Large Scale Robot Models: RoboBrain
Creating a robot frontier model requires various elements -
- VLAMs
- Agents with robotics tools
- Reflection with robot code
- RAG on robot knowledge graph
- Training with Real2Sim
We learn these models rom a variety of sources, including interactions that robots have while performing perception, planning and control, as well as natural language and visual data from the Internet.This is done across several modalities including symbols, natural language, visual or shape features, haptic properties, and so on. This allows robots to perform diverse tasks.
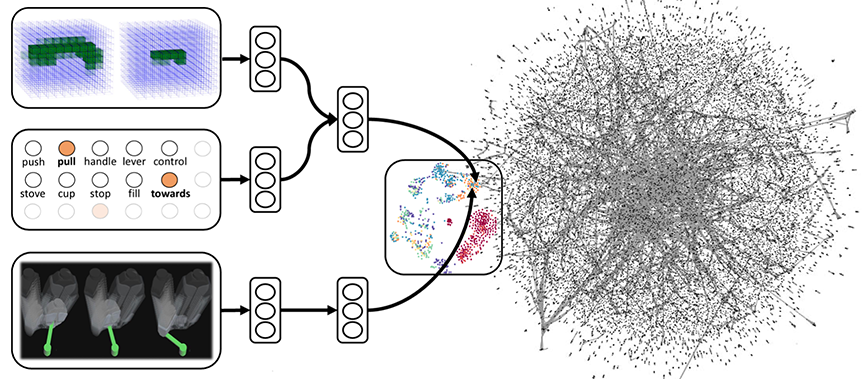
VLAM Agents with Tools

VLAMs
Embed 3D point-cloud, language, and action (trajectories) into a shared embedding space. Pre-train network's lower layers for multimodal feature embedding and then finetune.

Agents with Tools
Specific agents derived from the large-scale model have access to the right tools and focus on different aspects of the architecture: control (MPC), trajectory scoring, task sequencing, and perception.

Training with Real2Sim
Incorporate variety of data - perception, trajectories, language, videos - online, in simulation, real, and real-based-variants-in-sim. Extract the full value of that rare event.

Reflection with robot code
Our model sequences a task into a robot program, where each primitive specializes in an atomic operation such as moving close, pulling, grasping, and releasing.
Selected Publications
-

Deep Multimodal Embedding: Manipulating Novel Objects with Point-clouds, Language and Trajectories, Jaeyong Sung, Ian Lenz, and Ashutosh Saxena. International Conference on Robotics and Automation (ICRA), 2017. (ICRA Best cognitive robotics paper finalist) [PDF, arxiv, project page]
@inproceedings{robobarista_deepmultimodalembedding_2015,
title={Deep Multimodal Embedding: Manipulating Novel Objects with Point-clouds, Language and Trajectories},
author={Jaeyong Sung and Ian Lenz and Ashutosh Saxena},
year={2017},
booktitle={International Conference on Robotics and Automation (ICRA)}
}Abstract: A robot operating in a real-world environment needs to perform reasoning with a variety of sensing modalities. However, manually designing features that allow a learning algorithm to relate these different modalities can be extremely challenging. In this work, we consider the task of manipulating novel objects and appliances. To this end, we learn to embed point-cloud, natural language, and manipulation trajectory data into a shared embedding space using a deep neural network. In order to learn semantically meaningful spaces throughout our network, we introduce a method for pre-training its lower layers for multimodal feature embedding and a method for fine- tuning this embedding space using a loss-based margin. We test our model on the Robobarista dataset, where we achieve significant improvements in both accuracy and inference time over the previous state of the art.
-
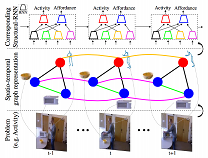
Structural-RNN: Deep Learning on Spatio-Temporal Graphs. Ashesh Jain, Amir R. Zamir, Silvio Savarese, and Ashutosh Saxena. In Computer Vision and Pattern Recognition (CVPR) oral, 2016. (best student paper) [PDF, project page, arxiv]
@inproceedings{rnn-brain4cars-saxena-2016,
title={Structural-RNN: Deep Learning on Spatio-Temporal Graphs},
author={Ashesh Jain and Amir R. Zamir and Silvio Savarese and Ashutosh Saxena},
year={2016},
booktitle={Computer Vision and Pattern Recognition (CVPR)}
}Abstract: Deep Recurrent Neural Network architectures, though remarkably capable at modeling sequences, lack an intuitive high-level spatio-temporal structure. That is while many problems in computer vision inherently have an underlying high-level structure and can benefit from it. Spatio-temporal graphs are a popular flexible tool for imposing such high-level intuitions in the formulation of real world problems. In this paper, we propose an approach for combining the power of high-level spatio-temporal graphs and sequence learning success of Recurrent Neural Networks (RNNs). We develop a scalable method for casting an arbitrary spatio-temporal graph as a rich RNN mixture that is feedforward, fully differentiable, and jointly trainable. The proposed method is generic and principled as it can be used for transforming any spatio-temporal graph through employing a certain set of well defined steps. The evaluations of the proposed approach on a diverse set of problems, ranging from modeling human motion to object interactions, shows improvement over the state-of-the-art with a large margin. We expect this method to empower a new convenient approach to problem formulation through high-level spatio-temporal graphs and Recurrent Neural Networks, and be of broad interest to the community.
-

Robo Brain: Large-Scale Knowledge Engine for Robots, Ashutosh Saxena, Ashesh Jain, Ozan Sener, Aditya Jami, Dipendra K Misra, Hema S Koppula. International Symposium on Robotics Research (ISRR), 2015. [PDF, arxiv, project page] (Earlier Cornell Tech Report, Aug 2014.)
@article{saxena_robobrain2014,
title={Robo Brain: Large-Scale Knowledge Engine for Robots},
author={Ashutosh Saxena and Ashesh Jain and Ozan Sener and Aditya Jami and Dipendra K Misra and Hema S Koppula},
year={2015},
journal={International Symposium on Robotics Research (ISRR)}
}Abstract: In this paper we introduce a knowledge engine, which learns and shares knowledge representations, for robots to carry out a variety of tasks. Building such an engine brings with it the challenge of dealing with multiple data modalities including symbols, natural language, haptic senses, robot trajectories, visual features and many others. The knowledge stored in the engine comes from multiple sources including physical interactions that robots have while performing tasks (perception, planning and control), knowledge bases from the Internet and learned representations from several robotics research groups.
We discuss various technical aspects and associated challenges such as modeling the correctness of knowledge, inferring latent information and formulating different robotic tasks as queries to the knowledge engine. We describe the system architecture and how it supports different mechanisms for users and robots to interact with the engine. Finally, we demonstrate its use in three important research areas: grounding natural language, perception, and planning, which are the key building blocks for many robotic tasks. This knowledge engine is a collaborative effort and we call it RoboBrain: http://www.robobrain.me
-

Tell Me Dave: Context-Sensitive Grounding of Natural Language to Manipulation Instructions, Dipendra K Misra, Jaeyong Sung, Kevin Lee, Ashutosh Saxena. International Journal of Robotics Research (IJRR), Jan 2016. (Earlier presented at RSS'14.) [PDF, project+video]
@inproceedings{misra_sung_lee_saxena_ijrr2015_groundingnlp,
title="Tell Me Dave: Context-Sensitive Grounding of Natural Language to Manipulation Instructions",
author="Dipendra K Misra and Jaeyong Sung and Kevin Lee and Ashutosh Saxena",
year="2016",
booktitle="International Journal of Robotics Research (IJRR)",
}Abstract: It is important for a robot to be able to interpret natural language commands given by a human. In this paper, we consider performing a sequence of mobile manipulation tasks with instructions described in natural language (NL). Given a new environment, even a simple task such as of boiling water would be performed quite differently depending on the presence, location and state of the objects. We start by collecting a dataset of task descriptions in free-form natural language and the corresponding grounded task-logs of the tasks performed in an online robot simulator. We then build a library of verb-environment-instructions that represents the possible instructions for each verb in that environment - these may or may not be valid for a different environment and task context.
We present a model that takes into account the variations in natural language, and ambiguities in grounding them to robotic instructions with appropriate environment context and task constraints. Our model also handles incomplete or noisy NL instructions. Our model is based on an energy function that encodes such properties in a form isomorphic to a conditional random field. We evaluate our model on tasks given in a robotic simulator and show that it successfully outperforms the state-of-the-art with 61.8% accuracy. We also demonstrate several of grounded robotic instruction sequences on a PR2 robot through Learning from Demonstration approach. -
Robobarista: Object Part based Transfer of Manipulation Trajectories from Crowd-sourcing in 3D Pointclouds, Jaeyong Sung, Seok H Jin, and Ashutosh Saxena. International Symposium on Robotics Research (ISRR), 2015. [PDF, arxiv, project page]
@inproceedings{sung2015_robobarista,
title={Robobarista: Object Part based Transfer of Manipulation Trajectories from Crowd-sourcing in 3D Pointclouds},
author={Jaeyong Sung and Seok H Jin and Ashutosh Saxena},
year={2015},
booktitle={International Symposium on Robotics Research (ISRR)}
}Abstract: There is a large variety of objects and appliances in human environments, such as stoves, coffee dispensers, juice extractors, and so on. It is challenging for a roboticist to program a robot for each of these object types and for each of their instantiations. In this work, we present a novel approach to manipulation planning based on the idea that many household objects share similarly-operated object parts. We formulate the manipulation planning as a structured prediction problem and design a deep learning model that can handle large noise in the manipulation demonstrations and learns features from three different modalities: point-clouds, language and trajectory. In order to collect a large number of manipulation demonstrations for different objects, we developed a new crowd-sourcing platform called Robobarista. We test our model on our dataset consisting of 116 objects with 249 parts along with 250 language instructions, for which there are 1225 crowd-sourced manipulation demonstrations. We further show that our robot can even manipulate objects it has never seen before.
-

DeepMPC: Learning Deep Latent Features for Model Predictive Control. Ian Lenz, Ross Knepper, and Ashutosh Saxena. In Robotics Science and Systems (RSS), 2015. (full oral) [PDF, extended version PDF, project page]
@inproceedings{deepmpc-lenz-knepper-saxena-rss2015,
title={DeepMPC: Learning Deep Latent Features for Model Predictive Control},
author={Ian Lenz and Ross Knepper and Ashutosh Saxena},
year={2015},
booktitle={Robotics Science and Systems (RSS)}
}Abstract: Designing controllers for tasks with complex non-linear dynamics is extremely challenging, time-consuming, and in many cases, infeasible. This difficulty is exacerbated in tasks such as robotic food-cutting, in which dynamics might vary both with environmental properties, such as material and tool class, and with time while acting. In this work, we present DeepMPC, an online real-time model-predictive control approach designed to handle such difficult tasks. Rather than hand-design a dynamics model for the task, our approach uses a novel deep architecture and learning algorithm, learning controllers for complex tasks directly from data. We validate our method in experiments on a large-scale dataset of 1488 material cuts for 20 diverse classes, and in 450 real-world robotic experiments, demonstrating significant improvement over several other approaches.
-

Deep Learning for Detecting Robotic Grasps, Ian Lenz, Honglak Lee, Ashutosh Saxena. International Journal on Robotics Research (IJRR), 2015. [IJRR link, PDF, more]
@article{lenz2015_deeplearning_roboticgrasp_ijrr,
title={Deep Learning for Detecting Robotic Grasps},
author={Ian Lenz and Honglak Lee and Ashutosh Saxena},
year={2015},
journal={IJRR}
}Abstract: We consider the problem of detecting robotic grasps in an RGBD view of a scene containing objects. In this work, we apply a deep learning approach to solve this problem, which avoids time-consuming hand-design of features. This presents two main challenges. First, we need to evaluate a huge number of candidate grasps. In order to make detection fast and robust, we present a two-step cascaded system with two deep networks, where the top detections from the first are re-evaluated by the second. The first network has fewer features, is faster to run, and can effectively prune out unlikely candidate grasps. The second, with more features, is slower but has to run only on the top few detections. Second, we need to handle multimodal inputs effectively, for which we present a method that applies structured regularization on the weights based on multimodal group regularization. We show that our method improves performance on an RGBD robotic grasping dataset, and can be used to successfully execute grasps on two different robotic platforms.
(An earlier version was presented in Robotics Science and Systems (RSS) 2013.)
-
Learning Preferences for Manipulation Tasks from Online Coactive Feedback, Ashesh Jain, Shikhar Sharma, Thorsten Joachims, Ashutosh Saxena. In International Journal of Robotics Research (IJRR), 2015. [PDF, project+video]
@inproceedings{jainsaxena2015_learningpreferencesmanipulation,
title="Learning Preferences for Manipulation Tasks from Online Coactive Feedback",
author="Ashesh Jain and Shikhar Sharma and Thorsten Joachims and Ashutosh Saxena",
year="2015",
booktitle="International Journal of Robotics Research (IJRR)",
}Abstract: We consider the problem of learning preferences over trajectories for mobile manipulators such as personal robots and assembly line robots. The preferences we learn are more intricate than simple geometric constraints on trajectories; they are rather governed by the surrounding context of various objects and human interactions in the environment. We propose a coactive online learning framework for teaching preferences in contextually rich environments. The key novelty of our approach lies in the type of feedback expected from the user: the human user does not need to demonstrate optimal trajectories as training data, but merely needs to iteratively provide trajectories that slightly improve over the trajectory currently proposed by the system. We argue that this coactive preference feedback can be more easily elicited than demonstrations of optimal trajectories. Nevertheless, theoretical regret bounds of our algorithm match the asymptotic rates of optimal trajectory algorithms. We implement our algorithm on two high-degree-of-freedom robots, PR2 and Baxter, and present three intuitive mechanisms for providing such incremental feedback. In our experimental evaluation we consider two context rich settings, household chores and grocery store checkout, and show that users are able to train the robot with just a few feedbacks (taking only a few minutes).
Earlier version of this work was presented at the NIPS'13 and ISRR'13.
-

PlanIt: A Crowdsourcing Approach for Learning to Plan Paths from Large Scale Preference Feedback. Ashesh Jain, Debarghya Das, Ashutosh Saxena. In International Conference on Robotics and Automation (ICRA), 2015. [PDF, PlanIt website]
@inproceedings{planit-jain-das-saxena-2014,
title={PlanIt: A Crowdsourcing Approach for Learning to Plan Paths from Large Scale Preference Feedback},
author={Ashesh Jain and Debarghya Das and Ashutosh Saxena},
year={2015},
booktitle={ICRA}
}Abstract: We consider the problem of learning user preferences over robot trajectories in environments rich in objects and humans. This is challenging because the criterion defining a good trajectory varies with users, tasks and interactions in the environments. We use a cost function to represent how preferred the trajectory is; the robot uses this cost function to generate a trajectory in a new environment. In order to learn this cost function, we design a system - PlanIt, where non-expert users can see robots motion for different asks and label segments of the video as good/bad/neutral. Using this weak, noisy labels, we learn the parameters of our model. Our model is a generative one, where the preferences are expressed as function of grounded object affordances. We test our approach on 112 different environments, and our extensive experiments show that we can learn meaningful preferences in the form of grounded planning affordances, and then use them to generate preferred trajectories in human environments.
-

Anticipatory Planning for Human-Robot Teams. Hema S Koppula, Ashesh Jain, Ashutosh Saxena. In 14th International Symposium on Experimental Robotics (ISER), 2014. [PDF, webpage]
@article{koppula-anticipatoryplanning-iser2014,
title={Anticipatory Planning for Human-Robot Teams},
author={Hema Koppula and Ashesh Jain and Ashutosh Saxena},
year={2014},
journal={ISER}
}Abstract: When robots work alongside humans for performing collaborative tasks, they need to be able to anticipate human's future actions and plan appropriate actions. The tasks we consider are performed in contextually-rich environments containing objects, and there is a large variation in the way humans perform these tasks. We use a graphical model to represent the state-space, where we model the humans through their low-level kinematics as well as their high-level intent, and model their interactions with the objects through physically-grounded object affordances. This allows our model to anticipate a belief about possible future human actions, and we model the human's and robot's behavior through an MDP in this rich state-space. We further discuss that due to perception errors and the limitations of the model, the human may not take the optimal action and therefore we present robot's anticipatory planning with different behaviors of the human within the model's scope. In experiments on Cornell Activity Dataset, we show that our method performs better than various baselines for collaborative planning.
-
Synthesizing Manipulation Sequences for Under-Specified Tasks using Unrolled Markov Random Fields. Jaeyong Sung, Bart Selman, Ashutosh Saxena. In International Conference on Intelligent Robotics and Systems (IROS), 2014. [PDF]
@inproceedings{sung-selman-saxena-learningsequenceofcontrollers_2014,
title={Synthesizing Manipulation Sequences for Under-Specified Tasks using Unrolled Markov Random Fields},
author={Jaeyong Sung and Bart Selman and Ashutosh Saxena},
year={2014},
booktitle={IROS}
}Abstract: Many tasks in human environments require performing a sequence of navigation and manipulation steps involving objects. In unstructured human environments, the location and configuration of the objects involved often change in unpredictable ways. This requires a high-level planning strategy that is robust and flexible in an uncertain environment. We propose a novel dynamic planning strategy, which can be trained from a set of example sequences. High level tasks are expressed as a sequence of primitive actions or controllers (with appropriate parameters). Our score function, based on Markov Random Field (MRF), captures the relations between environment, controllers, and their arguments. By expressing the environment using sets of attributes, the approach generalizes well to unseen scenarios. We train the parameters of our MRF using a maximum margin learning method. We provide a detailed empirical validation of our overall framework demonstrating successful plan strategies for a variety of tasks.
-
Learning Trajectory Preferences for Manipulators via Iterative Improvement, Ashesh Jain, Brian Wojcik, Thorsten Joachims, Ashutosh Saxena. In Neural Information Processing Systems (NIPS), 2013. [PDF, project+video]
@inproceedings{jainsaxena2013_trajectorypreferences,
title="Learning Trajectory Preferences for Manipulators via Iterative Improvement",
author="Ashesh Jain and Brian Wojcik and Thorsten Joachims and Ashutosh Saxena",
year="2013",
booktitle="Neural Information Processing Systems (NIPS)",
}Abstract: We consider the problem of learning good trajectories for manipulation tasks. This is challenging because the criterion defining a good trajectory varies with users, tasks and environments. In this paper, we propose a co-active online learning framework for teaching robots the preferences of its users for object manipulation tasks. The key novelty of our approach lies in the type of feedback expected from the user: the human user does not need to demonstrate optimal trajectories as training data, but merely needs to iteratively provide trajectories that slightly improve over the trajectory currently proposed by the system. We argue that this co-active preference feedback can be more easily elicited from the user than demonstrations of optimal trajectories, which are often challenging and non-intuitive to provide on high degrees of freedom manipulators. Nevertheless, theoretical regret bounds of our algorithm match the asymptotic rates of optimal trajectory algorithms. We demonstrate the generalizability of our algorithm on a variety of grocery checkout tasks, for whom, the preferences were not only influenced by the object being manipulated but also by the surrounding environment.
An earlier version of this work was presented at the ICML workshop on Robot Learning, June 2013. [PDF]
-
Deep Learning for Detecting Robotic Grasps, Ian Lenz, Honglak Lee, Ashutosh Saxena. In Robotics: Science and Systems (RSS), 2013. [PDF, arXiv, more]
@inproceedings{lenz2013_deeplearning_roboticgrasp,
title={Deep Learning for Detecting Robotic Grasps},
author={Ian Lenz and Honglak Lee and Ashutosh Saxena},
year={2013},
booktitle={RSS}
}Abstract: We consider the problem of detecting robotic grasps in an RGB-D view of a scene containing objects. In this work, we apply a deep learning approach to solve this problem, which avoids time-consuming hand-design of features. One challenge is that we need to handle multimodal inputs well, for which we present a method to apply structured regularization on the weights based on multimodal group regularization. We demonstrate that our method outperforms the previous state-of-the-art methods in robotic grasp detection, and can be used to successfully execute grasps on a Baxter robot.
(An earlier version was presented in International Conference on Learning Representations (ICLR), 2013.)
-

Beyond geometric path planning: Learning context-driven trajectory preferences via sub-optimal feedback. Ashesh Jain, Shikhar Sharma, Ashutosh Saxena. In International Symposium of Robotics Research (ISRR), 2013. [PDF, project+video]
@inproceedings{jain_contextdrivenpathplanning_2013,
title={Beyond geometric path planning: Learning context-driven trajectory preferences via sub-optimal feedback},
author={Ashesh Jain and Shikhar Sharma and Ashutosh Saxena},
year={2013},
booktitle={ISRR}
}Abstract: We consider the problem of learning preferences over trajectories for mobile manipulators such as personal robots and assembly line robots. The preferences we learn are more intricate than those arising from simple geometric constraints on robot's trajectory, such as distance of the robot from human etc. Our preferences are rather governed by the surrounding context of various objects and human interactions in the environment. Such preferences makes the problem challenging because the criterion of defining a good trajectory now varies with the task, with the environment and across the users. Furthermore, demonstrating optimal trajectories (e.g., learning from expert's demonstrations) is often challenging and non-intuitive on high degrees of freedom manipulators. In this work, we propose an approach that requires a non-expert user to only incrementally improve the trajectory currently proposed by the robot. We implement our algorithm on two high degree-of-freedom robots, PR2 and Baxter, and present three intuitive mechanisms for providing such incremental feedback. In our experimental evaluation we consider two context rich settings - household chores and grocery store checkout - and show that users are able to train the robot with just a few feedbacks (taking only a few minutes). Despite receiving sub-optimal feedback from non-expert users, our algorithm enjoys theoretical bounds on regret that match the asymptotic rates of optimal trajectory algorithms.
-

Learning to Open New Doors, Ellen Klingbeil, Ashutosh Saxena, Andrew Y. Ng. In Int'l conf on Intelligent Robots and Systems (IROS), 2010. [PDF]
First published in Robotics Science and Systems (RSS) workshop on Robot Manipulation, 2008. [PDF]
@inproceedings{klingbeilsaxena-door-iros2010,
title={Learning to Open New Doors},
author={Klingbeil, E. and Saxena, A. and Ng, A.Y.},
booktitle={IROS},
year={2010}
}Abstract: We consider the problem of enabling a robot to autonomously open doors, including novel ones that the robot has not previously seen. Given the large variation in the appearances and locations of doors and door handles, this is a challenging perception and control problem; but this capability will significantly enlarge the range of environments that our robots can autonomously navigate through. In this paper, we focus on the case of doors with door handles. We propose an approach that, rather than trying to build a full 3d model of the door/door handle--which is challenging because of occlusion, specularity of many door handles, and the limited accuracy of our 3d sensors--instead uses computer vision to choose a manipulation strategy. Specifically, it uses an image of the door handle to identify a small number of "3d key locations," such as the axis of rotation of the door handle, and the location of the end-point of the door-handle. These key locations then completely define a trajectory for the robot end-effector (hand) that successfully turns the door handle and opens the door. Evaluated on a large set of doors that the robot had not previously seen, it successfully opened 31 out of 34 doors. We also show that this approach of using vision to identify a small number of key locations also generalizes to a range of other tasks, including turning a thermostat knob, pulling open a drawer, and pushing elevator buttons.
-

Robotic Grasping of Novel Objects, Ashutosh Saxena, Justin Driemeyer, Justin Kearns, Andrew Y. Ng. In Neural Information Processing Systems (NIPS) 19, 2006. (spotlight paper) [PDF, more]
@inproceedings{saxena2006roboticgrasping,
title={Robotic grasping of novel objects},
author={Saxena, A. and Driemeyer, J. and Kearns, J. and Ng, A.Y.},
booktitle={Neural Information Processing Systems},
year={2006},
}Abstract: We consider the problem of grasping novel objects, specifically ones that are being seen for the first time through vision. We present a learning algorithm that neither requires, nor tries to build, a 3-d model of the object. Instead it predicts, directly as a function of the images, a point at which to grasp the object. Our algorithm is trained via supervised learning, using synthetic images for the training set. We demonstrate on a robotic manipulation platform that this approach successfully grasps a wide variety of objects, such as wine glasses, duct tape, markers, a translucent box, jugs, knife-cutters, cellphones, keys, screwdrivers, staplers, toothbrushes, a thick coil of wire, a strangely shaped power horn, and others, none of which were seen in the training set.