Publications
Filter by type:
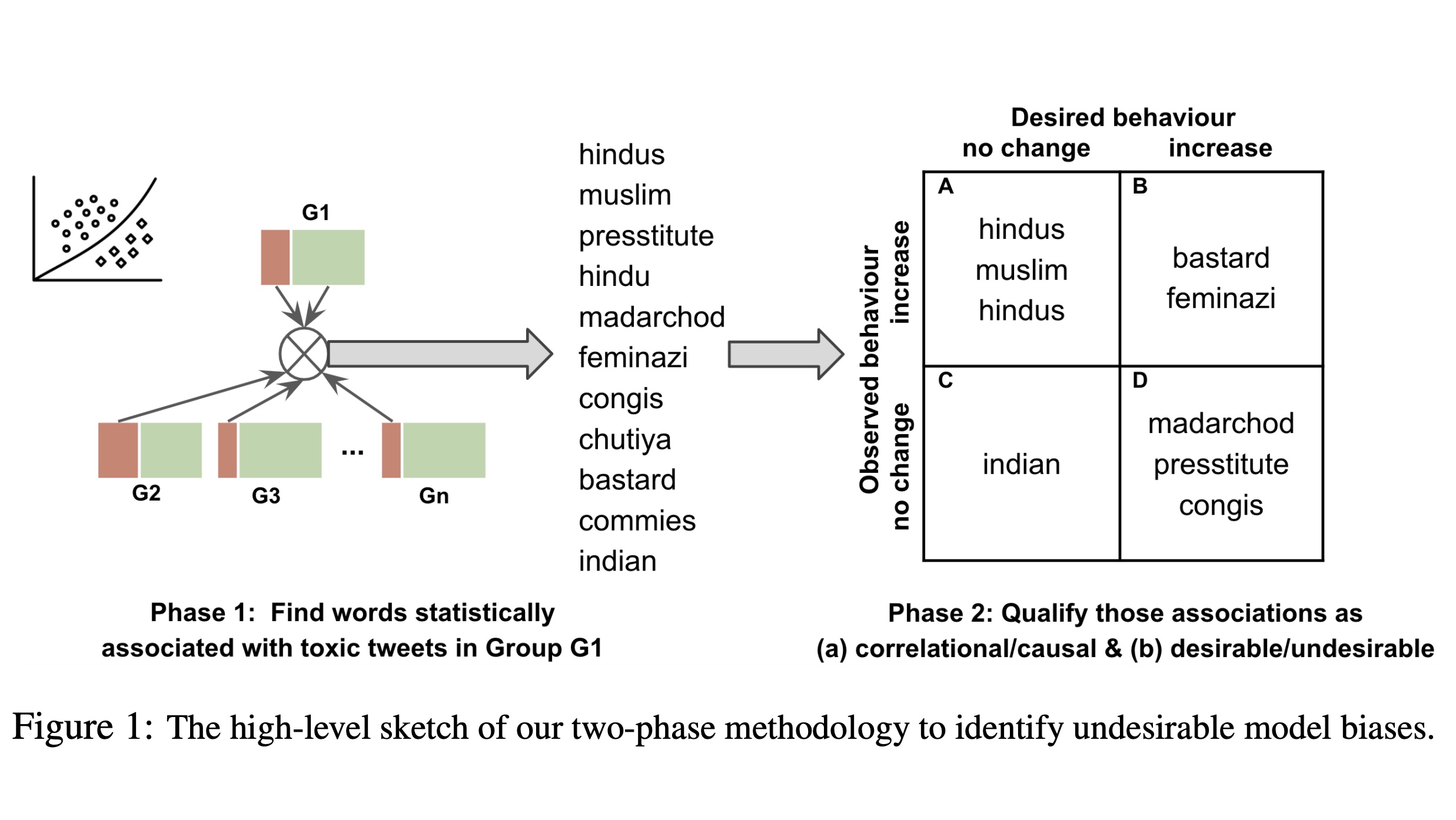 |
AbstractOnline social media platforms increasingly rely on Natural Language Processing (NLP) techniques to detect abusive content at scale in order to mitigate the harms it causes to their users. However, these techniques suffer from various sampling and association biases present in training data, often resulting in sub-par performance on content relevant to marginalized groups, potentially furthering disproportionate harms towards them. Studies on such biases so far have focused on only a handful of axes of disparities and subgroups that have annotations/lexicons available. Consequently, biases concerning non-Western contexts are largely ignored in the literature. In this paper, we introduce a weakly supervised method to robustly detect lexical biases in broader geocultural contexts. Through a case study on cross-geographic toxicity detection, we demonstrate that our method identifies salient groups of errors, and, in a follow up, demonstrate that these groupings reflect human judgments of offensive and inoffensive language in those geographic contexts. |
 |
How Metaphors Impact Political Discourse: A Large-Scale Topic-Agnostic Study Using Neural Metaphor Detection.Conference PaperInternational Conference on Web and Social Media (ICWSM '21).2021.
AbstractMetaphors are widely used in political rhetoric as an effective framing device. While the efficacy of specific metaphors such as the war metaphor in political discourse has been documented before, those studies often rely on small number of hand-coded instances of metaphor use. Larger-scale topic-agnostic studies are required to establish the general persuasiveness of metaphors as a device, and to shed light on the broader patterns that guide their persuasiveness. In this paper, we present a large-scale data-driven study of metaphors used in political discourse. We conduct this study on a publicly available dataset of over 85K posts made by 412 US politicians in their Facebook public pages, up until Feb 2017. Our contributions are threefold: we show evidence that metaphor use correlates with ideological leanings in complex ways that depend on concurrent political events such as winning or losing elections; we show that posts with metaphors elicit more engagement from their audience overall even after controlling for various socio-political factors such as gender and political party affiliation; and finally, we demonstrate that metaphoricity is indeed the reason for increased engagement of posts, through a fine-grained linguistic analysis of metaphorical vs. literal usages of 513 words across 70K posts. |
 |
Learning to Recognize Dialect Features.Conference PaperNorth American Chapter of Association for Computational Linguistics (NAACL '21).2021.
AbstractBuilding NLP systems that serve everyone requires accounting for dialect differences. But dialects are not monolithic entities: rather, distinctions between and within dialects are captured by the presence, absence, and frequency of dozens of dialect features in speech and text, such as the deletion of the copula in "He {} running". In this paper, we introduce the task of dialect feature detection, and present two multitask learning approaches, both based on pretrained transformers. For most dialects, large-scale annotated corpora for these features are unavailable, making it difficult to train recognizers. We train our models on a small number of minimal pairs, building on how linguists typically define dialect features. Evaluation on a test set of 22 dialect features of Indian English demonstrates that these models learn to recognize many features with high accuracy, and that a few minimal pairs can be as effective for training as thousands of labeled examples. We also demonstrate the downstream applicability of dialect feature detection both as a measure of dialect density and as a dialect classifier. |
 |
Re-imagining Algorithmic Fairness in India and Beyond.Conference PaperACM Conference on Fairness, Accountability, and Transparency (FAccT ’21).2021.
AbstractConventional algorithmic fairness is West-centric, as seen in its subgroups, values, and methods. In this paper, we de-center algorithmic fairness and analyse AI power in India. Based on 36 qualitative interviews and a discourse analysis of algorithmic deployments in India, we find that several assumptions of algorithmic fairness are challenged. We find that in India, data is not always reliable due to socio-economic factors, ML makers appear to follow double standards, and AI evokes unquestioning aspiration. We contend that localising model fairness alone can be window dressing in India, where the distance between models and oppressed communities is large. Instead, we re-imagine algorithmic fairness in India and provide a roadmap to re-contextualise data and models, empower oppressed communities, and enable Fair-ML ecosystems. |
 |
Non-portability of Algorithmic Fairness in India.Workshop Paper NeurIPS Workshop on Navigating the Broader Impacts of AI Research2020.
AbstractConventional algorithmic fairness is Western in its sub-groups, values, and optimizations. In this paper, we ask how portable the assumptions of this largely Western take on algorithmic fairness are to a different geo-cultural context such as India. Based on 36 expert interviews with Indian scholars, and an analysis of emerging algorithmic deployments in India, we identify three clusters of challenges that engulf the large distance between machine learning models and oppressed communities in India. We argue that a mere translation of technical fairness work to Indian subgroups may serve only as a window dressing, and instead, call for a collective re-imagining of Fair-ML, by re-contextualising data and models, empowering oppressed communities, and more importantly, enabling ecosystems. |
 |
Participatory Machine Learning Using Community-Based System Dynamics.Journal PaperHarvard Health and Human Rights Journal (Viewpoints)., 2020.
AbstractThe pervasive digitization of health data, aided with advancements in machine learning (ML) techniques, has triggered an exponential growth in the research and development of ML applications in health, especially in areas such as drug discovery, clinical diagnosis, and public health. A growing body of research has shown evidence that ML techniques, if unchecked, have the potential to propagate and amplify existing forms of discrimination in society, which may undermine people’s human rights to health and to be free from discrimination. We argue for a participatory approach that will enable ML-based interventions to address these risks early in the process and to safeguard the rights of the communities they will affect. |
 |
Online Abuse and Human Rights: WOAH Satellite Session at RightsCon 2020.Workshop Paper EMNLP Workshop on Online Abuse and Harms2020.
AbstractIn 2020 The Workshop on Online Abuse and Harms (WOAH) held a satellite panel at RightsCons 2020, an international human rights conference. Our aim was to bridge the gap between human rights scholarship and Natural Language Processing (NLP) research communities in tackling online abuse. We report on the discussions that took place, and present an analysis of four key issues which emerged: Problems in tackling online abuse, Solutions, Meta concerns and the Ecosystem of content moderation and research. We argue there is a pressing need for NLP research communities to engage with human rights perspectives, and identify four key ways in which NLP research into online abuse could immediately be enhanced to create better and more ethical solutions. |
 |
Extending the Machine Learning Abstraction Boundary: A Complex Systems Approach to Incorporate Societal Context.Preprint Arxiv. 2020.
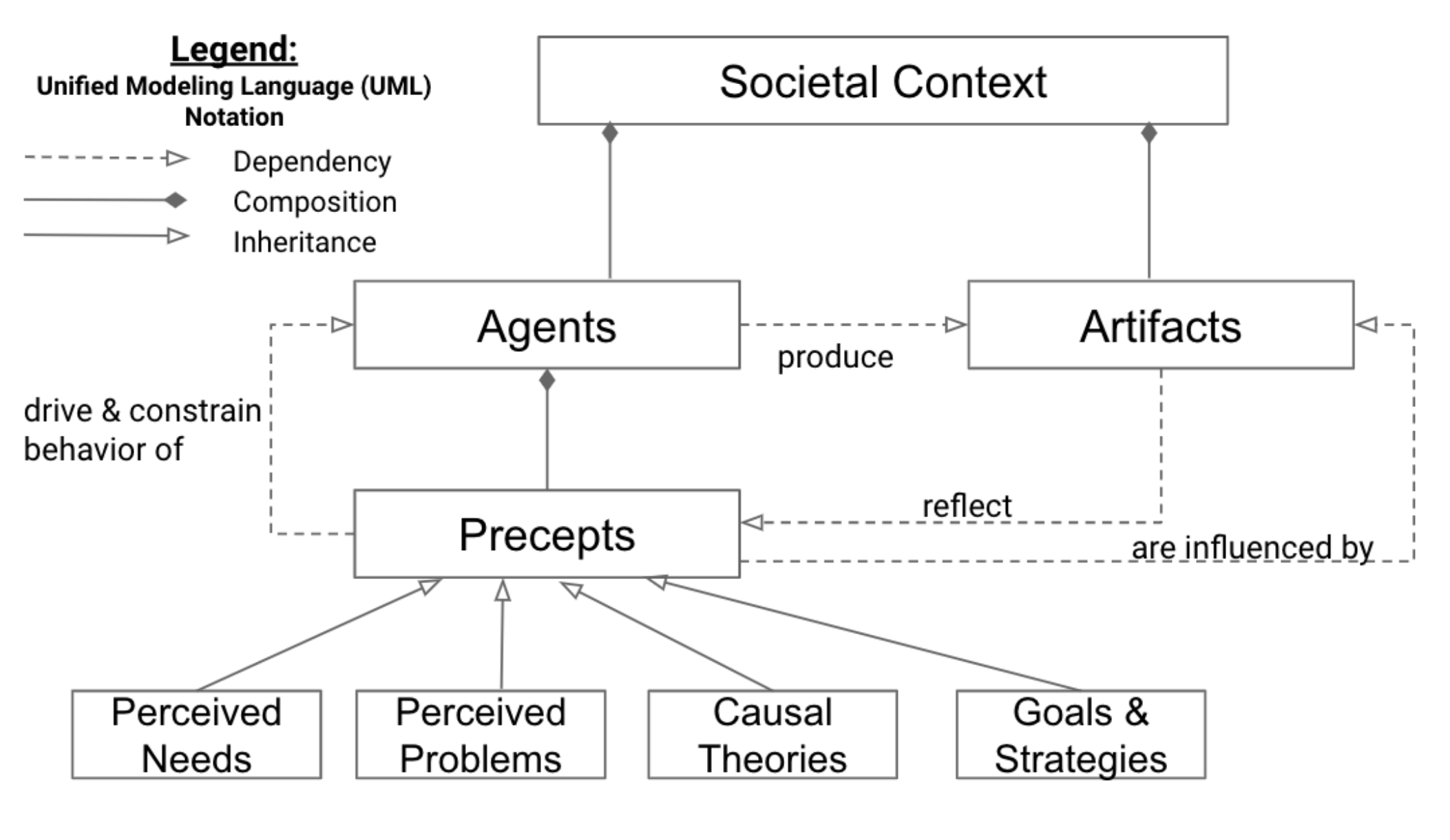
AbstractMachine learning (ML) fairness research tends to focus primarily on mathematically-based interventions on often opaque algorithms or models and/or their immediate inputs and outputs. Such oversimplified mathematical models abstract away the underlying societal context where ML models are conceived, developed, and ultimately deployed. As fairness itself is a socially constructed concept that originates from that societal context along with the model inputs and the models themselves, a lack of an in-depth understanding of societal context can easily undermine the pursuit of ML fairness. In this paper, we outline three new tools to improve the comprehension, identification and representation of societal context. First, we propose a complex adaptive systems (CAS) based model and definition of societal context that will help researchers and product developers to expand the abstraction boundary of ML fairness work to include societal context. Second, we introduce collaborative causal theory formation (CCTF) as a key capability for establishing a sociotechnical frame that incorporates diverse mental models and associated causal theories in modeling the problem and solution space for ML-based products. Finally, we identify community based system dynamics (CBSD) as a powerful, transparent and rigorous approach for practicing CCTF during all phases of the ML product development process. We conclude with a discussion of how these systems theoretic approaches to understand the societal context within which sociotechnical systems are embedded can improve the development of fair and inclusive ML-based products. |
 |
Social Biases in NLP Models as Barriers for Persons with Disabilities.Conference Paper Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL). July 2020. Seattle, USA.2020.
AbstractBuilding equitable and inclusive NLP technologies demands consideration of whether and how social attitudes are represented in ML models. In particular, representations encoded in models often inadvertently perpetuate undesirable social biases from the data on which they are trained. In this paper, we present evidence of such undesirable biases towards mentions of disability in two different English language models: toxicity prediction and sentiment analysis. Next, we demonstrate that the neural embeddings that are the critical first step in most NLP pipelines similarly contain undesirable biases towards mentions of disability. We end by highlighting topical biases in the discourse about disability which may contribute to the observed model biases; for instance, gun violence, homelessness, and drug addiction are over-represented in texts discussing mental illness. |
|
Participatory Problem Formulation for Fairer Machine Learning Through Community Based System Dynamics.Workshop Paper Fair & Responsible AI Workshop at CHI2020.
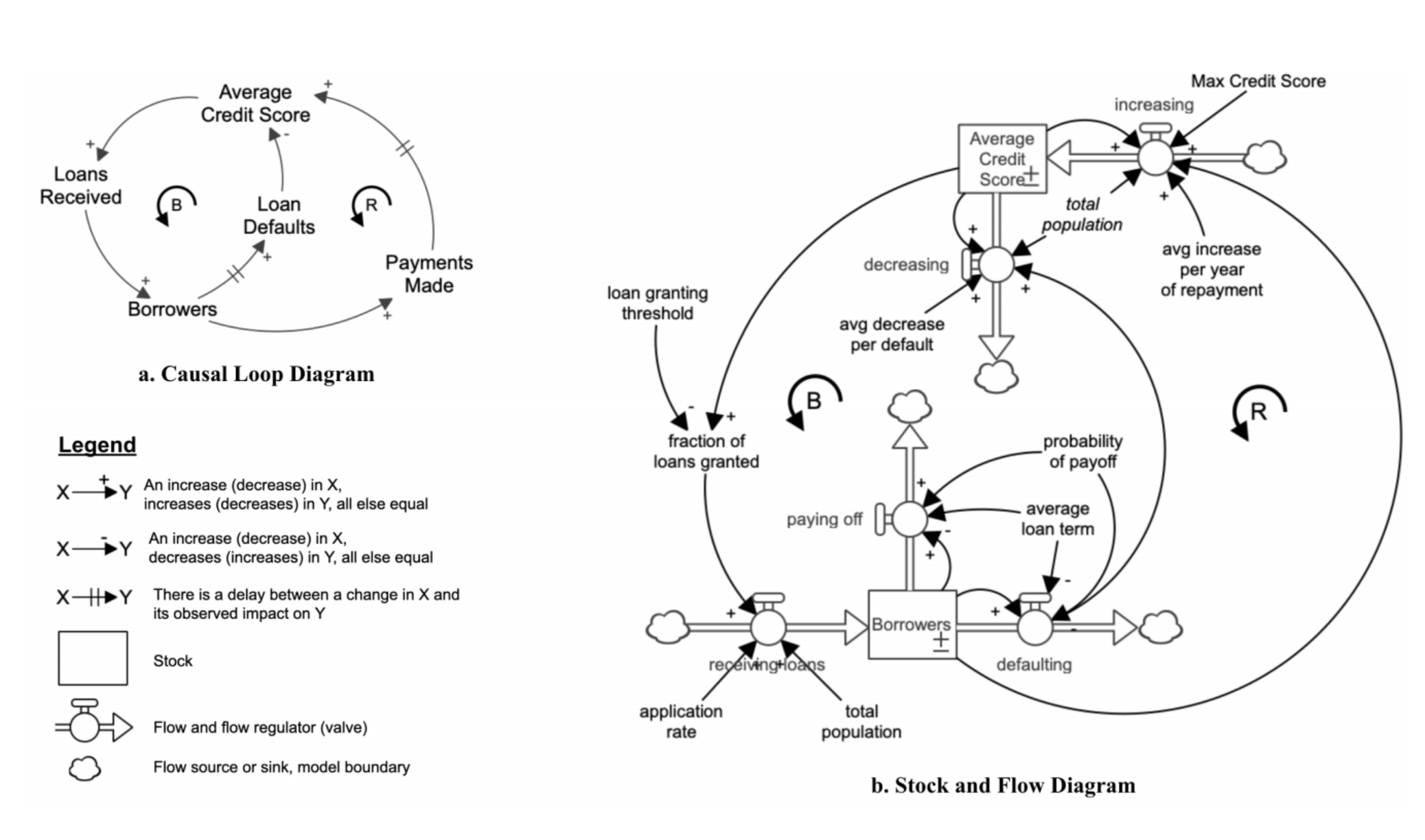
AbstractRecent research on algorithmic fairness has highlighted that the problem formulation phase of Machine Learning (ML) system development can be a key source of bias that has significant downstream impacts on ML system fairness outcomes. However, very little attention has been paid to methods for improving the fairness efficacy of this critical phase of ML system development. Current practice neither accounts for the dynamic complexity of high-stakes domains nor incorporates the perspectives of vulnerable stakeholders. In this paper we introduce community based system dynamics (CBSD) as a mature practice to enable the participation of typically excluded stakeholders in the problem formulation phase of the ML system development process and facilitate the deep problem understanding required to mitigate bias during this crucial stage. |
 |
Participatory Problem Formulation for Fairer Machine Learning Through Community Based System Dynamics Approach.Workshop Paper ICLR Workshop on Machine Learning in Real Life (ML-IRL)2020.
AbstractRecent research on algorithmic fairness has highlighted that the problem formulation phase of ML system development can be a key source of bias that has significant downstream impacts on ML system fairness outcomes. However, very little attention has been paid to methods for improving the fairness efficacy of this critical phase of ML system development. Current practice neither accounts for the dynamic complexity of high-stakes domains nor incorporates the perspectives of vulnerable stakeholders. In this paper we introduce community based system dynamics (CBSD) as a mature framework to enable the participation of typically excluded stakeholders in the problem formulation phase of the ML system development process and facilitate the deep problem understanding required to mitigate bias during this crucial stage. |
 |
Perturbation Sensitivity Analysis to Detect Unintended Model Biases.Conference Paper Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP)2019.
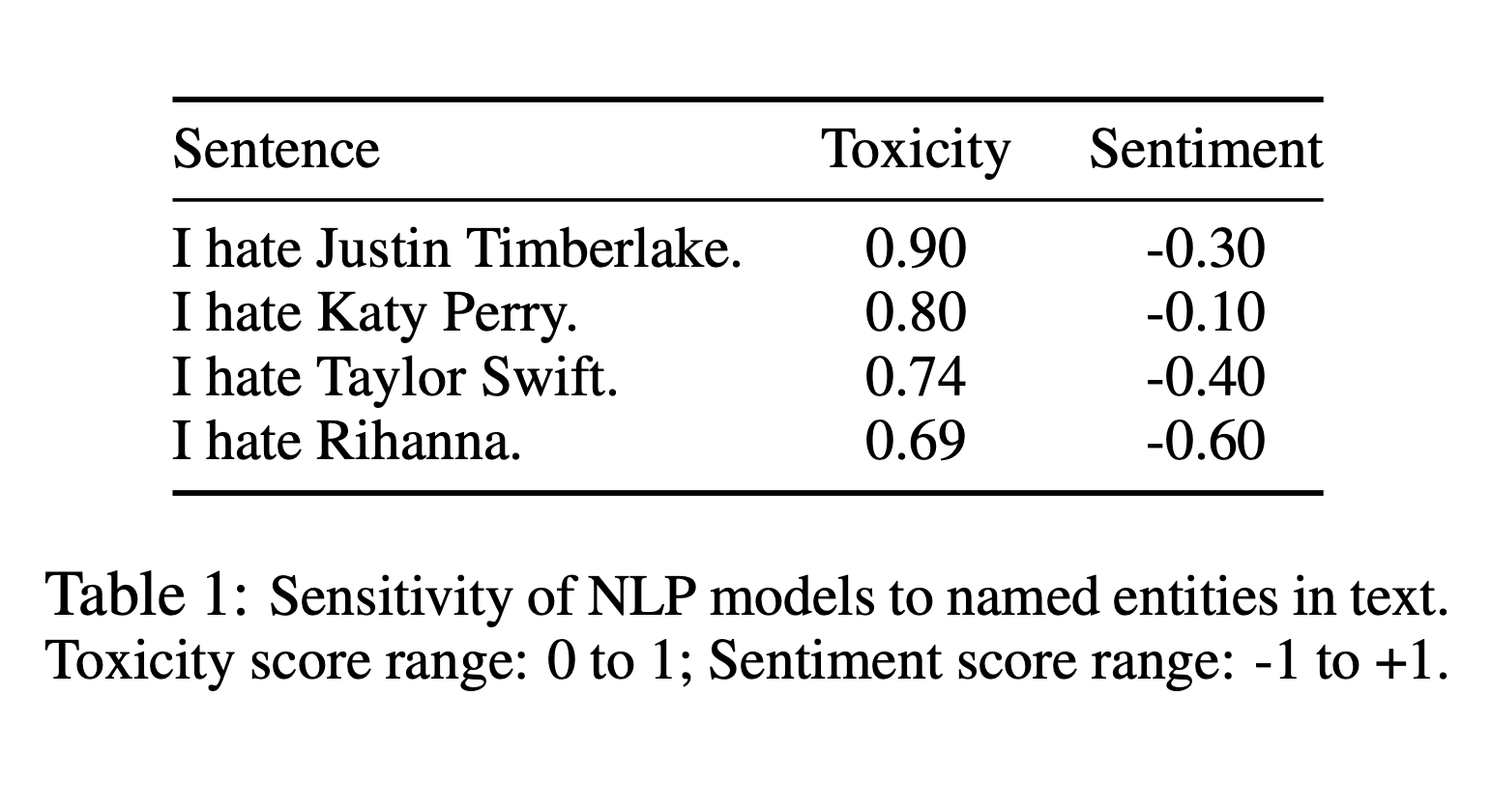
AbstractData-driven statistical Natural Language Processing (NLP) techniques leverage large amounts of language data to build models that can understand language. However, most language data reflect the public discourse at the time the data was produced, and hence NLP models are susceptible to learning incidental associations around named referents at a particular point in time, in addition to general linguistic meaning. An NLP system designed to model notions such as sentiment and toxicity should ideally produce scores that are independent of the identity of such entities mentioned in text and their social associations. For example, in a general purpose sentiment analysis system, a phrase such as I hate Katy Perry should be interpreted as having the same sentiment as I hate Taylor Swift. Based on this idea, we propose a generic evaluation framework, Perturbation Sensitivity Analysis, which detects unintended model biases related to named entities, and requires no new annotations or corpora. We demonstrate the utility of this analysis by employing it on two different NLP models---a sentiment model and a toxicity model---applied on online comments in English language from four different genres. |
 |
Unintended Machine Learning Biases as Social Barriers for Persons with Disabilities.Workshop Paper ASSETS Workshop on AI Fairness for People with Disabilities, 2019.
AbstractPersons with disabilities face many barriers to participation in society, and the rapid advancement of technology creates ever more. Achieving fair opportunity and justice for people with disabilities demands paying attention not just to accessibility, but also to the attitudes towards, and representations of, disability that are implicit in machine learning (ML) models that are pervasive in how one engages with the society. However such models often inadvertently learn to perpetuate undesirable social biases from the data on which they are trained. This can result, for example, in models for classifying text producing very different predictions for I stand by a person with mental illness, and I stand by a tall person. We present evidence of such social biases in existing ML models, along with an analysis of biases in a dataset used for model development. |
 |
Power Networks: A Novel Neural Architecture to Predict Power Relations.Workshop Paper Proceedings of the SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL), 2018.
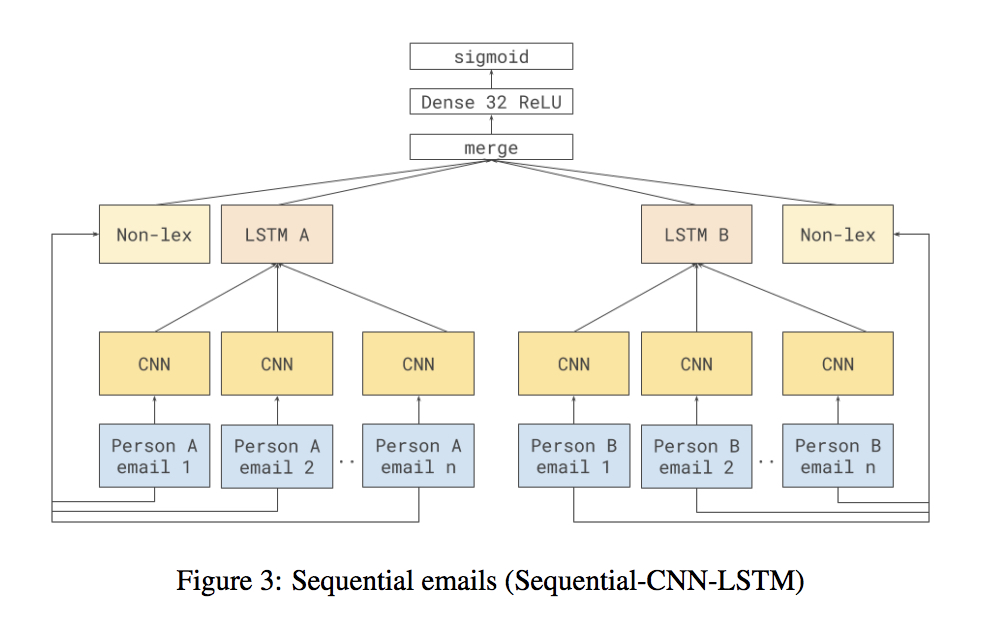
AbstractCan language analysis reveal the underlying social power relations that exist between participants of an interaction? Prior work within NLP has shown promise in this area, but the performance of automatically predicting power relations using NLP analysis of social interactions remains wanting. In this paper, we present a novel neural architecture that captures manifestations of power within individual emails which are then aggregated in an order-preserving way in order to infer the direction of power between pairs of participants in an email thread. We obtain an accuracy of 80.4%, a 10.1% improvement over state-of-the-art methods, in this task. We further apply our model to the task of predicting power relations between individuals based on the entire set of messages exchanged between them; here also, our model significantly outperforms the70. 0% accuracy using prior state-of-the-art techniques, obtaining an accuracy of 83.0%. |
 |
Author Commitment and Social Power: Automatic Belief Tagging to Infer the Social Context of Interactions.Conference Paper Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2018.
AbstractUnderstanding how social power structures affect the way we interact with one another is of great interest to social scientists who want to answer fundamental questions about human behavior, as well as to computer scientists who want to build automatic methods to infer the social contexts of interactions. In this paper, we employ advancements in extrapropositional semantics extraction within NLP to study how author commitment reflects the social context of an interactions. Specifically, we investigate whether the level of commitment expressed by individuals in an organizational interaction reflects the hierarchical power structures they are part of. We find that subordinates use significantly more instances of non-commitment than superiors. More importantly, we also find that subordinates attribute propositions to other agents more often than superiors do — an aspect that has not been studied before. Finally, we show that enriching lexical features with commitment labels captures important distinctions in social meanings. |
 |
Detecting Institutional Dialog Acts in Police Traffic Stops.Journal PaperTransactions of Association for Computational Linguistics (TACL), 2018.
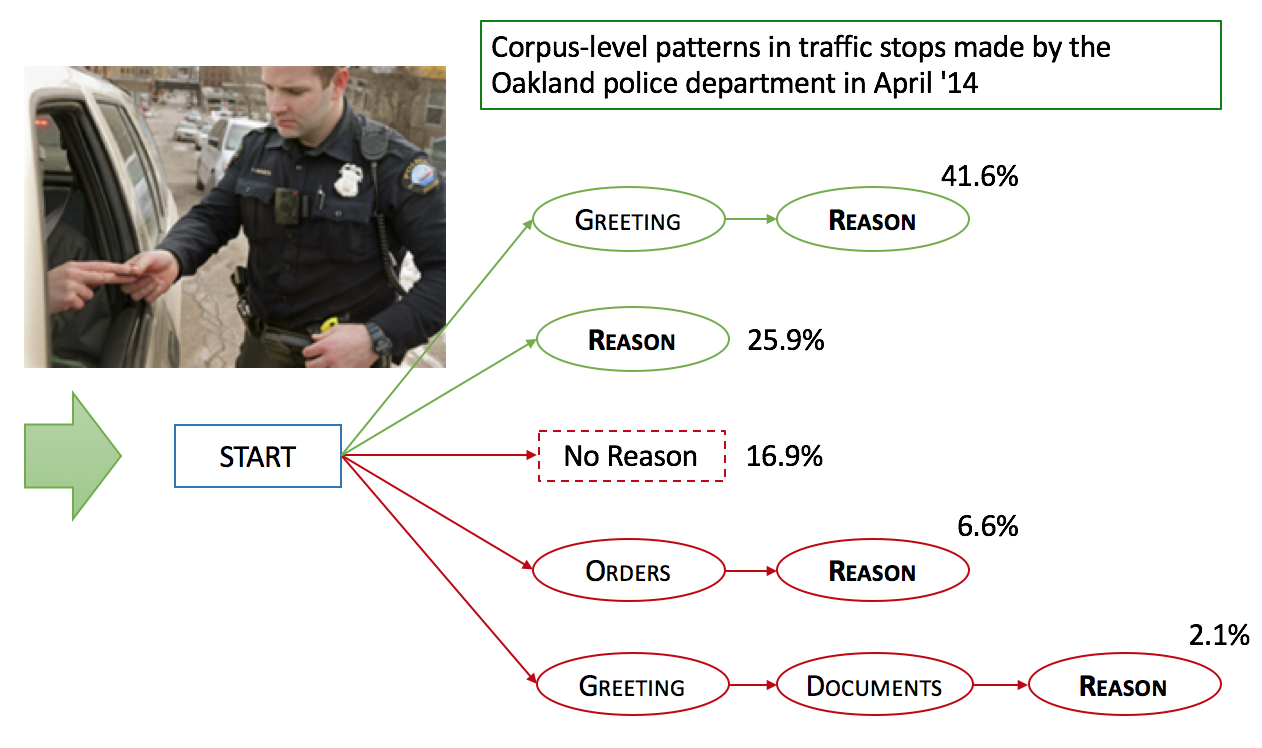
AbstractWe apply computational dialog methods on police body-worn camera footage to model conversations between police officers and community members in traffic stops. Relying on the theory of institutional talk, we develop a labeling scheme for police talk in traffic stops, and a tagger to detect institutional dialog acts (Reasons, Searches, Offering Help) from transcribed text at the turn (78% F-score) and stop (89% F-score) level. We then develop speech recognition and segmentation algorithms to detect these acts at the stop level from raw camera audio (81% F-score, with even higher accuracy for crucial acts like the stop Reason). We demonstrate that the dialog structures produced by our tagger could reveal whether officers follow law enforcement norms like introducing themselves, explaining the reason for the stop, and asking permission for searches, making our work an important step in improving police-community relations. |
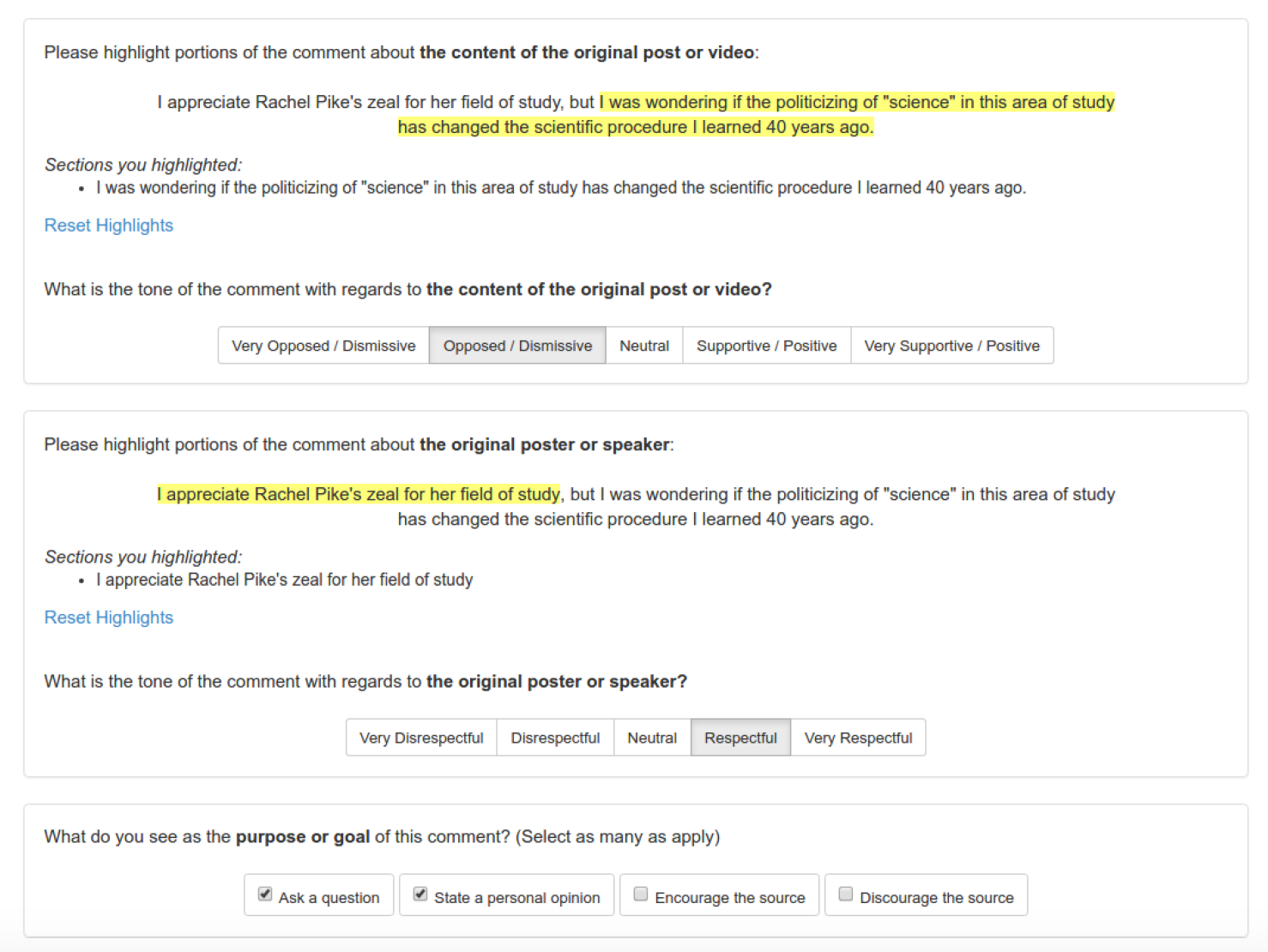 |
RtGender: A Corpus of Responses to Gender for Studying Gender Bias.Conference Paper In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC), May 2018, Miyazaki, Japan. (accepted for publication)
AbstractGender bias often manifests in the language people use to respond to others of a specific gender. However, prior computational work has largely focused on communications about gender, rather than messages to people of that gender, in part due to lack of data. Here, we fill a critical need by introducing a multi-genre dataset of over 27M comments from four socially and topically diverse sources tagged for the gender of the addressee. Using our dataset, we describe pilot studies on how gender bias can be measured and analyzed and we highlight our ongoing effort to annotate the data for different aspects of bias. Our dataset has the potential not just for studying bias but for improving downstream applications in dialogue systems, gender detection or obfuscation, and debiasing language generation. |
 |
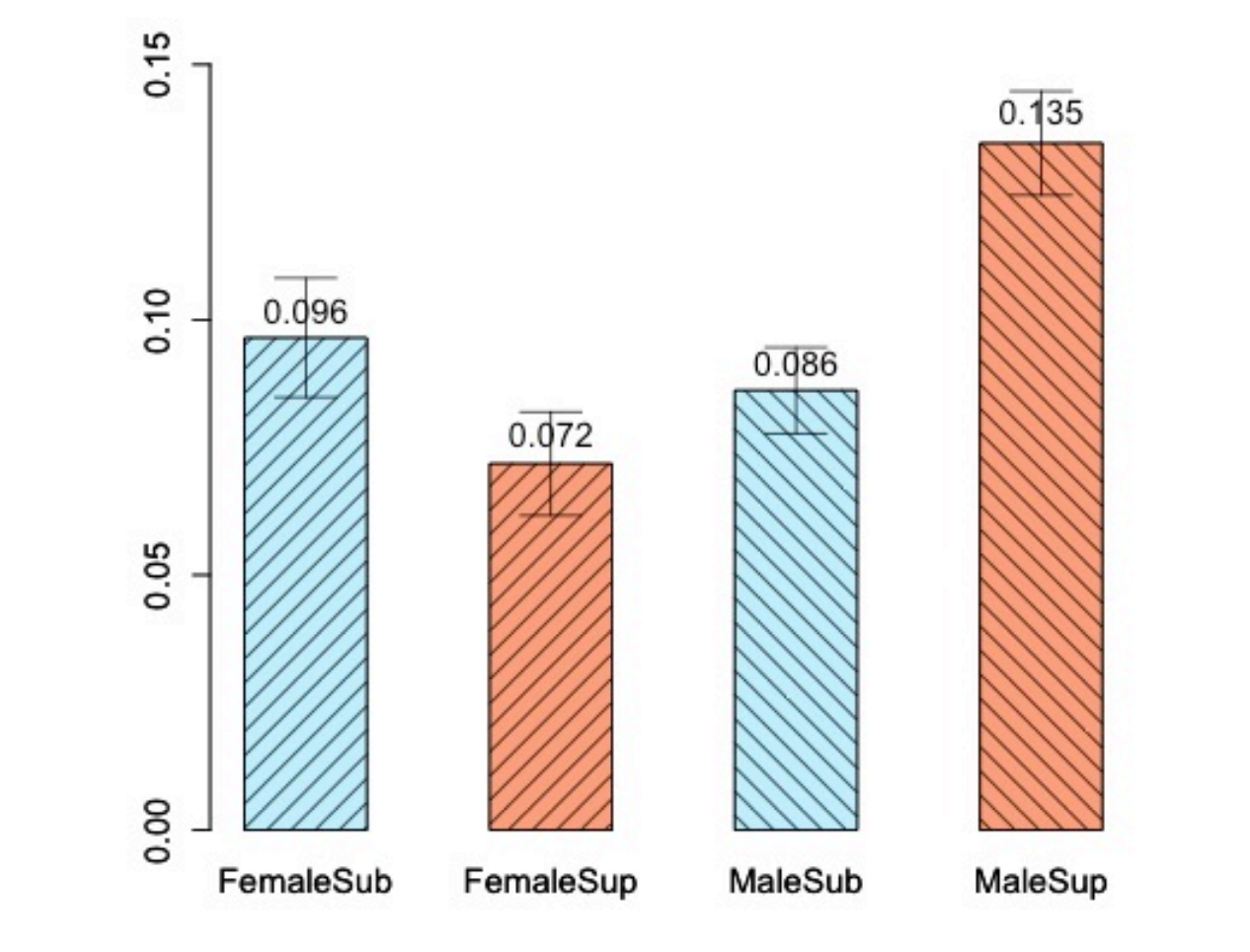
Body Camera Footage Captures Racial Disparities in Officer Respect.Journal Paper Proceedings of the National Academy of Sciences, Volume 114, Number 25, June 2017, Pages 6521-6526
AbstractUsing footage from body-worn cameras, we analyze the respectfulness of police officer language toward white and black community members during routine traffic stops. We develop computational linguistic methods that extract levels of respect automatically from transcripts, informed by a thin-slicing study of participant ratings of officer utterances. We find that officers speak with consistently less respect toward black versus white community members, even after controlling for the race of the officer, the severity of the infraction, the location of the stop, and the outcome of the stop. Such disparities in common, everyday interactions between police and the communities they serve have important implications for procedural justice and the building of police–community trust. |
 |
Dialog Structure Through the Lens of Gender, Gender Environment, and Power.Journal PaperJournal on Dialogue & Discourse, Volume 8, Number 2, May 2017, Pages 21-55
AbstractUnderstanding how the social context of an interaction affects our dialog behavior is of great interest to social scientists who study human behavior, as well as to computer scientists who build automatic methods to infer those social contexts. In this paper, we study the interaction of power, gender, and dialog behavior in organizational interactions. In order to perform this study, we first construct the Gender Identified Enron Corpus of emails, in which we semi-automatically assign the gender of around 23,000 individuals who authored around 97,000 email messages in the Enron corpus. This corpus, which is made freely available, is orders of magnitude larger than previously existing gender identified corpora in the email domain. Next, we use this corpus to perform a largescale data-oriented study of the interplay of gender and manifestations of power. We argue that, in addition to one’s own gender, the “gender environment” of an interaction, i.e., the gender makeup of one’s interlocutors, also affects the way power is manifested in dialog. We focus especially on manifestations of power in the dialog structure — both, in a shallow sense that disregards the textual content of messages (e.g., how often do the participants contribute, how often do they get replies etc.), as well as the structure that is expressed within the textual content (e.g., who issues requests and how are they made, whose requests get responses etc.). We find that both gender and gender environment affect the ways power is manifested in dialog, resulting in patterns that reveal the underlying factors. Finally, we show the utility of gender information in the problem of automatically predicting the direction of power between pairs of participants in email interactions. |
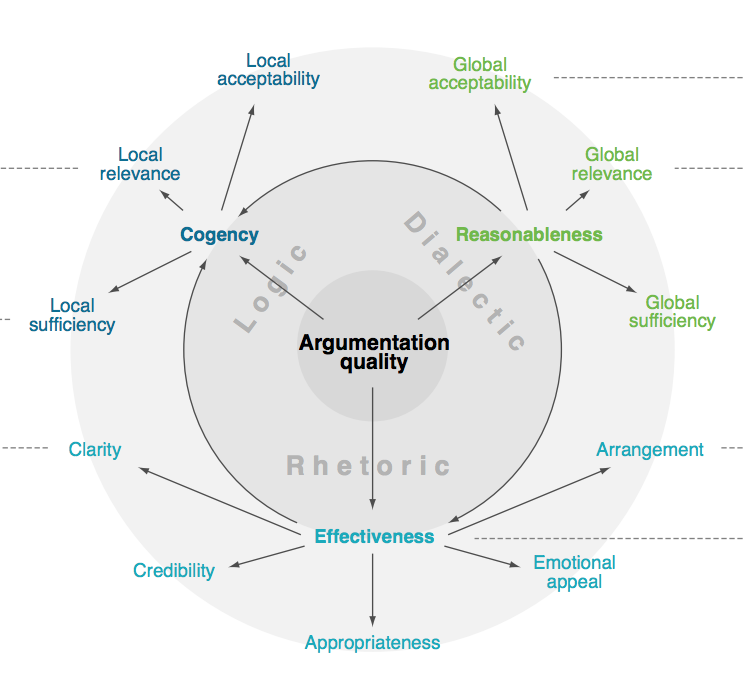 |
Computational Argumentation Quality Assessment in Natural Language.Conference Paper In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL), April 2017, Valencia, Spain.
AbstractResearch on computational argumentation faces the problem of how to automatically assess the quality of an argument or argumentation. While different quality dimensions have been approached in natural language processing, a common understanding of argumentation quality is still missing. This paper presents the first holistic work on computational argumentation quality in natural language. We comprehensively survey the diverse existing theories and approaches to assess logical, rhetorical, and dialectical quality dimensions, and we derive a systematic taxonomy from these. In addition, we provide a corpus with 320 arguments, annotated for all 15 dimensions in the taxonomy. Our results establish a common ground for research on computational argumentation quality assessment. |
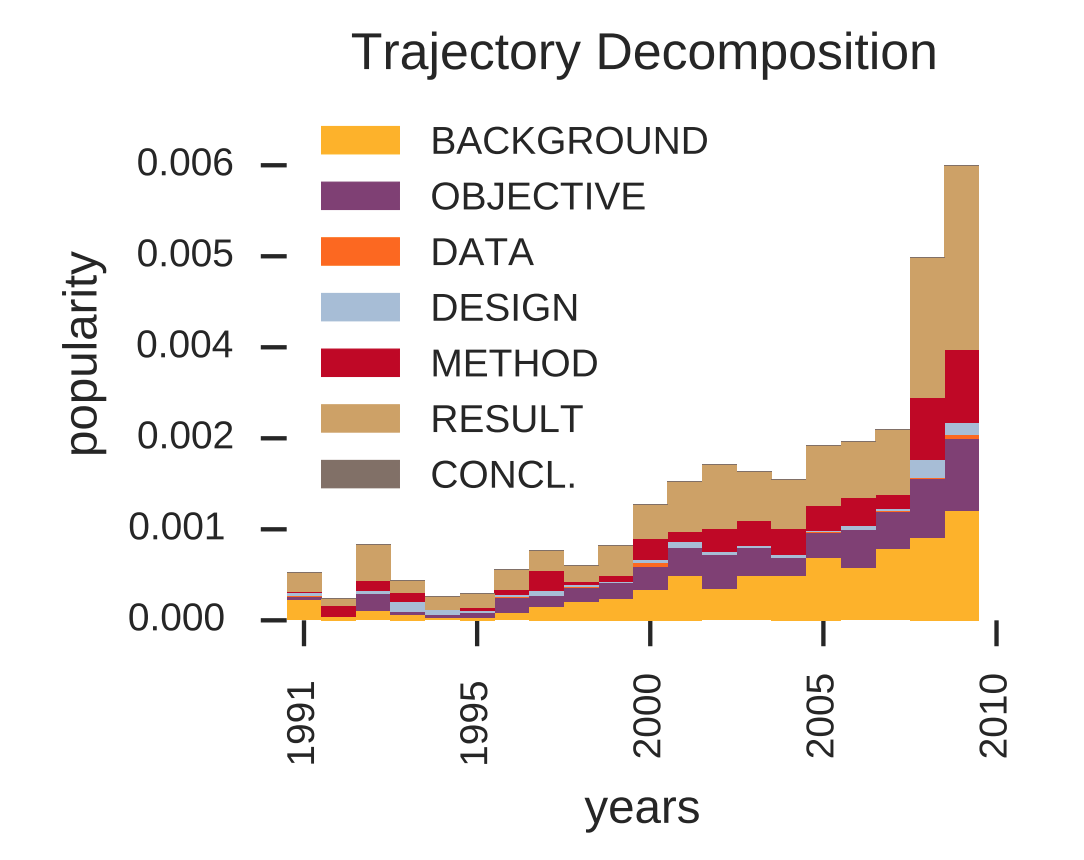 |
Predicting the Rise and Fall of Scientific Topics from Trends in their Rhetorical Framing.Conference Paper In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (ACL). August 2016. Berlin, Germany.
AbstractComputationally modeling the evolution of science by tracking how scientific topics rise and fall over time has important implications for research funding and public policy. However, little is known about the mechanisms underlying topic growth and decline. We investigate the role of rhetorical framing: whether the rhetorical role or function that authors ascribe to topics (as methods, as goals, as results, etc.) relates to the historical trajectory of the topics. We train topic models and a rhetorical function classifier to map topic models onto their rhetorical roles in 2.4 million abstracts from the Web of Science from 1991-2010. We find that a topic’s rhetorical function is highly predictive of its eventual growth or decline. For example, topics that are rhetorically described as results tend to be in decline, while topics that function as methods tend to be in early phases of growth. |
 |
 |
 |
A Corpus of Wikipedia Discussions: Over the Years, with Topic, Power and Gender Labels.Conference PaperIn Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC-2016). May 2016. Portoroz, Slovenia.
AbstractIn order to gain a deep understanding of how social context manifests in interactions, we need data that represents interactions from a large community of people over a long period of time, capturing different aspects of social context. In this paper, we present a large corpus of Wikipedia Talk page discussions that are collected from a broad range of topics, containing discussions that happened over a period of 15 years. The dataset contains 166,322 discussion threads, across 1236 articles/topics that span 15 different topic categories or domains. The dataset also captures whether the post is made by an registered user or not, and whether he/she was an administrator at the time of making the post. It also captures the Wikipedia age of editors in terms of number of months spent as an editor, as well as their gender. This corpus will be a valuable resource to investigate a variety of computational sociolinguistics research questions regarding online social interactions. |
 |
How Powerful are You? gSPIN: Bringing Power Analysis to Your Finger Tips.Demo Paper In Proceedings of the 25th International Conference Companion on World Wide Web (WWW). April 2016. Montreal, Canada.
AbstractWe present the SPIN system, a computational tool to detect linguistic and dialog structure patterns in a social interaction that reveal the underlying power relations between its participants. The SPIN system labels sentences in an interaction with their dialog acts (i.e., communicative intents), detects instances of overt display of power, and predicts social power relations between its participants. We also describe a Google Chrome browser extension, namely gSPIN, to illustrate an exciting use-case of the SPIN system, which will be demonstrated at the demo session during the conference. |
 |
A New Dataset and Evaluation for Belief/Factuality.Conference PaperIn Proceedings of the Fourth Joint Conference on Lexical and Computational Semantics (*SEM). June, 2015. Denver, USA.
AbstractThe terms “belief” and “factuality” both refer to the intention of the writer to present the propositional content of an utterance as firmly believed by the writer, not firmly believed, or having some other status. This paper presents an ongoing annotation effort and an associated evaluation. |
 |
Learning Structures of Negations from Flat Annotations.Conference PaperIn Proceedings of the Fourth Joint Conference on Lexical and Computational Semantics (*SEM). June, 2015. Denver, USA.
AbstractWe propose a novel method to learn negation expressions in a specialized (medical) domain. In our corpus, negations are annotated as ‘flat’ text spans. This allows for some infelicities in the mark-up of the ground truth, making it less than perfectly aligned with the underlying syntactic structure. Nonetheless, the negations thus captured are correct in intent, and thus potentially valuable. We succeed in training a model for detecting the negated predicates corresponding to the annotated negations, by re-mapping the corpus to anchor its ‘flat’ annotation spans into the predicate argument structure. Our key idea—re-mapping the negation instance spans to more uniform syntactic nodes—makes it possible to re-frame the learning task as a simpler one, and to leverage an imperfect resource in a way which enables us to learn a high performance model. We achieve high accuracy for negation detection overall, 87%. Our re-mapping scheme can be constructively applied to existing flatly annotated resources for other tasks where syntactic context is vital. |
 |
Committed Belief Tagging on the FactBank and LU Corpora: A Comparative Study.Workshop PaperIn Proceedings of NAACL Workshop on Extra-propositional aspects of meaning in computational linguistics (ExProM). June, 2015. Denver, USA.
AbstractLevel of committed belief is a modality in natural language, it expresses a speak-er/writers belief in a proposition. Initial work exploring this phenomenon in the literature both from a linguistic and computational modeling perspective shows that it is a challenging phenomenon to capture, yet of great interest to several downstream NLP applications. In this work, we focus on identifying relevant features to the task of determining the level of committed belief tagging in two corpora specifically annotated for the phenomenon: the LU corpus and the FactBank corpus. We perform a thorough analysis comparing tagging schemes, infrastructure machinery, feature sets, preprocessing schemes and data genres and their impact on performance in both corpora. Our best results are an F1 score of 75.7 on the FactBank corpus and 72.9 on the smaller LU corpus. |
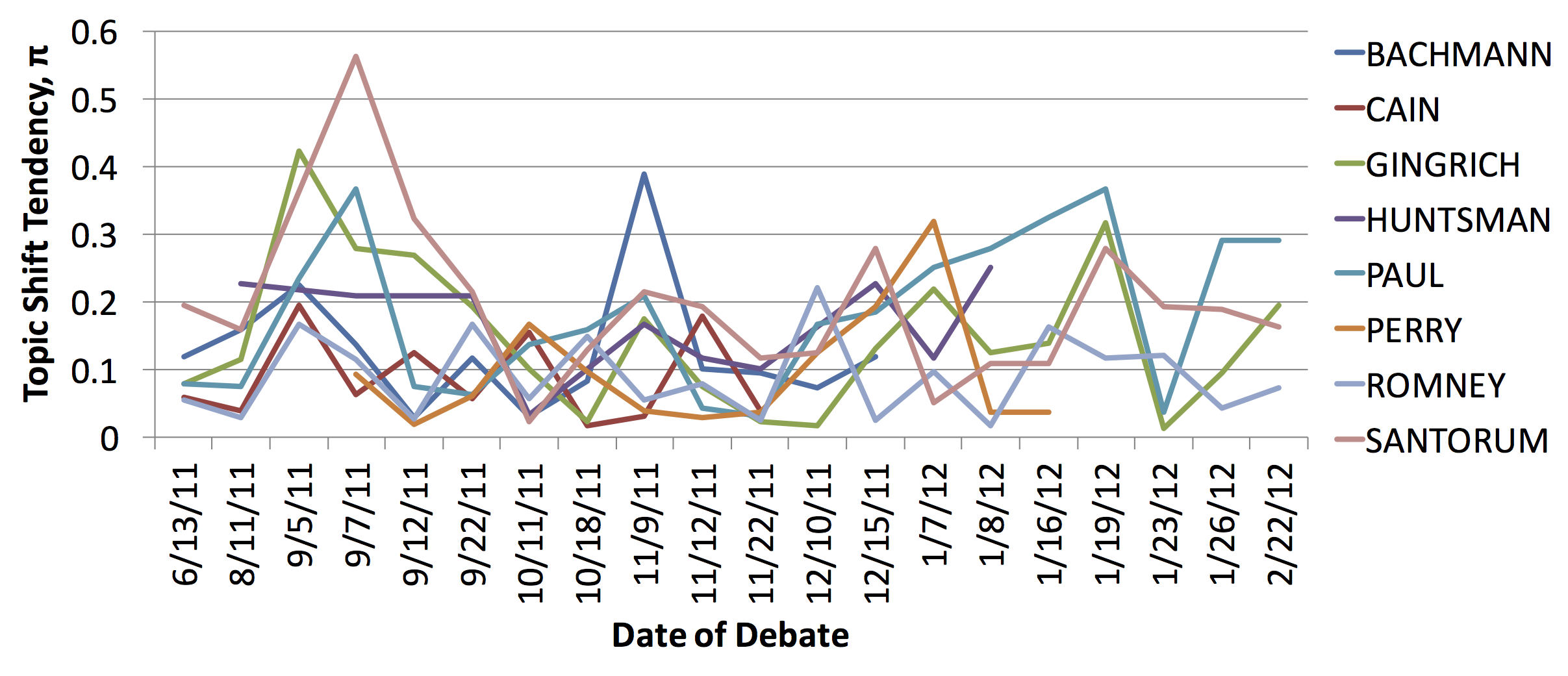 |
Staying on Topic: An Indicator of Power in Political Debates.Conference PaperIn Proceedings of the conference on Empirical Methods for Natural Language Processing (EMNLP): short papers. October, 2014. Doha, Qatar. (acceptance rate: 27.8%).
AbstractWe study the topic dynamics of interactions in political debates using the 2012 Republican presidential primary debates as data. We show that the tendency of candidates to shift topics changes over the course of the election campaign, and that it is correlated with their relative power. We also show that our topic shift features help predict candidates’ relative rankings. |
 |
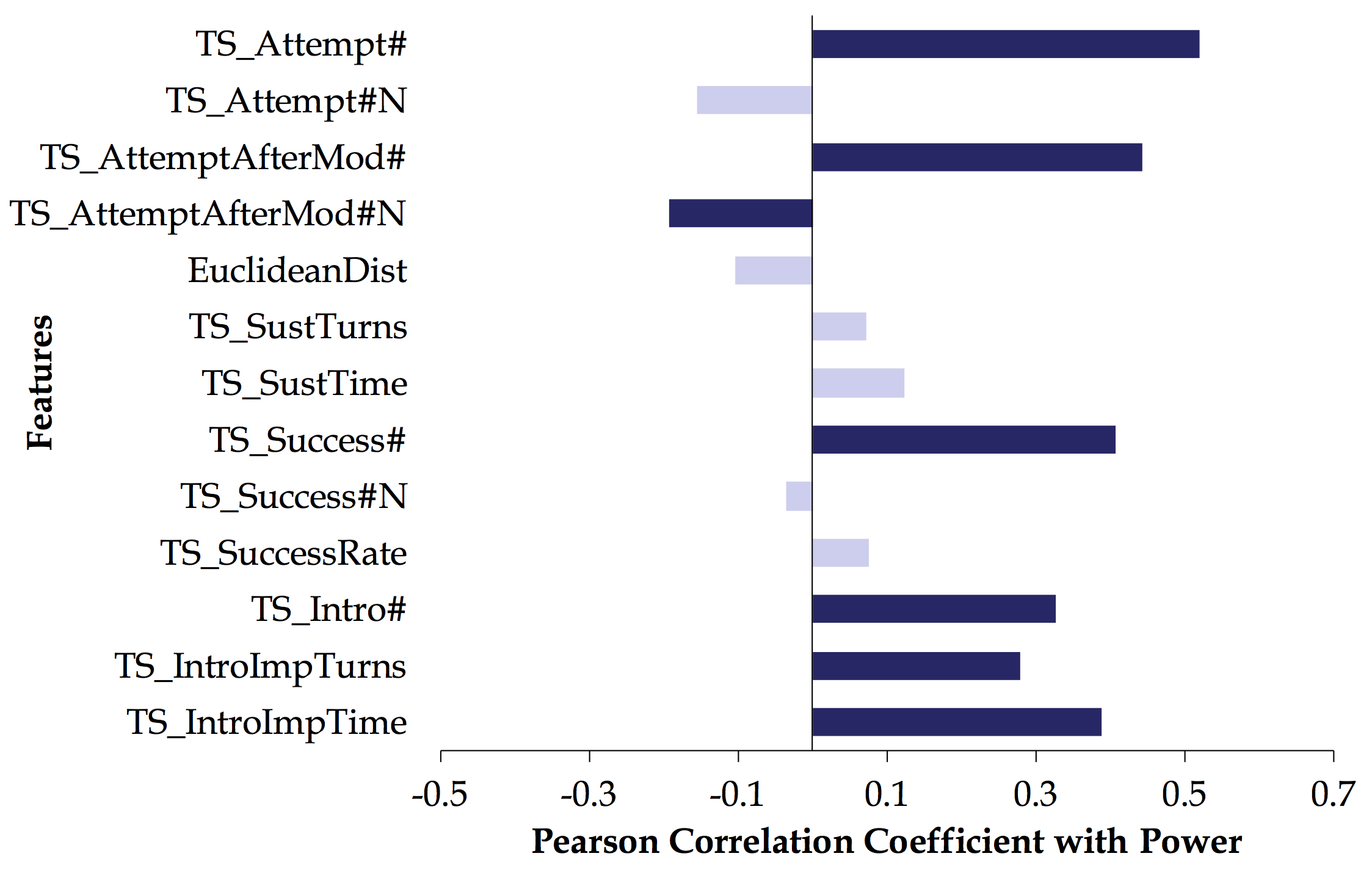
Gender and Power: How Gender and Gender Environment Affect Manifestations of Power.Conference PaperIn Proceedings of the conference on Empirical Methods for Natural Language Processing (EMNLP). October, 2014. Doha, Qatar. (acceptance rate: 30.4%).
AbstractWe investigate the interaction of power, gender, and language use in the Enron email corpus. We present a freely available extension to the Enron corpus, with the gender of senders of 87% messages reliably identified. Using this data, we test two specific hypotheses drawn from the sociolinguistic literature pertaining to gender and power: women managers use face-saving communicative strategies, and women use language more explicitly than men to create and maintain social relations. We introduce the notion of “gender environment” to the computational study of written conversations; we interpret this notion as the gender makeup of an email thread, and show that some manifestations of power differ significantly between gender environments. Finally, we show the utility of gender information in the problem of automatically predicting the direction of power between pairs of participants in email interactions. |
 |
Power of Confidence: How Poll Scores Impact Topic Dynamics in Political Debates.Workshop PaperIn Proceedings of the ACL Joint Workshop on Social Dynamics and Personal Attributes in Social Media. June, 2014. Baltimore, USA.
AbstractIn this paper, we investigate how topic dynamics during the course of an interaction correlate with the power differences between its participants. We perform this study on the US presidential debates and show that a candidate’s power, modeled after their poll scores, affects how often he/she attempts to shift topics and whether he/she succeeds. We ensure the validity of topic shifts by confirming, through a simple but effective method, that the turns that shift topics provide substantive topical content to the interaction. |
 |
Predicting Power Relations between Participants in Written Dialog from a Single Thread.Conference PaperIn Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (ACL) (Volume 2: Short Papers). June, 2014. Baltimore, USA. (acceptance rate: 25.2%) (Best Paper Honorable Mention)
AbstractWe introduce the problem of predicting who has power over whom in pairs of people based on a single written dialog. We propose a new set of structural features. We build a supervised learning system to predict the direction of power; our new features significantly improve the results over using previously proposed features. |
 |
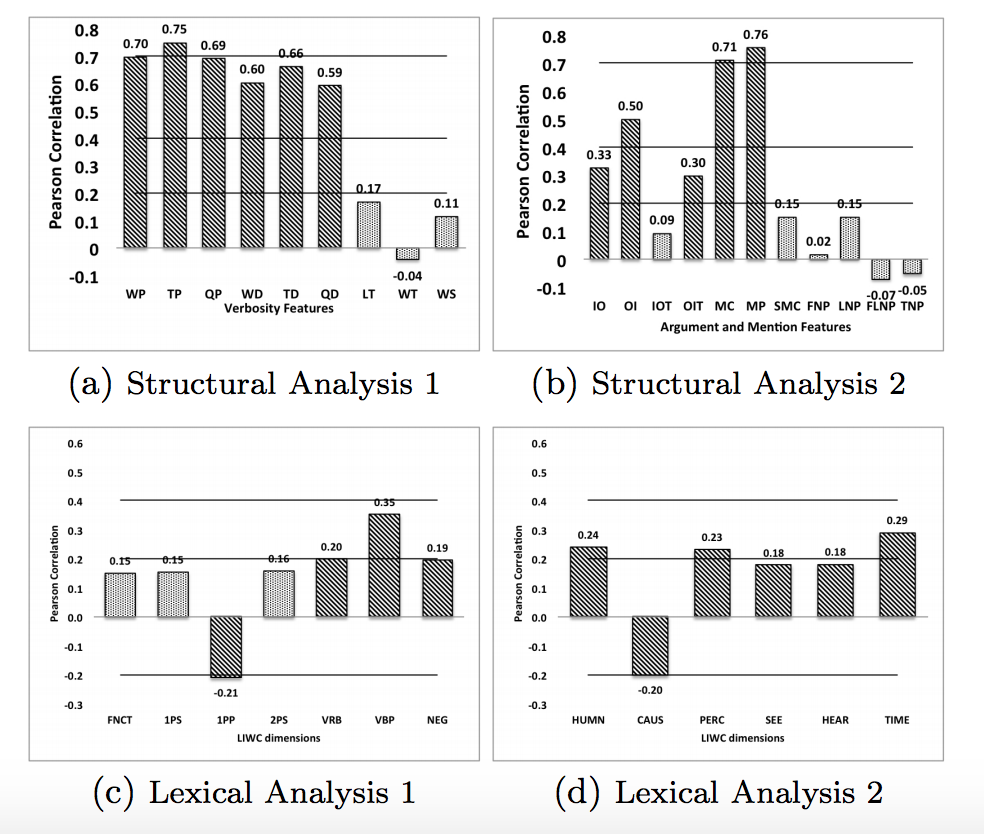
Who Had the Upper Hand? Ranking Participants of Interactions Based on Their Relative Power.Conference PaperIn Proceedings of the Sixth International Joint Conference on Natural Language Processing (IJCNLP). October, 2013. Nagoya, Japan. (acceptance rate: 23.4%)
AbstractIn this paper, we present an automatic system to rank participants of an interaction in terms of their relative power. We find several linguistic and structural features to be effective in predicting these rankings. We conduct our study in the domain of political debates, specifically the 2012 Republican presidential primary debates. Our dataset includes textual transcripts of 20 debates with 4-9 candidates as participants per debate. We model the power index of each candidate in terms of their relative poll standings in the state and national polls. We find that the candidates’ power indices affect the way they interact with others and the way others interact with them. We obtained encouraging results in our experiments and we expect these findings to carry across to other genres of multi-party conversations. |
 |
Written Dialog and Social Power: Manifestations of Different Types of Power in Dialog Behavior.Conference PaperIn Proceedings of the Sixth International Joint Conference on Natural Language Processing (IJCNLP). October, 2013. Nagoya, Japan. (acceptance rate: 23.4%)
AbstractDialog behavior is affected by power relations among the discourse participants. We show that four different types of power relations (hierarchical power, situational power, influence, and power over communication) affect written dialog behavior in different ways. We also present a system that can identify power relations given a written dialog. |
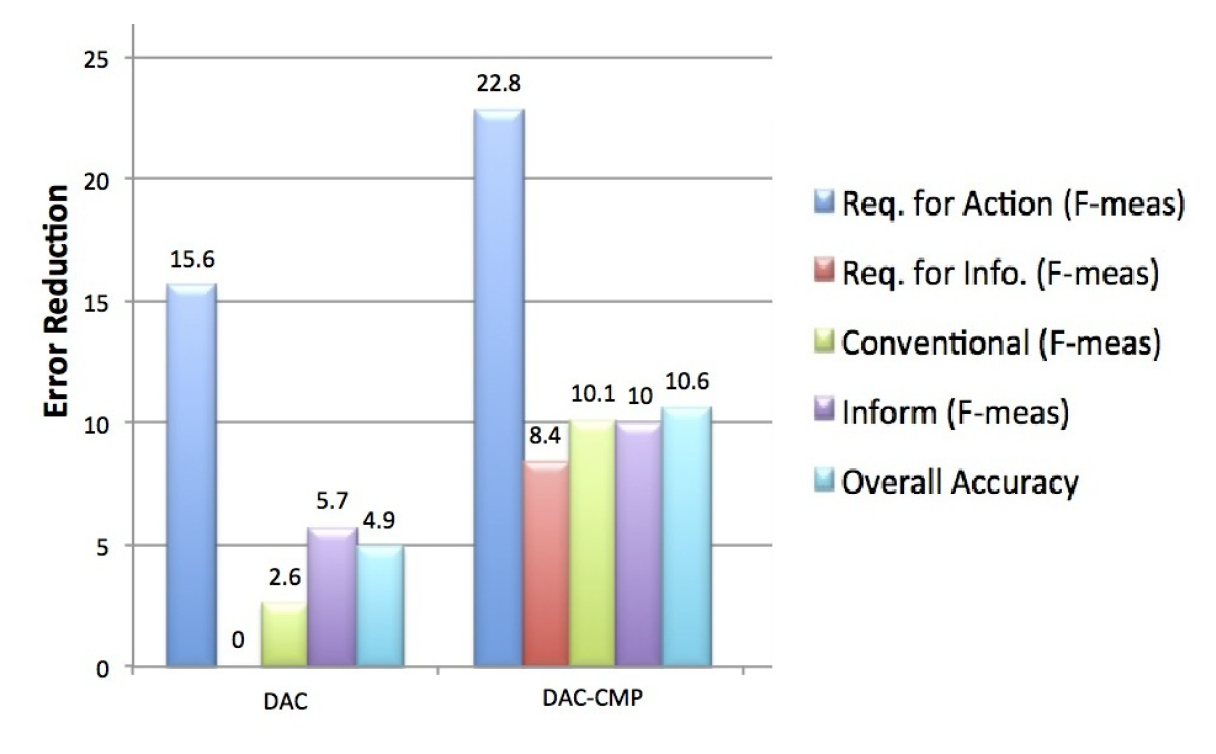 |
Improving the Quality of Minority Class Identification in Dialog Act Tagging.Conference PaperIn Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT). Atlanta, GA, USA (2013) (acceptance rate: 32%)
AbstractWe present a method of improving the performance of dialog act tagging in identifying minority classes by using per-class feature optimization and a method of choosing the class based not on confidence, but on a cascade of classifiers. We show that it gives a minority class F-measure error reduction of 22.8%, while also reducing the error for other classes and the overall error by about 10%. |
 |
Power Dynamics in Spoken Interactions: A Case Study on 2012 Republican Primary Debates.Conference PaperIn Proceedings of the 22nd International Conference Companion on World Wide Web (WWW). Rio de Janeiro, Brazil (2013)
AbstractIn this paper, we explore how the power differential between participants of an interaction affects the way they interact in the context of political debates. We analyze the 2012 Republican presidential primary debates where we model the power index of each candidate in terms of their poll standings. We find that the candidates’ power indices affected the way they interacted with others in the debates as well as how others interacted with them. |
 |
Who's (Really) the Boss? Perception of Situational Power in Written Interactions.Conference PaperIn Proceedings of COLING 2012. Mumbai, India (2012)
AbstractWe study the perception of situational power in written dialogs in the context of organizational emails and contrast it to the power attributed by organizational hierarchy. We analyze various correlates of the perception of power in the dialog structure and language use by participants in the dialog. We also present an SVM-based machine learning system using dialog structure and lexical features to predict persons with situational power in a given communication thread. |
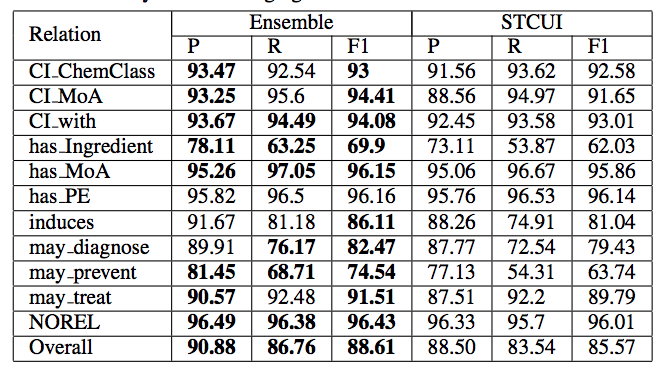 |
Relation Mining in the Biomedical Domain using Entity-level Semantics.Conference PaperIn Proceedings of the 19th European Conference on Artificial Intelligence (ECAI 2012). Montpellier, France (August, 2012) (acceptance rate: 28%)
AbstractThis work explores the use of semantic information from background knowledge sources for the task of relation mining between medical entities such as diseases, drugs, and their functional effects/actions. We hypothesize that the semantics of medical entities, and the information about them in different knowledge sources play an important role in determining their interactions and can thus be exploited to infer relations between these entities. We capture entities’ semantics using a number of resources such as Wikipedia, UMLS Semantic Network, MEDCIN, MeSH and SNOMED. Depending on coverage and specificity of the resources, and features of interest, different classifiers are learnt. An ensemble based approach is then used to fuse together individual predictions. Using a human-curated ontology as the gold standard, the proposed approach has been used to recognize ten medical relations of interest. We show that the proposed approach achieves substantial improvements in both coverage and performance over a distant supervision based baseline that uses sentence-level information. Finally, we also show that even a simple ensemble approach that combines all the semantic information is able to get the best coverage and performance. |
 |
Statistical Modality Tagging from Rule-based Annotations and Crowdsourcing.Workshop PaperIn Proceedings of the ACL Workshop on Extra-propositional aspects of meaning in computational linguistics (ExProM), Jeju, South Korea (July, 2012).
AbstractWe explore training an automatic modality tagger. Modality is the attitude that a speaker might have toward an event or state. One of the main hurdles for training a linguistic tagger is gathering training data. This is particularly problematic for training a tagger for modality because modality triggers are sparse for the overwhelming majority of sentences. We investigate an approach to automatically training a modality tagger where we first gathered sentences based on a high-recall simple rule-based modality tagger and then provided these sentences to Mechanical Turk annotators for further annotation. We used the resulting set of training data to train a precise modality tagger using a multi-class SVM that delivers good performance. |
 |
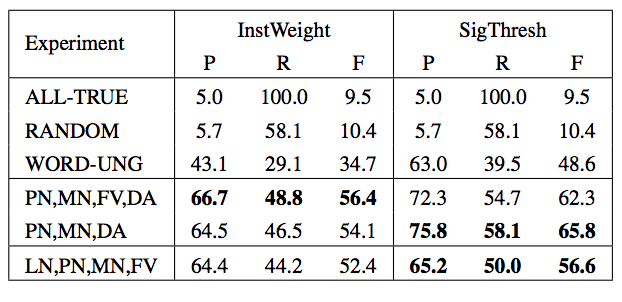
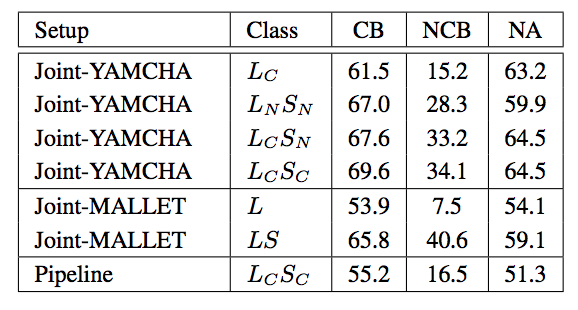
Detecting Power Relations from Written Dialog.Workshop PaperIn Proceedings of ACL 2012 Student Research Workshop, Jeju, South Korea (July, 2012).
AbstractIn my thesis I propose a data-oriented study on how social power relations between participants manifest in the language and structure of online written dialogs. I propose that there are different types of power relations and they are different in the ways they are expressed and revealed in dialog and across different languages, genres and domains. So far, I have defined four types of power and annotated them in corporate email threads in English and found support that they in fact manifest differently in the threads. Using dialog and language features, I have built a system to predict participants possessing these types of power within email threads. I intend to extend this system to other languages, genres and domains and to improve it’s performance using deeper linguistic analysis. |
 |
Predicting overt display of power in written dialogs.Conference PaperIn Proceedings of North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT). Montreal, Canada (June, 2012)
AbstractWe analyze overt displays of power (ODPs) in written dialogs. We present an email corpus with utterances annotated for ODP and present a supervised learning system to predict it. We obtain a best cross validation F-measure of 65.8 using gold dialog act features and 55.6 without using them. |
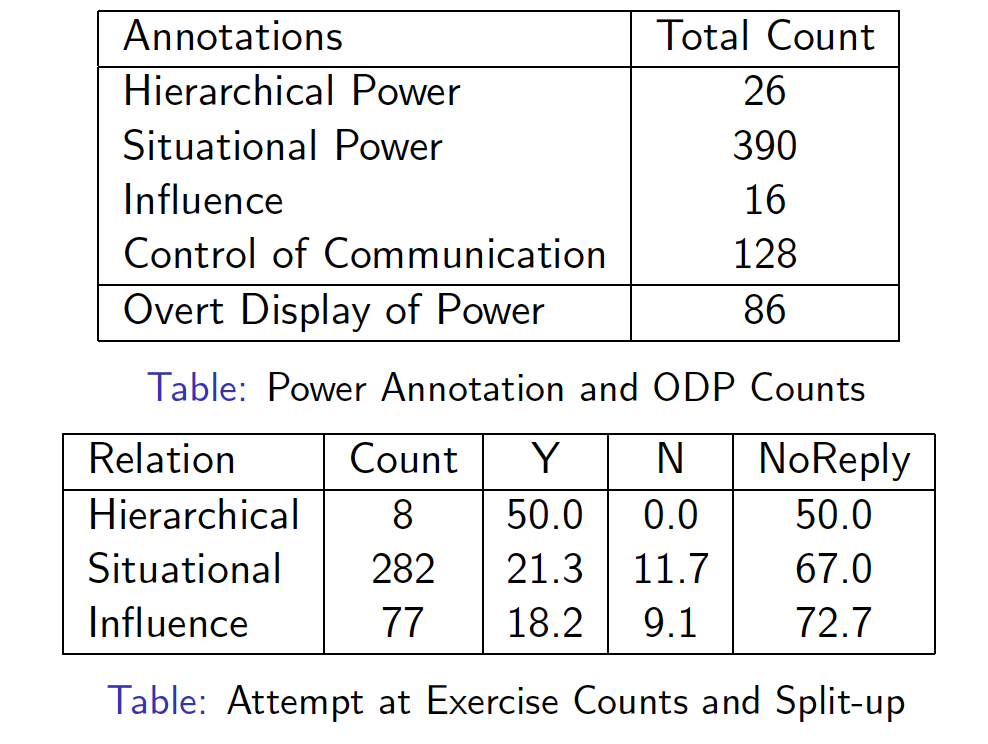 |
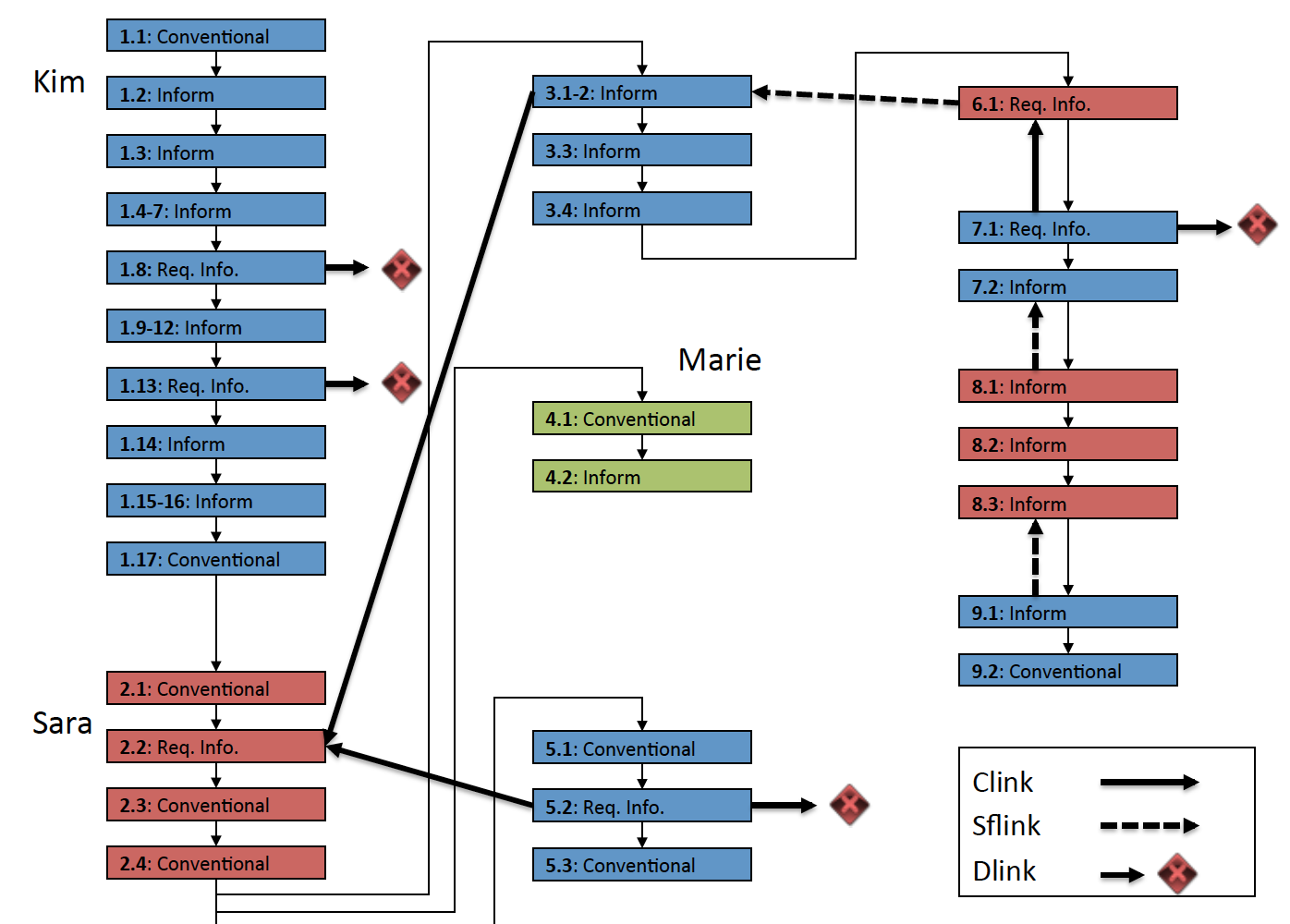
Annotations for Power Relations on Email Threads.Conference PaperIn Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC-2012). Istanbul, Turkey (May 2012).
AbstractSocial relations like power and influence are difficult concepts to define, but are easily recognizable when expressed. In this paper, we describe a multi-layer annotation scheme for social power relations that are recognizable from online written interactions. We introduce a typology of four types of power relations between dialog participants: hierarchical power, situational power, influence and control of communication. We also present a corpus of Enron emails comprising of 122 threaded conversations, manually annotated with instances of these power relations between participants. Our annotations also capture attempts at exercise of power or influence and whether those attempts were successful or not. In addition, we also capture utterance level annotations for overt display of power. We describe the annotation definitions using two example email threads from our corpus illustrating each type of power relation. We also present detailed instructions given to the annotators and provide various statistics on annotations in the corpus. |
 |
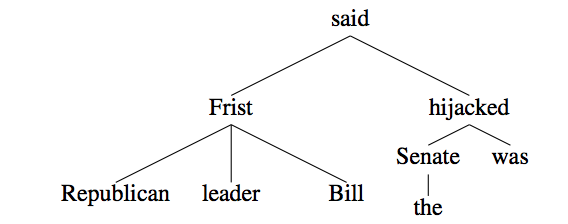
Automatic committed belief tagging.Conference PaperIn Proceedings of Conference on Computational Linguistics (COLING) 2010. Beijing, China (2010).
AbstractWe go beyond simple propositional meaning extraction and present experiments in determining which propositions in text the author believes. We show that deep syntactic parsing helps for this task. Our best feature combination achieves an Fmeasure of 64%, a relative reduction in Fmeasure error of 21% over not using syntactic features. |
 |
Uncertainty Learning Using SVMs and CRFs.Workshop PaperIn Proceedings of the Fourteenth Conference on Computational Natural Language Learning: Shared Task, Uppsala, Sweden, 15-16 July 2010.
AbstractIn this work, we explore the use of SVMs and CRFs in the problem of predicting certainty in sentences. We consider this as a task of tagging uncertainty cues in context, for which we used lexical, wordlist-based and deep-syntactic features. Results show that the syntactic context of the tokens in conjunction with the wordlist-based features turned out to be useful in predicting uncertainty cues. |
 |
Committed Belief Annotation and Tagging.Workshop PaperIn Proceedings of the Fourteenth Conference on Computational Natural Language Learning: Shared Task, Uppsala, Sweden, 15-16 July 2010.
AbstractWe present a preliminary pilot study of belief annotation and automatic tagging. Our objective is to explore semantic meaning beyond surface propositions. We aim to model people’s cognitive states, namely their beliefs as expressed through linguistic means. We model the strength of their beliefs and their (the human) degree of commitment to their utterance. We explore only the perspective of the author of a text. We classify predicates into one of three possibilities: committed belief, non committed belief, or not applicable. We proceed to manually annotate data to that end, then we build a supervised framework to test the feasibility of automatically predicting these belief states. Even though the data is relatively small, we show that automatic prediction of a belief class is a feasible task. Using syntactic features, we are able to obtain significant improvements over a simple baseline of 23% F-measure absolute points. The best performing automatic tagging condition is where we use POS tag, word type feature AlphaNumeric, and shallow syntactic chunk information CHUNK. Our best overall performance is 53.97% F-measure. |
 |
Autonomous Restructuring Portfolios in Credit Cards.Conference PaperIn Proceedings of the TCS Technical Architects Conference (TACTiCS), Charlotte, NC. (October 2007) (Best Paper Honorable Mention).
AbstractThis paper proposes the novel concept of Autonomous Restructuring Portfolios which would enable financial portfolios to re-adjust themselves to cater with the highly volatile customer behavior pattern. It investigates the possibility of using Kohonen’s Self Organizing Maps in analyzing, categorizing & modifying strategies applied on financial portfolios according to the its behavior patterns. It also puts forth a design which could enhance the effectiveness of the strategy assignment to different areas of portfolios. This model would introduce new strategies to meet new scenarios as well as to drop off obsolete strategies. This model is also applicable to any financial portfolio where dynamic business decisions needs to be made based on the portfolio’s behavior. |