
Brain4Cars: AI for Autonomous Vehicles
End-to-end multi-modal AI for autonomous robots and vehicles
- Information from multiple sources: cameras, GPS, vehicle dynamics
- Real-time inference in distilled, smaller, models
- Generative model maps inputs to control actions
- 1000s of miles of driving data
Autonomous Robots
End-to-end AI
For autonomous driving through unstructured outdoor environments, large-scale end-to-end models help address long-tail scenarios. The model perceives 3D layout from camera images and the reinforcement learning agent maps it to control actions.


Autonomous Flying Robots
Able to guide itself through forests, tunnels, or damaged buildings, autonomous flying robots could have tremendous value in search-and-rescue operations, according to the researchers.
The AI models map camera images to control actions, enabling robot to navigate around obstacles such as tree branches, poles, fences and buildings.

High Speed Obstacle Avoidance
The model first estimates depth from single monocular images. Reinforcement learning then learns a control policy that selects a steering direction based on estimated depths. Model is trained both in simulator and real data.
Selected Publications
-

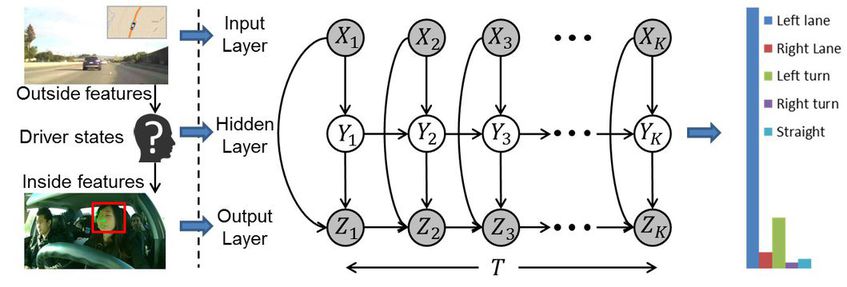
Recurrent Neural Networks for Driver Activity Anticipation via Sensory-Fusion Architecture. Ashesh Jain, Avi Singh, Hema S Koppula, Shane Soh, and Ashutosh Saxena. In International Conference on Robotics and Automation (ICRA), 2016. [project page, arxiv]
@inproceedings{rnn-brain4cars-saxena-2016,
title={Recurrent Neural Networks for Driver Activity Anticipation via Sensory-Fusion Architecture},
author={Ashesh Jain and Avi Singh and Hema S Koppula and Shane Soh and Ashutosh Saxena},
year={2016},
booktitle={International Conference on Robotics and Automation (ICRA)}
}Abstract: Anticipating the future actions of a human is a widely studied problem in robotics that requires spatio-temporal reasoning. In this work we propose a deep learning approach for anticipation in sensory-rich robotics applications. We introduce a sensory-fusion architecture which jointly learns to anticipate and fuse information from multiple sensory streams. Our architecture consists of Recurrent Neural Networks (RNNs) that use Long Short-Term Memory (LSTM) units to capture long temporal dependencies. We train our architecture in a sequence-to-sequence prediction manner, and it explicitly learns to predict the future given only a partial temporal context. We further introduce a novel loss layer for anticipation which prevents over-fitting and encourages early anticipation. We use our architecture to anticipate driving maneuvers several seconds before they happen on a natural driving data set of 1180 miles. The context for maneuver anticipation comes from multiple sensors installed on the vehicle. Our approach shows significant improvement over the state-of-the-art in maneuver anticipation by increasing the precision from 77.4% to 90.5% and recall from 71.2% to 87.4%.
-

Brain4Cars: Car That Knows Before You Do via Sensory-Fusion Deep Learning Architecture, Ashesh Jain, Hema S Koppula, Shane Soh, Bharad Raghavan, Avi Singh, Ashutosh Saxena. Cornell Tech Report (journal version), Jan 2016. (Earlier presented at ICCV'15.) [Arxiv PDF, project+video]
@inproceedings{misra_sung_lee_saxena_ijrr2015_groundingnlp,
title="Brain4Cars: Car That Knows Before You Do via Sensory-Fusion Deep Learning Architecture",
author="Ashesh Jain and Hema S Koppula and Shane Soh and Bharad Raghavan and Avi Singh and Ashutosh Saxena",
year="2016",
booktitle="Cornell Tech Report",
}Abstract: Advanced Driver Assistance Systems (ADAS) have made driving safer over the last decade. They prepare vehicles for unsafe road conditions and alert drivers if they perform a dangerous maneuver. However, many accidents are unavoidable because by the time drivers are alerted, it is already too late. Anticipating maneuvers beforehand can alert drivers before they perform the maneuver and also give ADAS more time to avoid or prepare for the danger.
In this work we propose a vehicular sensor-rich platform and learning algorithms for maneuver anticipation. For this purpose we equip a car with cameras, Global Positioning System (GPS), and a computing device to capture the driving context from both inside and outside of the car. In order to anticipate maneuvers, we propose a sensory-fusion deep learning architecture which jointly learns to anticipate and fuse multiple sensory streams. Our architecture consists of Recurrent Neural Networks (RNNs) that use Long Short-Term Memory (LSTM) units to capture long temporal dependencies. We propose a novel training procedure which allows the network to predict the future given only a partial temporal context. We introduce a diverse data set with 1180 miles of natural freeway and city driving, and show that we can anticipate maneuvers 3.5 seconds before they occur in real-time with a precision and recall of 90.5% and 87.4% respectively. -
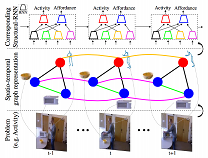
Structural-RNN: Deep Learning on Spatio-Temporal Graphs. Ashesh Jain, Amir R. Zamir, Silvio Savarese, and Ashutosh Saxena. In Computer Vision and Pattern Recognition (CVPR) oral, 2016. (best student paper) [PDF, project page, arxiv]
@inproceedings{rnn-brain4cars-saxena-2016,
title={Structural-RNN: Deep Learning on Spatio-Temporal Graphs},
author={Ashesh Jain and Amir R. Zamir and Silvio Savarese and Ashutosh Saxena},
year={2016},
booktitle={Computer Vision and Pattern Recognition (CVPR)}
}Abstract: Deep Recurrent Neural Network architectures, though remarkably capable at modeling sequences, lack an intuitive high-level spatio-temporal structure. That is while many problems in computer vision inherently have an underlying high-level structure and can benefit from it. Spatio-temporal graphs are a popular flexible tool for imposing such high-level intuitions in the formulation of real world problems. In this paper, we propose an approach for combining the power of high-level spatio-temporal graphs and sequence learning success of Recurrent Neural Networks (RNNs). We develop a scalable method for casting an arbitrary spatio-temporal graph as a rich RNN mixture that is feedforward, fully differentiable, and jointly trainable. The proposed method is generic and principled as it can be used for transforming any spatio-temporal graph through employing a certain set of well defined steps. The evaluations of the proposed approach on a diverse set of problems, ranging from modeling human motion to object interactions, shows improvement over the state-of-the-art with a large margin. We expect this method to empower a new convenient approach to problem formulation through high-level spatio-temporal graphs and Recurrent Neural Networks, and be of broad interest to the community.
-
Car that Knows Before You Do: Anticipating Maneuvers via Learning Temporal Driving Models. Ashesh Jain, Hema S Koppula, Bharad Raghavan, and Ashutosh Saxena. In International Conference on Computer Vision (ICCV), 2015. [PDF, Arxiv, project page]
@inproceedings{jain2015_brain4cars,
title={Know Before You Do: Anticipating Maneuvers via Learning Temporal Driving Models},
author={Ashesh Jain and Hema S Koppula and Bharad Raghavan and Ashutosh Saxena},
year={2015},
booktitle={Cornell Tech Report}
}Abstract: Advanced Driver Assistance Systems (ADAS) have made driving safer over the last decade. They prepare vehicles for unsafe road conditions and alert drivers if they perform a dangerous maneuver. However, many accidents are unavoidable because by the time drivers are alerted, it is already too late. Anticipating maneuvers a few seconds beforehand can alert drivers before they perform the maneuver and also give ADAS more time to avoid or prepare for the danger. Anticipation requires modeling the driver’s action space, events inside the vehicle such as their head movements, and also the outside environment. Performing this joint modeling makes anticipation a challenging problem.
In this work we anticipate driving maneuvers a few seconds before they occur. For this purpose we equip a car with cameras and a computing device to capture the context from both inside and outside of the car. We represent the context with expressive features and propose an Autoregressive Input-Output HMM to model the contextual information. We evaluate our approach on a diverse data set with 1180 miles of natural freeway and city driving and show that we can anticipate maneuvers 3.5 seconds before they occur with over 80% F1-score. Our computation time during inference is under 3.6 milliseconds.
-
Low-Power Parallel Algorithms for Single Image based Obstacle Avoidance in Aerial Robots, Ian Lenz, Mevlana Gemici, Ashutosh Saxena. In International Conference on Intelligent Robots and Systems (IROS), 2012. [PDF, more]
@inproceedings{lenz_lowpoweraerial_2012,
title={Low-Power Parallel Algorithms for Single Image based Obstacle Avoidance in Aerial Robots},
author={Ian Lenz and Mevlana Gemici and Ashutosh Saxena},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
year={2012}
}Abstract: For an aerial robot, perceiving and avoiding obstacles are necessary skills to function autonomously in a cluttered unknown environment. In this work, we use a single image captured from the onboard camera as input, produce obstacle classifications, and use them to select an evasive maneuver. We present a Markov Random Field based approach that models the obstacles as a function of visual features and non-local dependencies in neighboring regions of the image. We perform efficient inference using new low-power parallel neuromorphic hardware, where belief propagation updates are done using leaky integrate and fire neurons in parallel, while consuming less than 1 W of power. In outdoor robotic experiments, our algorithm was able to consistently produce clean, accurate obstacle maps which allowed our robot to avoid a wide variety of obstacles, including trees, poles and fences.
-

Autonomous MAV Flight in Indoor Environments using Single Image Perspective Cues, Cooper Bills, Joyce Chen, Ashutosh Saxena. In International Conference on Robotics and Automation (ICRA), 2011. [PDF, More]
@inproceedings{bills2011_indoorsingleimage,
title={Autonomous MAV Flight in Indoor Environments using Single Image Perspective Cues},
author={Cooper Bills and Joyce Chen and Ashutosh Saxena},
year={2011},
booktitle={ICRA}
}Abstract: We consider the problem of autonomously flying Miniature Aerial Vehicles (MAVs) in indoor environments such as home and office buildings. The primary long range sensor in these MAVs is a miniature camera. While previous approaches first try to build a 3D model in order to do planning and control, our method neither attempts to build nor requires a 3D model. Instead, our method first classifies the type of indoor environment the MAV is in, and then uses vision algorithms based on perspective cues to estimate the desired direction to fly. We test our method on two MAV platforms: a co-axial miniature helicopter and a toy quadrotor. Our experiments show that our vision algorithms are quite reliable, and they enable our MAVs to fly in a variety of corridors and staircases.
-

Robotic Object Detection: Learning to Improve the Classifiers using Sparse Graphs for Path Planning. Zhaoyin Jia, Ashutosh Saxena, Tsuhan Chen. In 22nd International Joint Conference on Artificial Intelligence (IJCAI), 2011. [PDF]
@inproceedings{jia2011_roboticobjectdetection,
title={Robotic Object Detection: Learning to Improve the Classifiers using Sparse Graphs for Path Planning},
author={Zhaoyin Jia and Ashutosh Saxena and Tsuhan Chen},
year={2011},
booktitle={IJCAI}
}Abstract: Object detection is a basic skill for a robot to perform tasks in human environments. In order to build a good object classifier, a large training set of labeled images is required; this is typically collected and labeled (often painstakingly) by a human. This method is not scalable and therefore limits the robot's detection performance. We propose an algorithm for a robot to collect more data in the environment during its training phase so that in the future it could detect objects more reliably. The first step is to plan a path for collecting additional training images, which is hard because a previously visited location affects the decision for the future locations. One key component of our work is path planning by building a sparse graph that captures these dependencies. The other key component is our learning algorithm that weighs the errors made in robot's data collection process while updating the classifier. In our experiments, we show that our algorithms enable the robot to improve its object classifiers significantly.
-

Autonomous Indoor Helicopter Flight using a Single Onboard Camera, Sai Prasanth Soundararaj, Arvind Sujeeth, Ashutosh Saxena. In International Conference on Intelligent RObots and Systems (IROS), 2009. [PDF]
@inproceedings{soundararajsaxena-door-iros2009,
title={Autonomous Indoor Helicopter Flight using a Single Onboard Camera},
author={Soundararaj, S.P. and Sujeeth, A. and Saxena, A.},
booktitle={IROS},
year={2009}
}Abstract: We consider the problem of autonomously flying a helicopter in indoor environments. Navigation in indoor settings poses two major challenges. First, real-time perception and response is crucial because of the high presence of obstacles. Second, the limited free space in such a setting places severe restrictions on the size of the aerial vehicle, resulting in a frugal payload budget.
We autonomously fly a miniature RC helicopter in small known environments using an on-board light-weight camera as the only sensor. We use an algorithm that combines data-driven image classification with optical flow techniques on the images captured by the camera to achieve real-time 3D localization and navigation. We perform successful autonomous test flights along trajectories in two different indoor settings. Our results demonstrate that our method is capable of autonomous flight even in narrow indoor spaces with sharp corners.
-

Learning Depth from Single Monocular Images, Ashutosh Saxena, Sung H. Chung, Andrew Y. Ng. In Neural Information Processing Systems (NIPS) 18, 2005. [PDF, Make3D project page, Google Tech Talk]
@inproceedings{saxena2005learningdepth,
title={Learning depth from single monocular images},
author={Saxena, A. and Chung, S.H. and Ng, A.},
booktitle={Neural Information Processing Systems 18},
year={2005},
}Abstract: We consider the task of depth estimation from a single monocular image. We take a supervised learning approach to this problem, in which we begin by collecting a training set of monocular images (of unstructured outdoor environments which include forests, trees, buildings, etc.) and their corresponding ground-truth depthmaps. Then, we apply supervised learning to predict the depthmap as a function of the image. Depth estimation is a challenging problem, since local features alone are insufficient to estimate depth at a point, and one needs to consider the global context of the image. Our model uses a discriminatively-trained Markov Random Field (MRF) that incorporates multiscale local- and global-image features, and models both depths at individual points as well as the relation between depths at different points. We show that, even on unstructured scenes, our algorithm is frequently able to recover fairly accurate depthmaps.
-
High Speed Obstacle Avoidance using Monocular Vision and Reinforcement Learning, Jeff Michels, Ashutosh Saxena, Andrew Y. Ng. In 22nd Int'l Conf on Machine Learning (ICML), 2005. [PDF, PPT, project page, aerial vehicles]
@inproceedings{michels2005obstacleavoidance,
title={High speed obstacle avoidance using monocular vision and reinforcement learning},
author={Michels, J. and Saxena, A. and Ng, A.Y.},
booktitle={Proceedings of the 22nd international conference on Machine learning},
pages={593--600}, year={2005},
organization={ACM}
}Abstract: We consider the task of driving a remote control car at high speeds through unstructured outdoor environments. We present an approach in which supervised learning is first used to estimate depths from single monocular images. The learning algorithm can be trained either on real camera images labeled with ground-truth distances to the closest obstacles, or on a training set consisting of synthetic graphics images. The resulting algorithm is able to learn monocular vision cues that accurately estimate the relative depths of obstacles in a scene. Reinforcement learning/policy search is then applied within a simulator that renders synthetic scenes. This learns a control policy that selects a steering direction as a function of the vision system's output. We present results evaluating the predictive ability of the algorithm both on held out test data, and in actual autonomous driving experiments.