-optimal feedback from non-expert users, our algorithm enjoys theoretical bounds on regret that match the asymptotic rates of optimal trajectory algorithms.
-
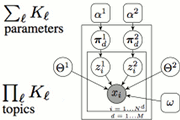
Discovering Different Types of Topics: Factored Topics Models, Yun Jiang, Ashutosh Saxena. In IJCAI, 2013. [PDF]
@inproceedings{jiang2013factoredtopicmodel,
title={Discovering Different Types of Topics: Factored Topics Models},
author={Yun Jiang and Ashutosh Saxena},
year={2013},
journal={IJCAI}
}Abstract: In traditional topic models such as LDA, a word is generated by choosing a topic from a collection. However, existing topic models do not identify different types of topics in a document, such as topics that represent the content and topics that represent the sentiment. In this paper, our goal is to discover such different types of topics, if they exist. We represent our model as several parallel topic models (called topic factors), where each word is generated from topics from these factors jointly. Since the latent membership of the word is now a vector, the learning algorithms become challenging. We show that using a variational approximation still allows us to keep the algorithm tractable. Our experiments over several datasets show that our approach consistently outperforms many classic topic models while also discovering fewer, more meaningful, topics.
-
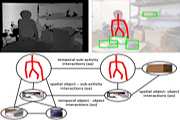
Learning Human Activities and Object Affordances from RGB-D Videos, Hema S Koppula, Rudhir Gupta, Ashutosh Saxena. International Journal of Robotics Research (IJRR), 32(8):951-970, July 2013. [PDF, CAD-120 dataset/code and more, ArXiv-2012]
@article{koppula2013detectingactivitiesrgbd,
title={Learning Human Activities and Object Affordances from RGB-D Videos},
author={Hema Koppula and Rudhir Gupta and Ashutosh Saxena},
year={2013},
volume={32},
number={8},
pages={951-970},
journal={IJRR}
}Abstract: Understanding human activities and object affordances are two very important skills, especially for personal robots which operate in human environments. In this work, we consider the problem of extracting a descriptive labeling of the sequence of sub-activities being performed by a human, and more importantly, of their interactions with the objects in the form of associated affordances. Given a RGB-D video, we jointly model the human activities and object affordances as a Markov random field where the nodes represent objects and sub-activities, and the edges represent the relationships between object affordances, their relations with sub-activities, and their evolution over time. We formulate the learning problem using a structural support vector machine (SSVM) approach, where labelings over various alternate temporal segmentations are considered as latent variables. We tested our method on a challenging dataset comprising 120 activity videos collected from 4 subjects, and obtained an accuracy of 79.4% for affordance, 63.4% for sub-activity and 75.0% for high-level activity labeling. We then demonstrate the use of such descriptive labeling in performing assistive tasks by a PR2 robot.
-

Learning Object Arrangements in 3D Scenes using Human Context, Yun Jiang, Marcus Lim, Ashutosh Saxena. In International Conference of Machine Learning (ICML), 2012. [PDF, project page]
(Related publication: Hallucinating Humans for Learning Robotic Placement of Objects, Yun Jiang, Ashutosh Saxena. In ISER, 2012.)
(Full journal version, under submission: Modeling 3D Environments through Hidden Human Context, 2014.)
@inproceedings{jiang2012humancontext,
title={Learning Object Arrangements in 3D Scenes using Human Context},
author={Yun Jiang and Marcus Lim and Ashutosh Saxena},
year={2012},
booktitle={ICML}
}Abstract: We consider the problem of learning object arrangements in a 3D scene. The key idea here is to learn how objects relate to human poses based on their affordances, ease of use and reachability. In contrast to modeling object-object relationships, modeling human-object relationships scales linearly in the number of objects. We design appropriate density functions based on 3D spatial features to capture this. We learn the distribution of human poses in a scene using a variant of the Dirichlet process mixture model that allows sharing of the density function parameters across the same object types. Then we can reason about arrangements of the objects in the room based on these meaningful human poses.
-

Learning to Place New Objects in a Scene, Yun Jiang, Marcus Lim, Changxi Zheng, Ashutosh Saxena. International Journal of Robotics Research (IJRR), 31(9):1021-1043, 2012. [PDF, ijrr-pdf, project page]
@article{jiang2012placingobjects,
title={Learning to Place New Objects in a Scene},
author={Yun Jiang and Marcus Lim and Changxi Zheng and Ashutosh Saxena},
year={2012},
volume={31},
number={9},
journal={IJRR}
}Abstract: Placing is a necessary skill for a personal robot to have in order to perform tasks such as arranging objects in a disorganized room. The object placements should not only be stable but also be in their semantically preferred placing areas and orientations. This is challenging because an environment can have a large variety of objects and placing areas that may not have been seen by the robot before. In this paper, we propose a learning approach for placing multiple objects in different placing areas in a scene. Given point-clouds of the objects and the scene, we design appropriate features and use a graphical model to encode various properties, such as the stacking of objects, stability, object-area relationship and common placing constraints. The inference in our model is an integer linear program, which we solve efficiently via an LP relaxation. We extensively evaluate our approach on 98 objects from 16 categories being placed into 40 areas. Our robotic experiments show a success rate of 98% in placing known objects and 82% in placing new objects stably. We use our method on our robots for performing tasks such as loading several dish-racks, a bookshelf and a fridge with multiple items.
-

Contextually Guided Semantic Labeling and Search for 3D Point Clouds, Abhishek Anand*, Hema Koppula*, Thorsten Joachims, Ashutosh Saxena. International Journal of Robotics Research (IJRR), 2012. [PDF, arXivPDF, project page]
(Original version in NIPS 2011.)
@article{koppula_semanticlabeling3d,
title={Contextually Guided Semantic Labeling and Search for 3D Point Clouds},
author={Abhishek Anand and Hema Koppula and Thorsten Joachims and Ashutosh Saxena},
year={2012},
booktitle={IJRR}
}Abstract: RGB-D cameras, which give an RGB image together with depths, are becoming increasingly popular for robotic perception. In this paper, we address the task of detecting commonly found objects in the 3D point cloud of indoor scenes obtained from such cameras. Our method uses a graphical model that captures various features and contextual relations, including the local visual appearance and shape cues, object co-occurence relationships and geometric relationships. With a large number of object classes and relations, the model's parsimony becomes important and we address that by using multiple types of edge potentials. We train the model using a maximum-margin learning approach. In our experiments over a total of 52 3D scenes of homes and offices (composed from about 550 views), we get a performance of 84.06% and 73.38% in labeling office and home scenes respectively for 17 object classes each. We also present a method for a robot to search for an object using the learned model and the contextual information available from the current labelings of the scene. We applied this algorithm successfully on a mobile robot for the task of finding 12 object classes in 10 different offices and achieved a precision of 97.56% with 78.43% recall.
-

Learning the Right Model: Efficient Max-Margin Learning in Laplacian CRFs, Dhruv Batra, Ashutosh Saxena. In Computer Vision and Pattern Recognition (CVPR), 2012. [PDF, supplementary material]
(Applied to Make3D: learning depths from a single still image.)
@inproceedings{laplaciancrfs_cvpr2012,
title={Learning the Right Model: Efficient Max-Margin Learning in Laplacian CRFs},
author={Dhruv Batra and Ashutosh Saxena},
year={2012},
booktitle={CVPR}
}Abstract: An important modeling decision made while designing Conditional Random Fields (CRFs) is the choice of the potential functions over the cliques of variables. Laplacian potentials are useful because they are robust potentials and match image statistics better than Gaussians. Moreover, energies with Laplacian terms remain convex, which simplifies inference. This makes Laplacian potentials an ideal modeling choice for some applications. In this paper, we study max-margin parameter learning in CRFs with Laplacian potentials (LCRFs). We first show that structured hinge-loss is non-convex for LCRFs and thus techniques used by previous works are not applicable. We then present the first approximate max-margin algorithm for LCRFs. Finally, we make our learning algorithm scalable in the number of training images by using dual-decomposition techniques. Our experiments on singleimage depth estimation show that even with simple features, our approach achieves comparable to state-of-art results.
-

Hallucinating Humans for Learning Robotic Placement of Objects, Yun Jiang, Ashutosh Saxena. In 13th International Symposium on Experimental Robotics (ISER), 2012. [PDF, more]
(Full journal version, under submission: Modeling 3D Environments through Hidden Human Context, 2014.)
@inproceedings{jiang2012placingobjects_context,
title={Hallucinating Humans for Learning Robotic Placement of Objects},
author={Yun Jiang and Ashutosh Saxena},
year={2012},
booktitle={ISER}
}Abstract: While a significant body of work has been done on grasping objects, there is little prior work on placing and arranging objects in the environment. In this work, we consider placing multiple objects in complex placing areas, where neither the object nor the placing area may have been seen by the robot before. Specifically, the placements should not only be stable, but should also follow human usage preferences. We present learning and inference algorithms that consider these aspects in placing. In detail, given a set of 3D scenes containing objects, our method, based on Dirichlet process mixture models, samples human poses in each scene and learns how objects relate to those human poses. Then given a new room, our algorithm is able to select meaningful human poses and use them to determine where to place new objects. We evaluate our approach on a variety of scenes in simulation, as well as on robotic experiments.
-

Learning to Place New Objects, Yun Jiang, Changxi Zheng, Marcus Lim, Ashutosh Saxena. In International Conference on Robotics and Automation (ICRA), 2012. First appeared in RSS workshop on mobile manipulation, June 2011. [PDF, more]
@inproceedings{jiang2011learningtoplace,
title={Learning to place new objects},
author={Jiang, Y. and Zheng, C. and Lim, M. and Saxena, A.},
booktitle={International Conference on Robotics and Automation (ICRA)},
year={2012}
}Abstract: The ability to place objects in an environment is an important skill for a personal robot. An object should not only be placed stably, but should also be placed in its preferred location/orientation. For instance, it is preferred that a plate be inserted vertically into the slot of a dish-rack as compared to being placed horizontally in it. Unstructured environments such as homes have a large variety of object types as well as of placing areas. Therefore our algorithms should be able to handle placing new object types and new placing areas. These reasons make placing a challenging manipulation task. In this work, we propose using a supervised learning approach for finding good placements given point-clouds of the object and the placing area. Our method combines the features that capture support, stability and preferred configurations, and uses a shared sparsity structure in its the parameters. Even when neither the object nor the placing area is seen previously in the training set, our learning algorithm predicts good placements.
-
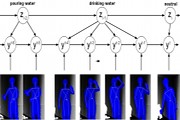
Unstructured Human Activity Detection from RGBD Images, Jaeyong Sung, Colin Ponce, Bart Selman, Ashutosh Saxena. In International Conference on Robotics and Automation (ICRA), 2012. [PDF, project page]
@inproceedings{sung_rgbdactivity_2012,
title={Unstructured Human Activity Detection from RGBD Images},
author={Jaeyong Sung and Colin Ponce and Bart Selman and Ashutosh Saxena},
booktitle={International Conference on Robotics and Automation (ICRA)},
year={2012}
}Abstract: Being able to detect and recognize human activities is essential for several applications, including personal assistive robotics. In this paper, we perform detection and recognition of unstructured human activity in unstructured environments. We use a RGBD sensor (Microsoft Kinect) as the input sensor, and compute a set of features based on human pose and motion, as well as based on image and point-cloud information. Our algorithm is based on a hierarchical maximum entropy Markov model (MEMM), which considers a person’s activity as composed of a set of sub-activities. We infer the two-layered graph structure using a dynamic programming approach. We test our algorithm on detecting and recognizing twelve different activities performed by four people in different environments, such as a kitchen, a living room, an office, etc., and achieve good performance even when the person was not seen before in the training set.
-

Low-Power Parallel Algorithms for Single Image based Obstacle Avoidance in Aerial Robots, Ian Lenz, Mevlana Gemici, Ashutosh Saxena. In International Conference on Intelligent Robots and Systems (IROS), 2012. [PDF, more]
@inproceedings{lenz_lowpoweraerial_2012,
title={Low-Power Parallel Algorithms for Single Image based Obstacle Avoidance in Aerial Robots},
author={Ian Lenz and Mevlana Gemici and Ashutosh Saxena},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
year={2012}
}Abstract: For an aerial robot, perceiving and avoiding obstacles are necessary skills to function autonomously in a cluttered unknown environment. In this work, we use a single image captured from the onboard camera as input, produce obstacle classifications, and use them to select an evasive maneuver. We present a Markov Random Field based approach that models the obstacles as a function of visual features and non-local dependencies in neighboring regions of the image. We perform efficient inference using new low-power parallel neuromorphic hardware, where belief propagation updates are done using leaky integrate and fire neurons in parallel, while consuming less than 1 W of power. In outdoor robotic experiments, our algorithm was able to consistently produce clean, accurate obstacle maps which allowed our robot to avoid a wide variety of obstacles, including trees, poles and fences.
-

Learning Hardware Agnostic Grasps for a Universal Jamming Gripper, Yun Jiang, John Amend, Hod Lipson, Ashutosh Saxena. In International Conference on Robotics and Automation (ICRA), 2012. [PDF, more]
@inproceedings{jiang_jamming_2012,
title={Learning Hardware Agnostic Grasps for a Universal Jamming Gripper},
author={Yun Jiang and John Amend and Hod Lipson and Ashutosh Saxena},
booktitle={International Conference on Robotics and Automation (ICRA)},
year={2012}
}Abstract: Grasping has been studied from various perspectives including planning, control, and learning. In this paper, we take a learning approach to predict successful grasps for a universal jamming gripper. A jamming gripper is comprised of a flexible membrane filled with granular material, and it can quickly harden or soften to grip objects of varying shape by modulating the air pressure within the membrane. Although this gripper is easy to control, developing a physical model of its gripping mechanism is difficult because it undergoes significant deformation during use. Thus, many grasping approaches based on physical models (such as based on form- and force-closure) would be challenging to apply to a jamming gripper. Here we instead use a supervised learning algorithm and design both visual and shape features for capturing the properties of good grasps. We show that given target object data from an RGBD sensor, our algorithm can predict successful grasps for the jamming gripper without requiring a physical model. It can therefore be applied to both a parallel plate gripper and a jamming gripper without modification. We demonstrate that our learning algorithm enables both grippers to pick up a wide variety of objects, including objects from outside the training set. Through robotic experiments we are then able to define the type of objects each gripper is best suited for handling.
-

Co-evolutionary Predictors for Kinematic Pose Inference from RGBD Images, Daniel Ly, Ashutosh Saxena, Hod Lipson. In Genetic and Evolutionary Computation Conference (GECCO), 2012. [PDF]
@inproceedings{ly_pose_2012,
title={Co-evolutionary Predictors for Kinematic Pose Inference from RGBD Images},
author={Daniel Ly and Ashutosh Saxena and Hod Lipson},
booktitle={Genetic and Evolutionary Computation Conference (GECCO)},
year={2012}
}Abstract: Markerless pose inference of arbitrary subjects is a primary problem for a variety of applications, including robot vision and teaching by demonstration. Unsupervised kinematic pose inference is an ideal method for these applications as it provides a robust, training-free approach with minimal reliance on prior information. However, these methods have been considered intractable for complex models. This paper presents a general framework for inferring poses from a single depth image given an arbitrary kinematic structure without prior training. A co-evolutionary algorithm, consisting of pose and predictor populations, is applied to overcome the traditional limitations in kinematic pose inference. Evaluated on test sets of 256 synthetic and 52 real images, our algorithm shows consistent pose inference for 34 and 78 degree of freedom models with point clouds containing over 40,000 points, even in cases of significant self-occlusion. Compared to various baselines, the co-evolutionary algorithm provides at least a 3.5-fold increase in pose accuracy and a two-fold reduction in computational effort for articulated models.
-

Semantic Labeling of 3D Point Clouds for Indoor Scenes, Hema Koppula, Abhishek Anand, Thorsten Joachims, Ashutosh Saxena. In Neural Information Processing Systems (NIPS), 2011. [PDF, project page, Code]
@inproceedings{koppula2011semantic,
title={Semantic Labeling of 3D Point Clouds for Indoor Scenes},
author={Koppula, H.S. and Anand, A. and Joachims, T. and Saxena, A.},
year={2011},
booktitle={NIPS}
}Abstract: Inexpensive RGB-D cameras that give an RGB image together with depth data have become widely available. In this paper, we use this data to build 3D point clouds of full indoor scenes such as an office and address the task of semantic labeling of these 3D point clouds. We propose a graphical model that captures various features and contextual relations, including the local visual appearance and shape cues, object co-occurence relationships and geometric relationships. With a large number of object classes and relations, the model's parsimony becomes important and we address that by using multiple types of edge potentials. The model admits efficient approximate inference, and we train it using a maximum-margin learning approach. In our experiments over a total of 52 3D scenes of homes and offices (composed from about 550 views, having 2495 segments labeled with 27 object classes), we get a performance of 84.06% in labeling 17 object classes for offices, and 73.38% in labeling 17 object classes for home scenes. Finally, we applied these algorithms successfully on a mobile robot for the task of finding objects in large cluttered rooms.
-
θ-MRF: Capturing Spatial and Semantic Structure in the Parameters for Scene Understanding, Congcong Li, Ashutosh Saxena, Tsuhan Chen. In Neural Information Processing Systems (NIPS), 2011. [PDF]
@inproceedings{li2011_thetamrf,
title={$\theta$-MRF: Capturing Spatial and Semantic Structure in the Parameters for Scene Understanding},
author={Li, C. and Saxena, A. and Chen, T.},
year={2011},
booktitle={NIPS} }Abstract: For most scene understanding tasks (such as object detection or depth estimation), the classifiers need to consider contextual information in addition to the local features. We can capture such contextual information by taking as input the features/attributes from all the regions in the image. However, this contextual dependence also varies with the spatial location of the region of interest, and we therefore need a different set of parameters for each spatial location. This results in a very large number of parameters. In this work, we model the independence properties between the parameters for each location and for each task, by defining a Markov Random Field (MRF) over the parameters. In particular, two sets of parameters are encouraged to have similar values if they are spatially close or semantically close. Our method is, in principle, complementary to other ways of capturing context such as the ones that use a graphical model over the labels instead. In extensive evaluation over two different settings, of multi-class object detection and of multiple scene understanding tasks (scene categorization, depth estimation, geometric labeling), our method beats the state-of-the-art methods in all the four tasks.
-
Towards Holistic Scene Understanding: Feedback Enabled Cascaded Classification Models, Congcong Li, Adarsh Kowdle, Ashutosh Saxena, Tsuhan Chen. IEEE Trans Pattern Analysis and Machine Intelligence (PAMI), 34(7):1394-1408, July 2012. (Online first: Oct 2011.) [PDF, IEEE link, project page]
(Original paper appeared in Neural Information Processing Systems (NIPS), 2010. [PDF])
@article{li2011feccm,
title={Towards holistic scene understanding: Feedback enabled cascaded classification models},
author={Li, C. and Kowdle, A. and Saxena, A. and Chen, T.},
journal={Pattern Analysis and Machine Intelligence, IEEE Transactions on},
volume={34},
number={7},
pages={1394-1408},
year={2012}
}Abstract: Scene understanding includes many related sub-tasks, such as scene categorization, depth estimation, object detection, etc. Each of these sub-tasks is often notoriously hard, and state-of-the-art classifiers already exist for many of them. These classifiers operate on the same raw image and provide correlated outputs. It is desirable to have an algorithm that can capture such correlation without requiring any changes to the inner workings of any classifier. We propose Feedback Enabled Cascaded Classification Models (FE-CCM), that jointly optimizes all the sub-tasks, while requiring only a 'black-box' interface to the original classifier for each sub-task. We use a two-layer cascade of classifiers, which are repeated instantiations of the original ones, with the output of the first layer fed into the second layer as input. Our training method involves a feedback step that allows later classifiers to provide earlier classifiers information about which error modes to focus on. We show that our method significantly improves performance in all the sub-tasks in the domain of scene understanding, where we consider depth estimation, scene categorization, event categorization, object detection, geometric labeling and saliency detection. Our method also improves performance in two robotic applications: an object-grasping robot and an object-finding robot.
-

Efficient Grasping from RGBD images: Learning using a new Rectangle Representation, Yun Jiang, Stephen Moseson, Ashutosh Saxena. In International Conference on Robotics and Automation (ICRA), 2011. [PDF]
@inproceedings{jiang2011_graspingrgbd,
title={Efficient Grasping from RGBD images: Learning using a new Rectangle Representation},
author={Yun Jiang and Stephen Moseson and Ashutosh Saxena},
year={2011},
booktitle={ICRA}
}Abstract: Given an image and an aligned depth map of an object, our goal is to estimate the full 7-dimensional gripper configuration---its 3D location, 3D orientation and the gripper opening width. Recently, learning algorithms have been successfully applied to grasp novel objects---ones not seen by the robot before. While these approaches use low-dimensional representations such as a 'grasping point' or a 'pair of points' that are perhaps easier to learn, they only partly represent the gripper configuration and hence are sub-optimal. We propose to learn a new 'grasping rectangle' representation: an oriented rectangle in the image plane. It takes into account the location, the orientation as well as the gripper opening width. However, inference with such a representation is computationally expensive. In this work, we present a two step process in which the first step prunes the search space efficiently using certain features that are fast to compute. For the remaining few cases, the second step uses advanced features to accurately select a good grasp. In our extensive experiments, we show that our robot successfully uses our algorithm to pick up a variety of novel objects.
-

Autonomous MAV Flight in Indoor Environments using Single Image Perspective Cues, Cooper Bills, Joyce Chen, Ashutosh Saxena. In International Conference on Robotics and Automation (ICRA), 2011. [PDF, More]
@inproceedings{bills2011_indoorsingleimage,
title={Autonomous MAV Flight in Indoor Environments using Single Image Perspective Cues},
author={Cooper Bills and Joyce Chen and Ashutosh Saxena},
year={2011},
booktitle={ICRA}
}Abstract: We consider the problem of autonomously flying Miniature Aerial Vehicles (MAVs) in indoor environments such as home and office buildings. The primary long range sensor in these MAVs is a miniature camera. While previous approaches first try to build a 3D model in order to do planning and control, our method neither attempts to build nor requires a 3D model. Instead, our method first classifies the type of indoor environment the MAV is in, and then uses vision algorithms based on perspective cues to estimate the desired direction to fly. We test our method on two MAV platforms: a co-axial miniature helicopter and a toy quadrotor. Our experiments show that our vision algorithms are quite reliable, and they enable our MAVs to fly in a variety of corridors and staircases.
-

Robotic Object Detection: Learning to Improve the Classifiers using Sparse Graphs for Path Planning. Zhaoyin Jia, Ashutosh Saxena, Tsuhan Chen. In 22nd International Joint Conference on Artificial Intelligence (IJCAI), 2011. [PDF]
@inproceedings{jia2011_roboticobjectdetection,
title={Robotic Object Detection: Learning to Improve the Classifiers using Sparse Graphs for Path Planning},
author={Zhaoyin Jia and Ashutosh Saxena and Tsuhan Chen},
year={2011},
booktitle={IJCAI}
}Abstract: Object detection is a basic skill for a robot to perform tasks in human environments. In order to build a good object classifier, a large training set of labeled images is required; this is typically collected and labeled (often painstakingly) by a human. This method is not scalable and therefore limits the robot's detection performance. We propose an algorithm for a robot to collect more data in the environment during its training phase so that in the future it could detect objects more reliably. The first step is to plan a path for collecting additional training images, which is hard because a previously visited location affects the decision for the future locations. One key component of our work is path planning by building a sparse graph that captures these dependencies. The other key component is our learning algorithm that weighs the errors made in robot's data collection process while updating the classifier. In our experiments, we show that our algorithms enable the robot to improve its object classifiers significantly.
-

MDPs with Unawareness, Joseph Y. Halpern, Nan Rong, Ashutosh Saxena. In Uncertainty in Artificial Intelligence (UAI 2010), 2010. [PDF, Extended version]
@inproceedings{halpern2010mdps,
title={MDPs with Unawareness},
author={Halpern, J.Y. and Rong, N. and Saxena, A.},
booktitle={UAI},
year={2010}
}Abstract: Markov decision processes (MDPs) are widely used for modeling decision-making problems in robotics, automated control, and economics. Traditional MDPs assume that the decision maker (DM) knows all states and actions. However, this may not be true in many situations of interest. We define a new framework, MDPs with unawareness (MDPUs) to deal with the possibilities that a DM may not be aware of all possible actions. We provide a complete characterization of when a DM can learn to play near-optimally in an MDPU, and give an algorithm that learns to play near-optimally when it is possible to do so, as efficiently as possible. In particular, we characterize when a near-optimal solution can be found in polynomial time.
-
Towards Holistic Scene Understanding: Feedback Enabled Cascaded Classification Models, Congcong Li, Adarsh Kowdle, Ashutosh Saxena, Tsuhan Chen. In Neural Information Processing Systems (NIPS), 2010. [PDF, More]
Also see: A Generic Model to Compose Vision Modules for Holistic Scene Understanding, Adarsh Kowdle, Congcong Li, Ashutosh Saxena and Tsuhan Chen. In European Conference on Computer Vision Workshop on Parts and Attributes (ECCV '10), 2010. [PDF, slides, More] FeCCM for Scene Understanding: Helping the Robot to Learn Multiple Tasks, Congcong Li, TP Wong, Norris Xu, Ashutosh Saxena. Video contribution in ICRA, 2011. [PDF, mp4, youtube, More]
@inproceedings{li2010feccm,
title={Towards holistic scene understanding: Feedback enabled cascaded classification models},
author={Li, C. and Kowdle, A. and Saxena, A. and Chen, T.},
booktitle={Neural Information Processing Systems (NIPS)},
year={2010}
}Abstract: In many machine learning domains (such as scene understanding), several related sub-tasks (such as scene categorization, depth estimation, object detection) operate on the same raw data and provide correlated outputs. Each of these tasks is often notoriously hard, and state-of-the-art classifiers already exist for many sub-tasks. It is desirable to have an algorithm that can capture such correlation without requiring to make any changes to the inner workings of any classifier.
We propose Feedback Enabled Cascaded Classification Models (FE-CCM), that maximizes the joint likelihood of the sub-tasks, while requiring only a 'black-box' interface to the original classifier for each sub-task. We use a two-layer cascade of classifiers, which are repeated instantiations of the original ones, with the output of the first layer fed into the second layer as input. Our training method involves a feedback step that allows later classifiers to provide earlier classifiers information about what error modes to focus on. We show that our method significantly improves performance in all the sub-tasks in two different domains: (i) scene understanding, where we consider depth estimation, scene categorization, event categorization, object detection, geometric labeling and saliency detection, and (ii) robotic grasping, where we consider grasp point detection and object classification.
-

Learning to Open New Doors, Ellen Klingbeil, Ashutosh Saxena, Andrew Y. Ng. In Int'l conf on Intelligent Robots and Systems (IROS), 2010. [PDF]
First published in Robotics Science and Systems (RSS) workshop on Robot Manipulation, 2008. [PDF]
@inproceedings{klingbeilsaxena-door-iros2010,
title={Learning to Open New Doors},
author={Klingbeil, E. and Saxena, A. and Ng, A.Y.},
booktitle={IROS},
year={2010}
}Abstract: We consider the problem of enabling a robot to autonomously open doors, including novel ones that the robot has not previously seen. Given the large variation in the appearances and locations of doors and door handles, this is a challenging perception and control problem; but this capability will significantly enlarge the range of environments that our robots can autonomously navigate through. In this paper, we focus on the case of doors with door handles. We propose an approach that, rather than trying to build a full 3d model of the door/door handle--which is challenging because of occlusion, specularity of many door handles, and the limited accuracy of our 3d sensors--instead uses computer vision to choose a manipulation strategy. Specifically, it uses an image of the door handle to identify a small number of "3d key locations," such as the axis of rotation of the door handle, and the location of the end-point of the door-handle. These key locations then completely define a trajectory for the robot end-effector (hand) that successfully turns the door handle and opens the door. Evaluated on a large set of doors that the robot had not previously seen, it successfully opened 31 out of 34 doors. We also show that this approach of using vision to identify a small number of key locations also generalizes to a range of other tasks, including turning a thermostat knob, pulling open a drawer, and pushing elevator buttons.
-

Autonomous Indoor Helicopter Flight using a Single Onboard Camera, Sai Prasanth Soundararaj, Arvind Sujeeth, Ashutosh Saxena. In International Conference on Intelligent RObots and Systems (IROS), 2009. [PDF]
@inproceedings{soundararajsaxena-door-iros2009,
title={Autonomous Indoor Helicopter Flight using a Single Onboard Camera},
author={Soundararaj, S.P. and Sujeeth, A. and Saxena, A.},
booktitle={IROS},
year={2009}
}Abstract: We consider the problem of autonomously flying a helicopter in indoor environments. Navigation in indoor settings poses two major challenges. First, real-time perception and response is crucial because of the high presence of obstacles. Second, the limited free space in such a setting places severe restrictions on the size of the aerial vehicle, resulting in a frugal payload budget.
We autonomously fly a miniature RC helicopter in small known environments using an on-board light-weight camera as the only sensor. We use an algorithm that combines data-driven image classification with optical flow techniques on the images captured by the camera to achieve real-time 3D localization and navigation. We perform successful autonomous test flights along trajectories in two different indoor settings. Our results demonstrate that our method is capable of autonomous flight even in narrow indoor spaces with sharp corners.
-

Monocular Depth Perception and Robotic Grasping of Novel Objects, Ashutosh Saxena. Ph.D. Thesis, Stanford University, June 2009. Thesis committee: Andrew Y Ng (chair), Sebastian Thrun, Stephen Boyd.[PDF]
@phdthesis{saxena2009monocular,
title={Monocular depth perception and robotic grasping of novel objects},
author={Saxena, A.},
year={2009},
school={Stanford University}
}Abstract: The ability to perceive the 3D shape of the environment is a basic ability for a robot. We present an algorithm to convert standard digital pictures into 3D models. This is a challenging problem, since an image is formed by a projection of the 3D scene onto two dimensions, thus losing the depth information. We take a supervised learning approach to this problem, and use a Markov Random Field (MRF) to model the scene depth as a function of the image features. We show that, even on unstructured scenes of a large variety of environments, our algorithm is frequently able to recover accurate 3D models. We then apply our methods to robotics applications: (a) obstacle avoidance for autonomously driving a small electric car, and (b) robot manipulation, where we develop vision-based learning algorithms for grasping novel objects. This enables our robot to perform tasks such as open new doors, clear up cluttered tables, and unload items from a dishwasher.
-

Cascaded Classification Models: Combining Models for Holistic Scene Understanding, Geremy Heitz, Stephen Gould, Ashutosh Saxena, Daphne Koller. In Neural Information Processing Systems (NIPS), 2008. (oral) [PDF, project page]
@inproceedings{heitz2008cascaded,
title={Cascaded classification models: Combining models for holistic scene understanding},
author={Heitz, G. and Gould, S. and Saxena, A. and Koller, D.},
booktitle={Neural Information Processing Systems},
year={2008}
}Abstract: One of the original goals of computer vision was to fully understand a natural scene. This requires solving several sub-problems simultaneously, including object detection, region labeling, and geometric reasoning. The last few decades have seen great progress in tackling each of these problems in isolation. Only recently have researchers returned to the difficult task of considering them jointly. In this work, we consider learning a set of related models in such that they both solve their own problem and help each other. We develop a framework called Cascaded Classification Models (CCM), where repeated instantiations of these classifiers are coupled by their input/output variables in a cascade that improves performance at each level. Our method requires only a limited "black box" interface with the models, allowing us to use very sophisticated, state-of-the-art classifiers without having to look under the hood. We demonstrate the effectiveness of our method on a large set of natural images by combining the subtasks of scene categorization, object detection, multiclass image segmentation, and 3d reconstruction.
-
Learning Sound Location from a Single Microphone, Ashutosh Saxena, Andrew Y Ng. In International Conference on Robotics and Automation (ICRA), 2009. (best student paper finalist) [PDF]
@inproceedings{saxena_sound_icra09,
title={Learning Sound Location from a Single Microphone},
author={Saxena, A. and Ng, A.Y.},
booktitle={ICRA},
year={2009}
}Abstract: We consider the problem of estimating the incident angle of a sound, using only a single microphone. The ability to perform monaural (single-ear) localization is important to many animals; indeed, monaural cues are also the primary method by which humans decide if a sound comes from the front or back, as well as estimate its elevation. Such monaural localization is made possible by the structure of the pinna (outer ear), which modifies sound in a way that is dependent on its incident angle. In this paper, we propose a machine learning approach to monaural localization, using only a single microphone and an "artificial pinna" (that distorts sound in a direction-dependent way). Our approach models the typical distribution of natural and artificial sounds, as well as the direction-dependent changes to sounds induced by the pinna. Our experimental results also show that the algorithm is able to fairly accurately localize a wide range of sounds, such as human speech, dog barking, waterfall, thunder, and so on. In contrast to microphone arrays, this approach also offers the potential of significantly more compact, as well as lower cost and power, devices for sounds localization.
-

Learning 3-D Object Orientation from Images, Ashutosh Saxena, Justin Driemeyer, Andrew Y Ng. In International Conference on Robotics and Automation (ICRA), 2009. [PDF]
First presented in NIPS workshop on Robotic Challenges for Machine Learning, 2007.
@inproceedings{saxena_3dorientation_icra09,
title={Learning 3-D Object Orientation from Images},
author={Saxena, A. and Driemeyer, J. and Ng, A.Y.},
booktitle={ICRA},
year={2009}
}Abstract: We propose a learning algorithm for estimating the 3-D orientation of objects. Orientation learning is a difficult problem because the space of orientations is non-Euclidean, and in some cases (such as quaternions) the representation is ambiguous, in that multiple representations exist for the same physical orientation. Learning is further complicated by the fact that most man-made objects exhibit symmetry, so that there are multiple "correct" orientations. In this paper, we propose a new representation for orientations--and a class of learning and inference algorithms using this representation--that allows us to learn orientations for symmetric or asymmetric objects as a function of a single image. We extensively evaluate our algorithm for learning orientations of objects from six categories.
-

i23 - Rapid Interactive 3D Reconstruction from a Single Image, Savil Srivastava, Ashutosh Saxena, Christian Theobalt, Sebastian Thrun, Andrew Y. Ng. In Vision, Modelling and Visualization (VMV), 2009. [PDF]
@inproceedings{i23_vmv09,
title={i23 - Rapid Interactive 3D Reconstruction from a Single Image},
author={Savil Srivastava and Ashutosh Saxena and Christian Theobalt and Sebastian Thrun and Andrew Y. Ng.},
booktitle={VMV},
year={2009}
}Abstract: We present i23, an algorithm to reconstruct a 3D model from a single image taken with a normal photo camera. It is based off an automatic machine learning approach that casts 3D reconstruction as a probabilistic inference problem using a Markov Random Field trained on ground truth data. Since it is difficult to learn the statistical relations for all possible images, the quality of the automatic reconstruction is sometimes unsatisfying. We therefore designed an intuitive interface for a user to sketch, in a few seconds, additional hints to the algorithm. We have developed a way to incorporate these constraints into the probabilistic reconstruction framework in order to obtain 3D reconstructions of much higher quality than previous fully-automatic methods. Our system also represents an exciting new computational photography tool, enabling new ways of rendering and editing photos.
-

Reactive Grasping using Optical Proximity Sensors, Kaijen Hsiao, Paul Nangeroni, Manfred Huber, Ashutosh Saxena, Andrew Y Ng. International Conference on Robotics and Automation (ICRA), 2009. [PDF, More]
@inproceedings{saxena_proximitysensor_icra09,
title={Reactive Grasping using Optical Proximity Sensors},
author={Hsiao, K. and Nangeroni, P. and Huber, M. and Saxena, A. and Ng, A.Y.},
booktitle={ICRA},
year={2009}
}Abstract: We propose a system for improving grasping using fingertip optical proximity sensors that allows us to perform online grasp adjustments to an initial grasp point without requiring premature object contact or regrasping strategies. We present novel optical proximity sensors that fit inside the fingertips of a Barrett Hand, and demonstrate their use alongside a probabilistic model for robustly combining sensor readings and a hierarchical reactive controller for improving grasps online. This system can be used to complement existing grasp planning algorithms, or be used in more interactive settings where a human indicates the location of objects. Finally, we perform a series of experiments using a Barrett hand equipped with our sensors to grasp a variety of common objects with mixed geometries and surface textures.
-

Make3D: Learning 3D Scene Structure from a Single Still Image, Ashutosh Saxena, Min Sun, Andrew Y. Ng. IEEE Transactions of Pattern Analysis and Machine Intelligence (PAMI), vol. 30, no. 5, pp 824-840, 2009. [PDF, Make3d project page, Google Tech Talk] (Original version received best paper award at ICCV 3dRR in 2007.)
@article{saxena2009make3d,
title={Make3d: Learning 3d scene structure from a single still image},
author={Saxena, A. and Sun, M. and Ng, A.Y.},
journal={Pattern Analysis and Machine Intelligence, IEEE Transactions on},
volume={31},
number={5},
pages={824--840},
year={2009},
publisher={IEEE}
}Abstract: We consider the problem of estimating detailed 3-d structure from a single still image of an unstructured environment. Our goal is to create 3-d models which are both quantitatively accurate as well as visually pleasing. For each small homogeneous patch in the image, we use a Markov Random Field (MRF) to infer a set of "plane parameters" that capture both the 3-d location and 3-d orientation of the patch. The MRF, trained via supervised learning, models both image depth cues as well as the relationships between different parts of the image. Other than assuming that the environment is made up of a number of small planes, our model makes no explicit assumptions about the structure of the scene; this enables the algorithm to capture much more detailed 3-d structure than does prior art, and also give a much richer experience in the 3-d flythroughs created using image-based rendering, even for scenes with significant non-vertical structure. Using this approach, we have created qualitatively correct 3-d models for 64.9% of 588 images downloaded from the internet. We have also extended our model to produce large scale 3d models from a few images.
-

Make3D: Depth Perception from a Single Still Image, Ashutosh Saxena, Min Sun, Andrew Y. Ng. In AAAI, 2008. (Nectar Track) [PDF]
@inproceedings{saxena_aaai09_depth,
title={Make3D: Depth Perception from a Single Still Image},
author={Ashutosh Saxena and Min Sun and Andrew Y. Ng.},
booktitle={AAAI},
year={2008}
}Abstract: Humans have an amazing ability to perceive depth from a single still image; however, it remains a challenging problem for current computer vision systems. In this paper, we will present algorithms for estimating depth from a single still image. There are numerous monocular cues--such as texture variations and gradients, defocus, color/haze, etc.--that can be used for depth perception. Taking a supervised learning approach to this problem, in which we begin by collecting a training set of single images and their corresponding groundtruth depths, we learn the mapping from image features to the depths. We then apply these ideas to create 3-d models that are visually-pleasing as well as quantitatively accurate from individual images. We also discuss applications of our depth perception algorithm in robotic navigation, in improving the performance of stereovision, and in creating large-scale 3-d models given only a small number of images.
-

Learning grasp strategies with partial shape information, Ashutosh Saxena, Lawson Wong, Andrew Y. Ng. In AAAI, 2008. [PDF]
@inproceedings{saxena_aaai09_3dgrasping,
title={Learning grasp strategies with partial shape information},
author={Ashutosh Saxena and Lawson Wong and Andrew Y. Ng.},
booktitle={AAAI},
year={2008}
}Abstract: We consider the problem of grasping novel objects in cluttered environments. If a full 3-d model of the scene were available, one could use the model to estimate the stability and robustness of different grasps (formalized as form/force-closure, etc); in practice, however, a robot facing a novel object will usually be able to perceive only the front (visible) faces of the object. In this paper, we propose an approach to grasping that estimates the stability of different grasps, given only noisy estimates of the shape of visible portions of an object, such as that obtained from a depth sensor. By combining this with a kinematic description of a robot arm and hand, our algorithm is able to compute a specific positioning of the robot’s fingers so as to grasp an object. We test our algorithm on two robots (with very different arms/manipulators, including one with a multi-fingered hand). We report results on the task of grasping objects of significantly different shapes and appearances than ones in the training set, both in highly cluttered and in uncluttered environments. We also apply our algorithm to the problem of unloading items from a dishwasher.
-

A Fast Data Collection and Augmentation Procedure for Object Recognition, Benjaminn Sapp, Ashutosh Saxena, Andrew Y. Ng. In AAAI, 2008. [PDF, More]
First presented at NIPS workshop on Principles of Learning Problem Design 2007.
@inproceedings{saxena_aaai09_datacollection,
title={Learning grasp strategies with partial shape information},
author={Benjaminn Sapp and Ashutosh Saxena and Andrew Y. Ng.},
booktitle={AAAI},
year={2008}
}Abstract: When building an application that requires object class recognition, having enough data to learn from is critical for good performance, and can easily determine the success or failure of the system. However, it is typically extremely labor intensive to collect data, as the process usually involves acquiring the image, then manual cropping and hand-labeling. Preparing large training sets for object recognition has already become one of the main bottlenecks for such emerging applications as mobile robotics and object recognition on the web. This paper focuses on a novel and practical solution to the dataset collection problem. Our method is based on using a green screen to rapidly collect example images; we then use a probabilistic model to rapidly synthesize a much larger training set that attempts to capture desired invariants in the object's foreground and background. We demonstrate this procedure on our own mobile robotics platform, where we achieve 135x savings in the time/effort needed to obtain a training set. Our data collection method is agnostic to the learning algorithm being used, and applies to any of a large class of standard object recognition methods. Given these results, we suggest that this method become a standard protocol for developing scalable object recognition systems. Further, we used our data to build reliable classifiers that enabled our robot to visually recognize an object in an office environment, and thereby fetch an object from an office in response to a verbal request.
-

Robotic Grasping of Novel Objects using Vision, Ashutosh Saxena, Justin Driemeyer, Andrew Y. Ng. International Journal of Robotics Research (IJRR), vol. 27, no. 2, pp. 157-173, Feb 2008. [PDF, ijrr-PDF, project page]
(Original version appeared in Neural Information Processing Systems (NIPS), 2006.)
@article{saxena2008roboticgrasping,
title={Robotic grasping of novel objects using vision},
author={Saxena, A. and Driemeyer, J. and Ng, A.Y.},
journal={The International Journal of Robotics Research},
volume={27},
number={2},
pages={157},
year={2008},
}Abstract: We consider the problem of grasping novel objects, specifically ones that are being seen for the first time through vision. Grasping a previously unknown object, one for which a 3-d model is not available, is a challenging problem. Further, even if given a model, one still has to decide where to grasp the object. We present a learning algorithm that neither requires, nor tries to build, a 3-d model of the object. Given two (or more) images of an object, our algorithm attempts to identify a few points in each image corresponding to good locations at which to grasp the object. This sparse set of points is then triangulated to obtain a 3-d location at which to attempt a grasp. This is in contrast to standard dense stereo, which tries to triangulate every single point in an image (and often fails to return a good 3-d model). Our algorithm for identifying grasp locations from an image is trained via supervised learning, using synthetic images for the training set. We demonstrate this approach on two robotic manipulation platforms. Our algorithm successfully grasps a wide variety of objects, such as plates, tape-rolls, jugs, cellphones, keys, screwdrivers, staplers, a thick coil of wire, a strangely shaped power horn, and others, none of which were seen in the training set. We also apply our method to the task of unloading items from dishwashers.
-
Learning 3-D Scene Structure from a Single Still Image, Ashutosh Saxena, Min Sun, Andrew Y. Ng. In ICCV workshop on 3D Representation for Recognition (3dRR-07), 2007. (best paper award) [ps, PDF, Make3d]
@inproceedings{saxena2007make3d,
title={Learning 3-D scene structure from a single still image},
author={Saxena, A. and Sun, M. and Ng, A.Y.},
booktitle={ICCV workshop on 3dRR},
year={2007},
}Abstract: We consider the problem of estimating detailed 3-d structure from a single still image of an unstructured environment. Our goal is to create 3-d models which are both quantitatively accurate as well as visually pleasing. For each small homogeneous patch in the image, we use a Markov Random Field (MRF) to infer a set of "plane parameters" that capture both the 3-d location and 3-d orientation of the patch. The MRF, trained via supervised learning, models both image depth cues as well as the relationships between different parts of the image. Inference in our model is tractable, and requires only solving a convex optimization problem. Other than assuming that the environment is made up of a number of small planes, our model makes no explicit assumptions about the structure of the scene; this enables the algorithm to capture much more detailed 3-d structure than does prior art (such as Saxena et al., 2005, Delage et al., 2005, and Hoiem et el., 2005), and also give a much richer experience in the 3-d flythroughs created using image-based rendering, even for scenes with significant non-vertical structure. Using this approach, we have created qualitatively correct 3-d models for 64.9% of 588 images downloaded from the internet, as compared to Hoiem et al.’s performance of 33.1%. Further, our models are quantitatively more accurate than either Saxena et al. or Hoiem et al.
-

A Vision-based System for Grasping Novel Objects in Cluttered Environments, Ashutosh Saxena, Lawson Wong, Morgan Quigley, Andrew Y. Ng. In International Symposium of Robotics Research (ISRR), 2007. [PDF, More]
@inproceedings{saxena2008_graspingsystem,
title={A Vision-based System for Grasping Novel Objects in Cluttered Environments},
author={Ashutosh Saxena and Lawson Wong and Morgan Quigley and Andrew Y. Ng},
booktitle={ISRR},
year={2007},
}Abstract: We present our vision-based system for grasping novel objects in cluttered environments. Our system can be divided into four components: 1) decide where to grasp an object, 2) perceive obstacles, 3) plan an obstacle-free path, and 4) follow the path to grasp the object. While most prior work assumes availability of a detailed 3-d model of the environment, our system focuses on developing algorithms that are robust to uncertainty and missing data, which is the case in real-world experiments. In this paper, we test our robotic grasping system using our STAIR (STanford AI Robots) platforms on two experiments: grasping novel objects and unloading items from a dishwasher. We also illustrate these ideas in the context of having a robot fetch an object from another room in response to a verbal request.
-

3-D Reconstruction from Sparse Views using Monocular Vision, Ashutosh Saxena, Min Sun, Andrew Y. Ng. In ICCV workshop on Virtual Representations and Modeling of Large-scale environments (VRML), 2007. [ps, PDF]
@inproceedings{saxena2007make3d,
title={3-D Reconstruction from Sparse Views using Monocular Vision},
author={Saxena, A. and Sun, M. and Ng, A.Y.},
booktitle={ICCV workshop on VRML},
year={2007},
}Abstract: We consider the task of creating a 3-d model of a large novel environment, given only a small number of images of the scene. This is a difficult problem, because if the images are taken from very different viewpoints or if they contain similar-looking structures, then most geometric reconstruction methods will have great difficulty finding good correspondences. Further, the reconstructions given by most algorithms include only points in 3-d that were observed in two or more images; a point observed only in a single image would not be reconstructed. In this paper, we show how monocular image cues can be combined with triangulation cues to build a photo-realistic model of a scene given only a few images—even ones taken from very different viewpoints or with little overlap. Our approach begins by oversegmenting each image into small patches (superpixels). It then simultaneously tries to infer the 3-d position and orientation of every superpixel in every image. This is done using a Markov Random Field (MRF) which simultaneously reasons about monocular cues and about the relations between multiple image patches, both within the same image and across different images (triangulation cues). MAP inference in our model is efficiently approximated using a series of linear programs, and our algorithm scales well to a large number of images.
-

3-D Depth Reconstruction from a Single Still Image, Ashutosh Saxena, Sung H. Chung, Andrew Y. Ng. International Journal of Computer Vision (IJCV), vol. 76, no. 1, pp 53-69, Jan 2008. (Online first: Aug 2007). [PDF, project page]
@article{saxena20083Ddepth,
title={3-d depth reconstruction from a single still image},
author={Saxena, A. and Chung, S.H. and Ng, A.Y.},
journal={International Journal of Computer Vision},
volume={76},
number={1},
pages={53--69},
year={2008},
publisher={Springer}
}Abstract: We consider the task of 3-d depth estimation from a single still image. We take a supervised learning approach to this problem, in which we begin by collecting a training set of monocular images (of unstructured indoor and outdoor environments which include forests, sidewalks, trees, buildings, etc.) and their corresponding ground-truth depthmaps. Then, we apply supervised learning to predict the value of the depthmap as a function of the image. Depth estimation is a challenging problem, since local features alone are insufficient to estimate depth at a point, and one needs to consider the global context of the image. Our model uses a hierarchical, multiscale Markov Random Field (MRF) that incorporates multiscale local- and global-image features, and models the depths and the relation between depths at different points in the image. We show that, even on unstructured scenes, our algorithm is frequently able to recover fairly accurate depthmaps. We further propose a model that incorporates both monocular cues and stereo (triangulation) cues, to obtain significantly more accurate depth estimates than is possible using either monocular or stereo cues alone.
-
Robotic Grasping of Novel Objects, Ashutosh Saxena, Justin Driemeyer, Justin Kearns, Andrew Y. Ng. In Neural Information Processing Systems (NIPS) 19, 2006. (spotlight paper) [PDF, more]
@inproceedings{saxena2006roboticgrasping,
title={Robotic grasping of novel objects},
author={Saxena, A. and Driemeyer, J. and Kearns, J. and Ng, A.Y.},
booktitle={Neural Information Processing Systems},
year={2006},
}Abstract: We consider the problem of grasping novel objects, specifically ones that are being seen for the first time through vision. We present a learning algorithm that neither requires, nor tries to build, a 3-d model of the object. Instead it predicts, directly as a function of the images, a point at which to grasp the object. Our algorithm is trained via supervised learning, using synthetic images for the training set. We demonstrate on a robotic manipulation platform that this approach successfully grasps a wide variety of objects, such as wine glasses, duct tape, markers, a translucent box, jugs, knife-cutters, cellphones, keys, screwdrivers, staplers, toothbrushes, a thick coil of wire, a strangely shaped power horn, and others, none of which were seen in the training set.
-
Depth Estimation using Monocular and Stereo Cues, Ashutosh Saxena, Jamie Schulte, Andrew Y. Ng. In 20th International Joint Conference on Artificial Intelligence (IJCAI), 2007. [PDF]
@inproceedings{saxena2007_stereo,
title={Depth Estimation using Monocular and Stereo Cues},
author={Saxena, A. and Schulte, J. and Ng, A.Y.},
journal={IJCAI},
year={2007},
}Abstract: Depth estimation in computer vision and robotics is most commonly done via stereo vision (stereopsis), in which images from two cameras are used to triangulate and estimate distances. However, there are also numerous monocular visual cues--such as texture variations and gradients, defocus, color/haze, etc.--that have heretofore been little exploited in such systems. Some of these cues apply even in regions without texture, where stereo would work poorly. In this paper, we apply a Markov Random Field (MRF) learning algorithm to capture some of these monocular cues, and incorporate them into a stereo system. We show that by adding monocular cues to stereo (triangulation) ones, we obtain significantly more accurate depth estimates than is possible using either monocular or stereo cues alone. This holds true for a large variety of environments, including both indoor environments and unstructured outdoor environments containing trees/forests, buildings, etc. Our approach is general, and applies to incorporating monocular cues together with any off-the-shelf stereo system.
-

Learning to Grasp Novel Objects using Vision, Ashutosh Saxena, Justin Driemeyer, Justin Kearns, Chioma Osondu, Andrew Y. Ng. In 10th International Symposium on Experimental Robotics (ISER), 2006. [PDF]
(Shorter version appeared in RSS Workshop on Manipulation for Human Environments, 2006.)
@inproceedings{saxena_iser06_grasping,
title={Learning to Grasp Novel Objects using Vision},
author={Ashutosh Saxena and Justin Driemeyer and Justin Kearns and Chioma Osondu and Andrew Y. Ng},
journal={ISER},
year={2006},
}Abstract: We consider the problem of grasping novel objects, specifically, ones that are being seen for the first time through vision.We present a learning algorithm which predicts, as a function of the images, the position at which to grasp the object. This is done without building or requiring a 3d model of the object. Our algorithm is trained via supervised learning, using synthetic images for the training set. Using our robotic arm, we successfully demonstrate this approach by grasping a variety of differently shaped objects, such as duct tape, markers, mugs, pens, wine glasses, knifecutters, jugs, keys, toothbrushes, books, and others, including many object types not seen in the training set.
-
Learning Depth from Single Monocular Images, Ashutosh Saxena, Sung H. Chung, Andrew Y. Ng. In Neural Information Processing Systems (NIPS) 18, 2005. [PDF, Make3D project page, Google Tech Talk]
@inproceedings{saxena2005learningdepth,
title={Learning depth from single monocular images},
author={Saxena, A. and Chung, S.H. and Ng, A.},
booktitle={Neural Information Processing Systems 18},
year={2005},
}Abstract: We consider the task of depth estimation from a single monocular image. We take a supervised learning approach to this problem, in which we begin by collecting a training set of monocular images (of unstructured outdoor environments which include forests, trees, buildings, etc.) and their corresponding ground-truth depthmaps. Then, we apply supervised learning to predict the depthmap as a function of the image. Depth estimation is a challenging problem, since local features alone are insufficient to estimate depth at a point, and one needs to consider the global context of the image. Our model uses a discriminatively-trained Markov Random Field (MRF) that incorporates multiscale local- and global-image features, and models both depths at individual points as well as the relation between depths at different points. We show that, even on unstructured scenes, our algorithm is frequently able to recover fairly accurate depthmaps.
-

High Speed Obstacle Avoidance using Monocular Vision and Reinforcement Learning, Jeff Michels, Ashutosh Saxena, Andrew Y. Ng. In 22nd Int'l Conf on Machine Learning (ICML), 2005. [PDF, PPT, project page, aerial vehicles]
@inproceedings{michels2005obstacleavoidance,
title={High speed obstacle avoidance using monocular vision and reinforcement learning},
author={Michels, J. and Saxena, A. and Ng, A.Y.},
booktitle={Proceedings of the 22nd international conference on Machine learning},
pages={593--600}, year={2005},
organization={ACM}
}Abstract: We consider the task of driving a remote control car at high speeds through unstructured outdoor environments. We present an approach in which supervised learning is first used to estimate depths from single monocular images. The learning algorithm can be trained either on real camera images labeled with ground-truth distances to the closest obstacles, or on a training set consisting of synthetic graphics images. The resulting algorithm is able to learn monocular vision cues that accurately estimate the relative depths of obstacles in a scene. Reinforcement learning/policy search is then applied within a simulator that renders synthetic scenes. This learns a control policy that selects a steering direction as a function of the vision system's output. We present results evaluating the predictive ability of the algorithm both on held out test data, and in actual autonomous driving experiments.
-

Non-Linear Dimensionality Reduction by Locally Linear Isomaps, Ashutosh Saxena, Abhinav Gupta and Amitabha Mukerjee. In Proc 11th Int'l Conf on Neural Information Processing, 2004. [PDF]
@inproceedings{saxena_llisomap_2004,
title={Non-Linear Dimensionality Reduction by Locally Linear Isomaps},
author={Ashutosh Saxena and Abhinav Gupta and Amitabha Mukerjee},
booktitle={Proc 11th Int'l Conf on Neural Information Processing},
year={2004},
}Abstract: Algorithms for nonlinear dimensionality reduction (NLDR) find meaningful hidden low-dimensional structures in a high-dimensional space. Current algorithms for NLDR are Isomaps, Local Linear Embed- ding and Laplacian Eigenmaps. Isomaps are able to reliably recover low- dimensional nonlinear structures in high-dimensional data sets, but suffer from the problem of short-circuiting, which occurs when the neighbor- hood distance is larger than the distance between the folds in the mani- folds. We propose a new variant of Isomap algorithm based on local linear properties of manifolds to increase its robustness to short-circuiting. We demonstrate that the proposed algorithm works better than Isomap al- gorithm for normal, noisy and sparse data sets.
-
In Use Parameter Estimation of Inertial Sensors by Detecting Multilevel Quasi-Static States,
Ashutosh Saxena, Gaurav Gupta, Vadim Gerasimov, Sebastian Ourselin. InLecture Notes in Computer Science, vol. 3684, KES, 2005. [PDF, Springer]
-
Robust Facial Expression Recognition using Spatially Localized Geometric Model
Ashutosh Saxena, Ankit Anand and Amitabha Mukerjee. In proc. Int'l Conf Systemics, Cybernetics and Informatics ICSCI, vol. 1, pp 124-129, 2004. [PDF]
-
Bioinspired Modification of Polystyryl Matrix: Single-step Chemical Evolution to a Moderately Conducting Polymer,
Ashutosh Saxena, S.G. Srivatsan, Vishal Saxena, Sandeep Verma. Chemistry Letters, vol. 33, no. 6, pp. 740-741, 2004. [PDF]
Seminars / Invited Talks / Technical Reports / Demos / Workshops
- How should a robot perceive the world? Ashutosh Saxena. In:
GRASP seminar, UPenn, 2012.
Robotics and Intelligent Machines (RIM) seminar, Georgia Tech, 2012.
CSAIL seminar, MIT, 2012.
VASC seminar, CMU, 2012.
University of Michigan, Ann Arbor, 2012.
UIUC, 2012.
University of California, Berkeley, 2012. - Perceiving 3D Environments for Robots. Ashutosh Saxena. In Midwest Vision workshop at UIUC, 2012.
- Learning Sequences of Controllers for Complex Manipulation Tasks, Jaeyong Sung, Bart Selman, Ashutosh Saxena. In ICML workshop on Prediction with Sequential Models, 2013. [PDF, arXiv]
- Learning Trajectory Preferences for Manipulators via Iterative Improvement, Ashesh Jain, Thorsten Joachims, Ashutosh Saxena. In ICML workshop on Robot Learning, 2013. [PDF,arXiv]
- Learning to Place Objects: Organizing a Room, Gaurab Basu, Yun Jiang, Ashutosh Saxena. Video contribution in ICRA,2012. [youtube video]
- 3D Perception for Personal Assistant Robots, Ashutosh Saxena. Talk in R:SS workshop on RGB-D cameras, 2011. [slides]
- Inferring 3D Articulated Models for Box Packaging Robot, Paul Heran Yang, Tiffany Low, Matthew Cong, Ashutosh Saxena. In RSS workshop on mobile manipulation, 2011. [PDF, More]
- Human Activity Detection from RGBD Images, Jae Y. Sung, Colin Ponce, Bart Selman, Ashutosh Saxena. In AAAI workshop on Pattern, Activity and Intent Recognition (PAIR), 2011. [PDF, More]
- Labeling 3D Scenes for Personal Assistant Robots, Hema Koppula, Abhishek Anand, Thorsten Joachims, Ashutosh Saxena. In R:SS workshop on RGB-D cameras, 2011. [PDF, More]
- Pose estimation from a single depth image for arbitrary kinematic skeletons, Daniel Ly, Ashutosh Saxena, Hod Lipson. In R:SS workshop on RGB-D cameras, 2011. [PDF]
- FeCCM for Scene Understanding: Helping the Robot to Learn Multiple Tasks, Congcong Li, TP Wong, Norris Xu, Ashutosh Saxena. Video contribution in International Conference on Robotics and Automation (ICRA 2011), 2011. [PDF, mp4, youtube, More]
- Make3D: Single Image Depth Perception and its applications to Robotics. Ashutosh Saxena. At NYU, 2009.
- Robotic Grasping and Depth Perception: Learning 3D Models from a Single Image.
Ashutosh Saxena. In:
AFRL workshop, 2010.
UC Berkeley, 2010.
Cornell University, 2009.
University of California, Los Angeles (UCLA), 2009.
TTI-C, 2009.
Oxford University (UK), 2008.
MSR Cambridge (UK), 2008.
Grasp seminar, University of Pennsylvania (Upenn), 2008.
PIXL seminar, Princeton University, 2008.
VASC seminar. Carnegie Mellon University (CMU), 2008.
GRAIL seminar. University of Washington, 2008.
Microsoft Research / Live-labs (Redmond), 2008.
PAML seminar, UIUC, 2008. - Rapid Interactive 3D Reconstruction from a Single Still Image, Ashutosh Saxena, Nuwan Senaratna, Savil Srivastava, Andrew Y. Ng. In SIGGRAPH Late Breaking work (Informal Session), 2008. [1-page PDF, Video]
- Monocular 3D Depth Perception for Navigation, Ashutosh Saxena. In ARO/NSF Workshop on Future Directions in Visual Navigation, May 2008.
- Learning to Open New Doors,
Ellen Klingbeil, Ashutosh Saxena, Andrew Y. Ng. In AAAI 17th Annual Robot Workshop and Exhibition, 2008. [PDF] - Building a 3-D Model From a Single Still Image,
Ashutosh Saxena, Min Sun and Andrew Y. Ng. Demonstration in Neural Information Processing Systems (NIPS), 2007.
Also presented at NIPS Workshop on The Grammar of Vision: Probabilistic Grammar-Based Models for Visual Scene Understanding and Object Categorization, 2007. [png]
Also in AAAI IS Demonstration, 2008. - Learning 3-D Object Orientation from Images,
Ashutosh Saxena, Justin Driemeyer and Andrew Y. Ng. NIPS workshop on Robotic Challenges for Machine Learning, 2007. [abstract, extended full version] - Data Manipulation and Creation Techniques for Learning Tasks,
NIPS workshop on Principles of Learning Problem Design, 2007. [ppt] - Monocular Vision and its applications,
HomeBrew Robotics Club, Jan 2007; Stanford PAIL, Apr 2007; Bay Area Vision Research Day (BAVRD), Aug 2007; Stanford DAGS, Oct 2007; Smith-Kettlewell Colloquium, Oct 2007; Stanford GRAI, Oct 2007; Nokia-NRC, Nov 2007; MIT, Jan 2008; Google, Jan 2008. - STAIR: The STanford Artificial Intelligence Robot project, Andrew Y. Ng, Stephen Gould, Morgan Quigley, Ashutosh Saxena and Eric Berger.
Learning Workshop, Snowbird, Apr 2008. - Learning to Grasp Novel Objects using Vision,
Ashutosh Saxena, Justin Driemeyer, Justin Kearns, Chioma Osondu, Andrew Y. Ng, RSS Workshop on Manipulation for Human Environments, 2006. - STAIR: Robotic Grasping of Novel Objects,
Stanford-KAIST Robotics Workshop, 2007. - Ultrasonic Sensor Network: Realtime Target Localization with Passive Self-Localization,
Ashutosh Saxena, and Andrew Ng, Project Report, CS229: Machine Learning, Stanford University, Dec 2004. - A New Embedded Multiresolution Signaling Scheme for CPFSK ,
Ashutosh Saxena, Ajit K. Chaturvedi, B. Tech. research thesis, IIT Kanpur, India, April 2004. - Adaptive Multirate CDMA for Uplink ensuring Maximum Proportional Fairness,
Ashutosh Saxena, Ajit K. Chaturvedi, IIT Kanpur tech report, April 2004. - SANKET: Hand Gesture Recognition,
Ashutosh Saxena, Aditya Awasthi and Vaibhav Vaish, IEEE CSIDC 2003. (More)
Patents
- Ashutosh Saxena, Jingwei Lu, Nimish Khanolkar, RETRIEVAL AND RANKING OF ITEMS UTILIZING SIMILARITY, US Patent Application.
- Ashutosh Saxena, Sung Chung, Min Sun, Andrew Y. Ng, ARRANGEMENT AND METHOD FOR THREE-DIMENSIONAL DEPTH IMAGE CONSTRUCTION, US Patent Application.
- Undisclosed, Stanford University, 2008.
Copyright Notice
All papers may be copyrighted by the journals/conferences, therefore, do not download without checking the journals' or conferences' copyright notices!
* The final, definitive version of this paper has been published in IJRR, vol, issue, Feb 2008 by Sage Publications Ltd, All rights reserved. (c) SAGE publications Ltd, 2008. It is available online at http://online.sagepub.com