Make3D - Generating 3D Depths & Videos
In this pioneering work, we consider the task of 3d depth estimation from a single monocular image. Depth estimation from a single image is a challenging problem, since local features alone are insufficient to estimate depth at a point, and one needs to consider the global context of the image.
Our model incorporates multiscale local- and global-image features, and models both depths at individual points as well as the relation between depths at different points. We show that, even on unstructured scenes, our model is frequently able to recover fairly accurate depthmaps.

Applications
Holopad: TinTin, Chief Scientist
Steven Spielberg's movie Tintin reimagines how we engage in 3D with what was once a static printed book.
TinTin Blurs The Line Between Books, Movies, And Apps. Techcrunch.
Zunavision, Co-founder & CTO
AI that generates 3D content within videos.
Embed Ads In User-Generated Videos With ZunaVision. New York Times. ABC News.

Autonomous Flying Robots
Able to guide itself through forests, tunnels, or damaged buildings, autonomous flying robots could have tremendous value in search-and-rescue operations, according to the researchers.
The AI models map camera images to control actions, enabling robot to navigate around obstacles such as tree branches, poles, fences and buildings.

High Speed Obstacle Avoidance
The model first estimates depth from single monocular images. Reinforcement learning then learns a control policy that selects a steering direction based on estimated depths. Model is trained both in simulator and real data.
Selected Publications
-

Learning Depth from Single Monocular Images, Ashutosh Saxena, Sung H. Chung, Andrew Y. Ng. In Neural Information Processing Systems (NIPS) 18, 2005. [PDF, Make3D project page, Google Tech Talk]
@inproceedings{saxena2005learningdepth,
title={Learning depth from single monocular images},
author={Saxena, A. and Chung, S.H. and Ng, A.},
booktitle={Neural Information Processing Systems 18},
year={2005},
}Abstract: We consider the task of depth estimation from a single monocular image. We take a supervised learning approach to this problem, in which we begin by collecting a training set of monocular images (of unstructured outdoor environments which include forests, trees, buildings, etc.) and their corresponding ground-truth depthmaps. Then, we apply supervised learning to predict the depthmap as a function of the image. Depth estimation is a challenging problem, since local features alone are insufficient to estimate depth at a point, and one needs to consider the global context of the image. Our model uses a discriminatively-trained Markov Random Field (MRF) that incorporates multiscale local- and global-image features, and models both depths at individual points as well as the relation between depths at different points. We show that, even on unstructured scenes, our algorithm is frequently able to recover fairly accurate depthmaps.
-
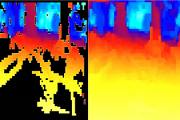
Depth Estimation using Monocular and Stereo Cues, Ashutosh Saxena, Jamie Schulte, Andrew Y. Ng. In 20th International Joint Conference on Artificial Intelligence (IJCAI), 2007. [PDF]
@inproceedings{saxena2007_stereo,
title={Depth Estimation using Monocular and Stereo Cues},
author={Saxena, A. and Schulte, J. and Ng, A.Y.},
journal={IJCAI},
year={2007},
}Abstract: Depth estimation in computer vision and robotics is most commonly done via stereo vision (stereopsis), in which images from two cameras are used to triangulate and estimate distances. However, there are also numerous monocular visual cues--such as texture variations and gradients, defocus, color/haze, etc.--that have heretofore been little exploited in such systems. Some of these cues apply even in regions without texture, where stereo would work poorly. In this paper, we apply a Markov Random Field (MRF) learning algorithm to capture some of these monocular cues, and incorporate them into a stereo system. We show that by adding monocular cues to stereo (triangulation) ones, we obtain significantly more accurate depth estimates than is possible using either monocular or stereo cues alone. This holds true for a large variety of environments, including both indoor environments and unstructured outdoor environments containing trees/forests, buildings, etc. Our approach is general, and applies to incorporating monocular cues together with any off-the-shelf stereo system.
-

3-D Depth Reconstruction from a Single Still Image, Ashutosh Saxena, Sung H. Chung, Andrew Y. Ng. International Journal of Computer Vision (IJCV), vol. 76, no. 1, pp 53-69, Jan 2008. (Online first: Aug 2007). [PDF, project page]
@article{saxena20083Ddepth,
title={3-d depth reconstruction from a single still image},
author={Saxena, A. and Chung, S.H. and Ng, A.Y.},
journal={International Journal of Computer Vision},
volume={76},
number={1},
pages={53--69},
year={2008},
publisher={Springer}
}Abstract: We consider the task of 3-d depth estimation from a single still image. We take a supervised learning approach to this problem, in which we begin by collecting a training set of monocular images (of unstructured indoor and outdoor environments which include forests, sidewalks, trees, buildings, etc.) and their corresponding ground-truth depthmaps. Then, we apply supervised learning to predict the value of the depthmap as a function of the image. Depth estimation is a challenging problem, since local features alone are insufficient to estimate depth at a point, and one needs to consider the global context of the image. Our model uses a hierarchical, multiscale Markov Random Field (MRF) that incorporates multiscale local- and global-image features, and models the depths and the relation between depths at different points in the image. We show that, even on unstructured scenes, our algorithm is frequently able to recover fairly accurate depthmaps. We further propose a model that incorporates both monocular cues and stereo (triangulation) cues, to obtain significantly more accurate depth estimates than is possible using either monocular or stereo cues alone.
-

3-D Reconstruction from Sparse Views using Monocular Vision, Ashutosh Saxena, Min Sun, Andrew Y. Ng. In ICCV workshop on Virtual Representations and Modeling of Large-scale environments (VRML), 2007. [ps, PDF]
@inproceedings{saxena2007make3d,
title={3-D Reconstruction from Sparse Views using Monocular Vision},
author={Saxena, A. and Sun, M. and Ng, A.Y.},
booktitle={ICCV workshop on VRML},
year={2007},
}Abstract: We consider the task of creating a 3-d model of a large novel environment, given only a small number of images of the scene. This is a difficult problem, because if the images are taken from very different viewpoints or if they contain similar-looking structures, then most geometric reconstruction methods will have great difficulty finding good correspondences. Further, the reconstructions given by most algorithms include only points in 3-d that were observed in two or more images; a point observed only in a single image would not be reconstructed. In this paper, we show how monocular image cues can be combined with triangulation cues to build a photo-realistic model of a scene given only a few images—even ones taken from very different viewpoints or with little overlap. Our approach begins by oversegmenting each image into small patches (superpixels). It then simultaneously tries to infer the 3-d position and orientation of every superpixel in every image. This is done using a Markov Random Field (MRF) which simultaneously reasons about monocular cues and about the relations between multiple image patches, both within the same image and across different images (triangulation cues). MAP inference in our model is efficiently approximated using a series of linear programs, and our algorithm scales well to a large number of images.
-

Learning 3-D Scene Structure from a Single Still Image, Ashutosh Saxena, Min Sun, Andrew Y. Ng. In ICCV workshop on 3D Representation for Recognition (3dRR-07), 2007. (best paper award) [ps, PDF, Make3d]
@inproceedings{saxena2007make3d,
title={Learning 3-D scene structure from a single still image},
author={Saxena, A. and Sun, M. and Ng, A.Y.},
booktitle={ICCV workshop on 3dRR},
year={2007},
}Abstract: We consider the problem of estimating detailed 3-d structure from a single still image of an unstructured environment. Our goal is to create 3-d models which are both quantitatively accurate as well as visually pleasing. For each small homogeneous patch in the image, we use a Markov Random Field (MRF) to infer a set of "plane parameters" that capture both the 3-d location and 3-d orientation of the patch. The MRF, trained via supervised learning, models both image depth cues as well as the relationships between different parts of the image. Inference in our model is tractable, and requires only solving a convex optimization problem. Other than assuming that the environment is made up of a number of small planes, our model makes no explicit assumptions about the structure of the scene; this enables the algorithm to capture much more detailed 3-d structure than does prior art (such as Saxena et al., 2005, Delage et al., 2005, and Hoiem et el., 2005), and also give a much richer experience in the 3-d flythroughs created using image-based rendering, even for scenes with significant non-vertical structure. Using this approach, we have created qualitatively correct 3-d models for 64.9% of 588 images downloaded from the internet, as compared to Hoiem et al.’s performance of 33.1%. Further, our models are quantitatively more accurate than either Saxena et al. or Hoiem et al.
-
High Speed Obstacle Avoidance using Monocular Vision and Reinforcement Learning, Jeff Michels, Ashutosh Saxena, Andrew Y. Ng. In 22nd Int'l Conf on Machine Learning (ICML), 2005. [PDF, PPT, project page, aerial vehicles]
@inproceedings{michels2005obstacleavoidance,
title={High speed obstacle avoidance using monocular vision and reinforcement learning},
author={Michels, J. and Saxena, A. and Ng, A.Y.},
booktitle={Proceedings of the 22nd international conference on Machine learning},
pages={593--600}, year={2005},
organization={ACM}
}Abstract: We consider the task of driving a remote control car at high speeds through unstructured outdoor environments. We present an approach in which supervised learning is first used to estimate depths from single monocular images. The learning algorithm can be trained either on real camera images labeled with ground-truth distances to the closest obstacles, or on a training set consisting of synthetic graphics images. The resulting algorithm is able to learn monocular vision cues that accurately estimate the relative depths of obstacles in a scene. Reinforcement learning/policy search is then applied within a simulator that renders synthetic scenes. This learns a control policy that selects a steering direction as a function of the vision system's output. We present results evaluating the predictive ability of the algorithm both on held out test data, and in actual autonomous driving experiments.
-
Make3D: Depth Perception from a Single Still Image, Ashutosh Saxena, Min Sun, Andrew Y. Ng. In AAAI, 2008. (Nectar Track) [PDF]
@inproceedings{saxena_aaai09_depth,
title={Make3D: Depth Perception from a Single Still Image},
author={Ashutosh Saxena and Min Sun and Andrew Y. Ng.},
booktitle={AAAI},
year={2008}
}Abstract: Humans have an amazing ability to perceive depth from a single still image; however, it remains a challenging problem for current computer vision systems. In this paper, we will present algorithms for estimating depth from a single still image. There are numerous monocular cues--such as texture variations and gradients, defocus, color/haze, etc.--that can be used for depth perception. Taking a supervised learning approach to this problem, in which we begin by collecting a training set of single images and their corresponding groundtruth depths, we learn the mapping from image features to the depths. We then apply these ideas to create 3-d models that are visually-pleasing as well as quantitatively accurate from individual images. We also discuss applications of our depth perception algorithm in robotic navigation, in improving the performance of stereovision, and in creating large-scale 3-d models given only a small number of images.
-
Make3D: Learning 3D Scene Structure from a Single Still Image, Ashutosh Saxena, Min Sun, Andrew Y. Ng. IEEE Transactions of Pattern Analysis and Machine Intelligence (PAMI), vol. 30, no. 5, pp 824-840, 2009. [PDF, Make3d project page, Google Tech Talk] (Original version received best paper award at ICCV 3dRR in 2007.)
@article{saxena2009make3d,
title={Make3d: Learning 3d scene structure from a single still image},
author={Saxena, A. and Sun, M. and Ng, A.Y.},
journal={Pattern Analysis and Machine Intelligence, IEEE Transactions on},
volume={31},
number={5},
pages={824--840},
year={2009},
publisher={IEEE}
}Abstract: We consider the problem of estimating detailed 3-d structure from a single still image of an unstructured environment. Our goal is to create 3-d models which are both quantitatively accurate as well as visually pleasing. For each small homogeneous patch in the image, we use a Markov Random Field (MRF) to infer a set of "plane parameters" that capture both the 3-d location and 3-d orientation of the patch. The MRF, trained via supervised learning, models both image depth cues as well as the relationships between different parts of the image. Other than assuming that the environment is made up of a number of small planes, our model makes no explicit assumptions about the structure of the scene; this enables the algorithm to capture much more detailed 3-d structure than does prior art, and also give a much richer experience in the 3-d flythroughs created using image-based rendering, even for scenes with significant non-vertical structure. Using this approach, we have created qualitatively correct 3-d models for 64.9% of 588 images downloaded from the internet. We have also extended our model to produce large scale 3d models from a few images.
-

i23 - Rapid Interactive 3D Reconstruction from a Single Image, Savil Srivastava, Ashutosh Saxena, Christian Theobalt, Sebastian Thrun, Andrew Y. Ng. In Vision, Modelling and Visualization (VMV), 2009. [PDF]
@inproceedings{i23_vmv09,
title={i23 - Rapid Interactive 3D Reconstruction from a Single Image},
author={Savil Srivastava and Ashutosh Saxena and Christian Theobalt and Sebastian Thrun and Andrew Y. Ng.},
booktitle={VMV},
year={2009}
}Abstract: We present i23, an algorithm to reconstruct a 3D model from a single image taken with a normal photo camera. It is based off an automatic machine learning approach that casts 3D reconstruction as a probabilistic inference problem using a Markov Random Field trained on ground truth data. Since it is difficult to learn the statistical relations for all possible images, the quality of the automatic reconstruction is sometimes unsatisfying. We therefore designed an intuitive interface for a user to sketch, in a few seconds, additional hints to the algorithm. We have developed a way to incorporate these constraints into the probabilistic reconstruction framework in order to obtain 3D reconstructions of much higher quality than previous fully-automatic methods. Our system also represents an exciting new computational photography tool, enabling new ways of rendering and editing photos.
-

Cascaded Classification Models: Combining Models for Holistic Scene Understanding, Geremy Heitz, Stephen Gould, Ashutosh Saxena, Daphne Koller. In Neural Information Processing Systems (NIPS), 2008. (oral) [PDF, project page]
@inproceedings{heitz2008cascaded,
title={Cascaded classification models: Combining models for holistic scene understanding},
author={Heitz, G. and Gould, S. and Saxena, A. and Koller, D.},
booktitle={Neural Information Processing Systems},
year={2008}
}Abstract: One of the original goals of computer vision was to fully understand a natural scene. This requires solving several sub-problems simultaneously, including object detection, region labeling, and geometric reasoning. The last few decades have seen great progress in tackling each of these problems in isolation. Only recently have researchers returned to the difficult task of considering them jointly. In this work, we consider learning a set of related models in such that they both solve their own problem and help each other. We develop a framework called Cascaded Classification Models (CCM), where repeated instantiations of these classifiers are coupled by their input/output variables in a cascade that improves performance at each level. Our method requires only a limited "black box" interface with the models, allowing us to use very sophisticated, state-of-the-art classifiers without having to look under the hood. We demonstrate the effectiveness of our method on a large set of natural images by combining the subtasks of scene categorization, object detection, multiclass image segmentation, and 3d reconstruction.
-

Autonomous Indoor Helicopter Flight using a Single Onboard Camera, Sai Prasanth Soundararaj, Arvind Sujeeth, Ashutosh Saxena. In International Conference on Intelligent RObots and Systems (IROS), 2009. [PDF]
@inproceedings{soundararajsaxena-door-iros2009,
title={Autonomous Indoor Helicopter Flight using a Single Onboard Camera},
author={Soundararaj, S.P. and Sujeeth, A. and Saxena, A.},
booktitle={IROS},
year={2009}
}Abstract: We consider the problem of autonomously flying a helicopter in indoor environments. Navigation in indoor settings poses two major challenges. First, real-time perception and response is crucial because of the high presence of obstacles. Second, the limited free space in such a setting places severe restrictions on the size of the aerial vehicle, resulting in a frugal payload budget.
We autonomously fly a miniature RC helicopter in small known environments using an on-board light-weight camera as the only sensor. We use an algorithm that combines data-driven image classification with optical flow techniques on the images captured by the camera to achieve real-time 3D localization and navigation. We perform successful autonomous test flights along trajectories in two different indoor settings. Our results demonstrate that our method is capable of autonomous flight even in narrow indoor spaces with sharp corners.
-
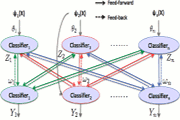
Towards Holistic Scene Understanding: Feedback Enabled Cascaded Classification Models, Congcong Li, Adarsh Kowdle, Ashutosh Saxena, Tsuhan Chen. In Neural Information Processing Systems (NIPS), 2010. [PDF, More]
Also see: A Generic Model to Compose Vision Modules for Holistic Scene Understanding, Adarsh Kowdle, Congcong Li, Ashutosh Saxena and Tsuhan Chen. In European Conference on Computer Vision Workshop on Parts and Attributes (ECCV '10), 2010. [PDF, slides, More] FeCCM for Scene Understanding: Helping the Robot to Learn Multiple Tasks, Congcong Li, TP Wong, Norris Xu, Ashutosh Saxena. Video contribution in ICRA, 2011. [PDF, mp4, youtube, More]
@inproceedings{li2010feccm,
title={Towards holistic scene understanding: Feedback enabled cascaded classification models},
author={Li, C. and Kowdle, A. and Saxena, A. and Chen, T.},
booktitle={Neural Information Processing Systems (NIPS)},
year={2010}
}Abstract: In many machine learning domains (such as scene understanding), several related sub-tasks (such as scene categorization, depth estimation, object detection) operate on the same raw data and provide correlated outputs. Each of these tasks is often notoriously hard, and state-of-the-art classifiers already exist for many sub-tasks. It is desirable to have an algorithm that can capture such correlation without requiring to make any changes to the inner workings of any classifier.
We propose Feedback Enabled Cascaded Classification Models (FE-CCM), that maximizes the joint likelihood of the sub-tasks, while requiring only a 'black-box' interface to the original classifier for each sub-task. We use a two-layer cascade of classifiers, which are repeated instantiations of the original ones, with the output of the first layer fed into the second layer as input. Our training method involves a feedback step that allows later classifiers to provide earlier classifiers information about what error modes to focus on. We show that our method significantly improves performance in all the sub-tasks in two different domains: (i) scene understanding, where we consider depth estimation, scene categorization, event categorization, object detection, geometric labeling and saliency detection, and (ii) robotic grasping, where we consider grasp point detection and object classification.
-

Autonomous MAV Flight in Indoor Environments using Single Image Perspective Cues, Cooper Bills, Joyce Chen, Ashutosh Saxena. In International Conference on Robotics and Automation (ICRA), 2011. [PDF, More]
@inproceedings{bills2011_indoorsingleimage,
title={Autonomous MAV Flight in Indoor Environments using Single Image Perspective Cues},
author={Cooper Bills and Joyce Chen and Ashutosh Saxena},
year={2011},
booktitle={ICRA}
}Abstract: We consider the problem of autonomously flying Miniature Aerial Vehicles (MAVs) in indoor environments such as home and office buildings. The primary long range sensor in these MAVs is a miniature camera. While previous approaches first try to build a 3D model in order to do planning and control, our method neither attempts to build nor requires a 3D model. Instead, our method first classifies the type of indoor environment the MAV is in, and then uses vision algorithms based on perspective cues to estimate the desired direction to fly. We test our method on two MAV platforms: a co-axial miniature helicopter and a toy quadrotor. Our experiments show that our vision algorithms are quite reliable, and they enable our MAVs to fly in a variety of corridors and staircases.
-
Towards Holistic Scene Understanding: Feedback Enabled Cascaded Classification Models, Congcong Li, Adarsh Kowdle, Ashutosh Saxena, Tsuhan Chen. IEEE Trans Pattern Analysis and Machine Intelligence (PAMI), 34(7):1394-1408, July 2012. (Online first: Oct 2011.) [PDF, IEEE link, project page]
(Original paper appeared in Neural Information Processing Systems (NIPS), 2010. [PDF])
@article{li2011feccm,
title={Towards holistic scene understanding: Feedback enabled cascaded classification models},
author={Li, C. and Kowdle, A. and Saxena, A. and Chen, T.},
journal={Pattern Analysis and Machine Intelligence, IEEE Transactions on},
volume={34},
number={7},
pages={1394-1408},
year={2012}
}Abstract: Scene understanding includes many related sub-tasks, such as scene categorization, depth estimation, object detection, etc. Each of these sub-tasks is often notoriously hard, and state-of-the-art classifiers already exist for many of them. These classifiers operate on the same raw image and provide correlated outputs. It is desirable to have an algorithm that can capture such correlation without requiring any changes to the inner workings of any classifier. We propose Feedback Enabled Cascaded Classification Models (FE-CCM), that jointly optimizes all the sub-tasks, while requiring only a 'black-box' interface to the original classifier for each sub-task. We use a two-layer cascade of classifiers, which are repeated instantiations of the original ones, with the output of the first layer fed into the second layer as input. Our training method involves a feedback step that allows later classifiers to provide earlier classifiers information about which error modes to focus on. We show that our method significantly improves performance in all the sub-tasks in the domain of scene understanding, where we consider depth estimation, scene categorization, event categorization, object detection, geometric labeling and saliency detection. Our method also improves performance in two robotic applications: an object-grasping robot and an object-finding robot.
-
Low-Power Parallel Algorithms for Single Image based Obstacle Avoidance in Aerial Robots, Ian Lenz, Mevlana Gemici, Ashutosh Saxena. In International Conference on Intelligent Robots and Systems (IROS), 2012. [PDF, more]
@inproceedings{lenz_lowpoweraerial_2012,
title={Low-Power Parallel Algorithms for Single Image based Obstacle Avoidance in Aerial Robots},
author={Ian Lenz and Mevlana Gemici and Ashutosh Saxena},
booktitle={International Conference on Intelligent Robots and Systems (IROS)},
year={2012}
}Abstract: For an aerial robot, perceiving and avoiding obstacles are necessary skills to function autonomously in a cluttered unknown environment. In this work, we use a single image captured from the onboard camera as input, produce obstacle classifications, and use them to select an evasive maneuver. We present a Markov Random Field based approach that models the obstacles as a function of visual features and non-local dependencies in neighboring regions of the image. We perform efficient inference using new low-power parallel neuromorphic hardware, where belief propagation updates are done using leaky integrate and fire neurons in parallel, while consuming less than 1 W of power. In outdoor robotic experiments, our algorithm was able to consistently produce clean, accurate obstacle maps which allowed our robot to avoid a wide variety of obstacles, including trees, poles and fences.
-

Learning the Right Model: Efficient Max-Margin Learning in Laplacian CRFs, Dhruv Batra, Ashutosh Saxena. In Computer Vision and Pattern Recognition (CVPR), 2012. [PDF, supplementary material]
(Applied to Make3D: learning depths from a single still image.)
@inproceedings{laplaciancrfs_cvpr2012,
title={Learning the Right Model: Efficient Max-Margin Learning in Laplacian CRFs},
author={Dhruv Batra and Ashutosh Saxena},
year={2012},
booktitle={CVPR}
}Abstract: An important modeling decision made while designing Conditional Random Fields (CRFs) is the choice of the potential functions over the cliques of variables. Laplacian potentials are useful because they are robust potentials and match image statistics better than Gaussians. Moreover, energies with Laplacian terms remain convex, which simplifies inference. This makes Laplacian potentials an ideal modeling choice for some applications. In this paper, we study max-margin parameter learning in CRFs with Laplacian potentials (LCRFs). We first show that structured hinge-loss is non-convex for LCRFs and thus techniques used by previous works are not applicable. We then present the first approximate max-margin algorithm for LCRFs. Finally, we make our learning algorithm scalable in the number of training images by using dual-decomposition techniques. Our experiments on singleimage depth estimation show that even with simple features, our approach achieves comparable to state-of-art results.