

Brain4Cars: End-to-end trained AI for Autonomous Navigation for Cars and Drones
For autonomous driving through unstructured outdoor environments, large-scale end-to-end models map multi-modal input from camera and sensors to behavior prediction and trajectories. Applications include ADAS, autonomous off-road driving, and drones.


Large-scale robot models with joint multi-modal embeddings - language, 3D, images and planning
RoboBrain, a large-scale robot model, learns from publicly available Internet resources, computer simulations, and real-life robot trials. The model embeds everything robotics - images, language, trajectories - all into a joint space. Applications include prototyping for robotics research, household robots, and self-driving cars. Drives robots at Cornell, Stanford, UC Berkeley and Brown University.
- Selected Papers: NIPS'06, IJRR'08, AAAI'08a, ICRA'11, ICRA'12, RSS'13, RSS'13, ICRA'12, IJRR'12, IROS 2010.
- Research/Code/Data: Dishwasher, Cluttered (Barrett), Opening New Doors, project webpage, Opening New Doors.
- Popular Press: New York Times, Wired Magazine, NBC, ABC, BBC, CBS WBNG Action News, MarketWatch.


Deep Multi-modal Embeddings for Robots: Grasping, Manipulation, Cooking Food, Opening Doors
Deep Learning to predict robotic grasps, even for objects of types never seen before by the robot. Enabled numerous robotic tasks such as unloading items from a dishwasher, clearing up a cluttered table, opening new doors, place objects in a fridge, and more.
- Selected Papers: NIPS'06, IJRR'08, AAAI'08a, ICRA'11, ICRA'12, RSS'13, RSS'13, ICRA'12, IJRR'12, IROS 2010.
- Research/Code/Data: Dishwasher, Cluttered (Barrett), Opening New Doors, project webpage, Opening New Doors.
- Popular Press: New York Times, Wired Magazine, NBC, ABC, BBC, CBS WBNG Action News, MarketWatch.


Generative AI Models for 3D Perception and Anticipating Human Activities
Anticipating which activities will a human do next (and how) enables a robot to do better planning. We propose a generative model that captures the rich context of human structure, activities and how humans use objects. It generates a distribution over a large space of future human activities.
- Selected Papers: ICML'13, RSS'13 (best student paper), ICML'12, ISER'12, CVPR'13 (oral), RSS'13.
- Research/Code/Data: project webpage
- Popular Press: Kurzweil AI, Wired, The Verge, Time Magazine, LA Times, CBS News, NBC News, Discovery News, National Geographic, FOX News (Studio B), Daily Show.


Make3D: Single Image Depth Perception
Learning algorithms to predict depth and infer 3-d models, given just a single still image. Applications included creating immersive 3-d experience from users' photos, improving performance of stereovision, creating large-scale models from a few images, robot navigation, etc. Tens of thousands of users have converted their single photographs into 3D models.
- Selected Papers: NIPS'05, IJCV'07, ICCV-3dRR'07, AAAI-Nectar'08, IEEE-PAMI'08, NIPS'08.
- Research/Code/Data: 2005, 2007, data.
- Online demo: Make3D.cs.cornell.edu.
- Popular Press: New Scientist, Technology Review, Scientific Computing, NTT (Japan).


Deep Cascaded Models: Holistic Scene Understanding
Holistic scene understanding requires solving several tasks simultaneously, including object detection, scene categorization, labeling of meaningful regions, and 3-d reconstruction. We develop a learning method that couples these individual sub-tasks for improving performance in each of them.
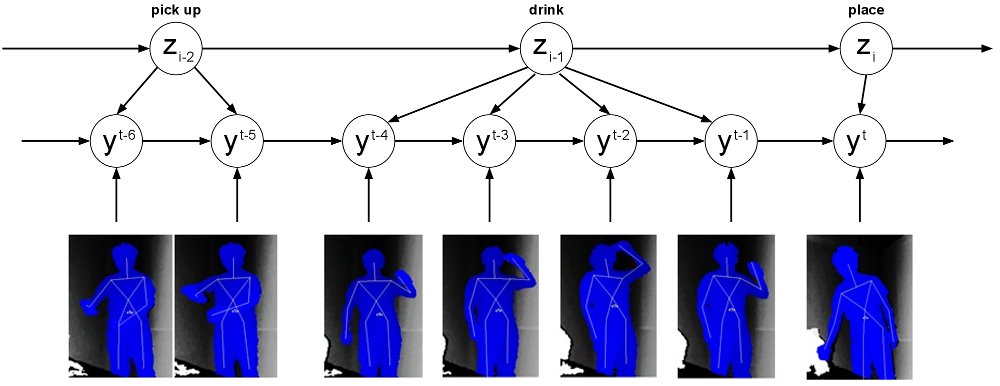

3D Scene Perception and Human Activities from Videos
Being able to detect human activities is important for making personal assistant robots useful in performing assistive tasks. Our CAD dataset comprises twelve different activities (composed of several sub-activities) performed by four people in different environments, such as a kitchen, a living room, and office, etc. Tested on robots reactively responding to the detected activities. (Code + CAD dataset available).
- Selected Papers: AAAI PAIR'11, ICRA'12, GECCO'12, IJRR'13, ICML'13, RSS'13 (best student paper), NIPS'11a, TPAMI'12, NIPS'11b, IJRR'12, CVPR'13a (oral), CVPR'13b (oral).
- Research/Code/Data: project webpage, with CAD-60 and CAD-120 dataset and code.
- Popular Press: E&T Magazine, R&D Magazine, Gizmag, GizmoWatch, myScience, WonderHowTo, Geekosystem, New Scientist (July 21).

Sim2Real: Large-scale AI model training with synthetic datasets for Robots
The issue of what data is there to learn from is at the heart of all learning algorithms---often even an inferior learning algorithm will outperform a superior one, if it is given more data to learn from. We proposed a novel and practical solution to the dataset collection problem; we use AI models to generate and synthesize a large training set based on rare, real-world examples.
- Selected Papers: AAAI'08.
- Research/Code/Data: here.
- Video: coming soon.
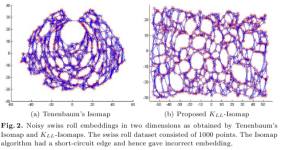
Noise tolerant Embeddings with Locally Linear Isomaps
Isomaps (for non-linear dimensionality reduction) suffer from the problem of short-circuiting, which occurs when the neighborhood distance is larger than the distance between the folds in the manifolds. We proposed a new variant of Isomap algorithm based on local linear properties of manifolds to increase its robustness to short-circuiting.
- Selected Papers: Int'l Conf NIP'05.
Other projects See publications page for more.