Code
See our code release on
Github, which allows you to train Multimodal Recurrent Neural Networks that describe images with sentences. You may also want to download the dataset JSON and VGG CNN features for
Flickr8K (50MB),
Flickr30K (200MB), or
COCO (750MB). You can also download the JSON blobs for all three datasets (but without the VGG CNN features)
here (35MB). See our Github repo for more instructions.
Update: NeuralTalk has now been
deprecated, in favor of the more recent release of
NeuralTalk2.
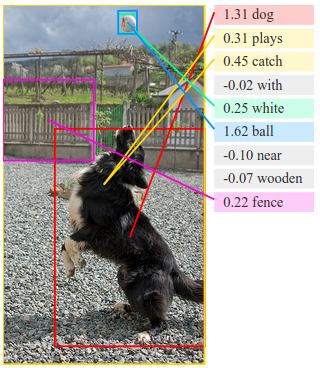
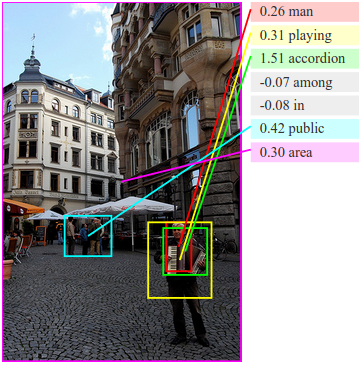
Region Annotations
Our COCO region annotations test set can be found
here as json. These consist of 9000 noun phrases collected on 200 images from COCO. Every image has a total of 45 region annotations from 9 distinct AMT workers.