-
Learning to Interactively Learn and Assist
- (Algorithm)
This video describes our "Learning to Interactively Learn and Assist" paper, published with Chelsea Finn and Karol Hausman.
Paper abstract: When deploying autonomous agents in the real world, we need effective ways of communicating objectives to them. Traditional skill learning has revolved around reinforcement and imitation learning, each with rigid constraints on the format of information exchanged between the human and the agent. While scalar rewards carry little information, demonstrations require significant effort to provide and may carry more information than is necessary. Furthermore, rewards and demonstrations are often defined and collected before training begins, when the human is most uncertain about what information would help the agent. In contrast, when humans communicate objectives with each other, they make use of a large vocabulary of informative behaviors, including non-verbal communication, and often communicate throughout learning, responding to observed behavior. In this way, humans communicate intent with minimal effort. In this paper, we propose such interactive learning as an alternative to reward or demonstration-driven learning. To accomplish this, we introduce a multi-agent training framework that enables an agent to learn from another agent who knows the current task. Through a series of experiments, we demonstrate the emergence of a variety of interactive learning behaviors, including information-sharing, information-seeking, and question-answering. Most importantly, we find that our approach produces an agent that is capable of learning interactively from a human user, without a set of explicit demonstrations or a reward function, and achieving significantly better performance cooperatively with a human than a human performing the task alone.
(, paper, paper website)
-
Learning a Frame-Level Model from Video-Level Labels
- (Algorithm)
This is an example of a deep learning model that trains a frame-level model from video-level labels.
This word was done for DeepIntent.
In the video, the model is applied to the problem of detecting if tobacco content is present in a video.
()
-
Highlight Extraction in American Football
- (Algorithm)
This is an example of a deep learning model for video segmentation and classification.
This work was done for The Cube.
Here it is applied to extracting highlights from high school football.
Nothing about the model structure or code is specific to football.
()
-
Identifying Runs, Passes, and Kicks in American Football
- (Algorithm)
This is an example of a deep learning model for video segmentation and classification.
This work was done for The Cube.
Here it is applied to segmenting plays and labeling their type (run, pass, or kick)
in high school football.
Nothing about the model structure or code is specific to football.
()
-
Active One-shot Learning
- (Algorithm)
This video describes our "Active One-shot Learning" paper, published with Chelsea Finn in the 2016 NIPS Workshop on Deep Reinforcement Learning.
Paper abstract: Recent advances in one-shot learning have produced models that can learn from a
handful of labeled examples, for passive classification and regression tasks. This
paper combines reinforcement learning with one-shot learning, allowing the model
to decide, during classification, which examples are worth labeling. We introduce
a classification task in which a stream of images are presented and, on each time
step, a decision must be made to either predict a label or pay to receive the correct
label. We present a recurrent neural network based action-value function, and
demonstrate its ability to learn how and when to request labels. Through the choice
of reward function, the model can achieve a higher prediction accuracy than a
similar model on a purely supervised task, or trade prediction accuracy for fewer
label requests.
(, paper, poster, code)
-
Possession Segmentation in Basketball
- (Algorithm)
This is an example of a deep learning model for video segmentation.
This work was done for The Cube.
Here it is applied to segmenting possessions in high school basketball.
Nothing about the model structure or code is specific to basketball.
()
-
Play Segmentation in Football
- (Algorithm)
This is early work on a deep learning model for detecting arbitrary
events in video. The work was done
for The Cube. Here it is applied to
segmenting plays in videos of highschool football.
()
-
Detection of Vocals in Songs
- (Algorithm)
This is a demonstration of a deep learning model applied to the
problem of detecting when vocals are present in a song. I needed a
non-asr (automatic speech recognition) task to play with. I trained
on the Jamendo song corpus.
()
-
Inference in Toy Football
- (Algorithm)
This is early work on a deep learning model for for detecting arbitrary
events in video. The work was done
for The Cube. Here it is applied to
video of Toy Football. The plays are detected and are classified
into 4 toy types (advance, incomplete, touchdown, and field goal).
()
-
Tele-Operated Farm Equipment
- (Hardware, Software)
This is an idea I explored of using cheap remote labor to automate farm equipment via teleoperation. See the video for a demonstration. The demo used a webcam on the crossbar, which is why I am leaning out of the way. I created hardware for actuating the steering wheel, and wrote software based on WebRTC to remotely view the scene and command the wheel. I used a cellphone for the internet connection (3G). The remote operator is controling the tractor from their home via a web interface. In the video the remote operator is able to keep the tractor in the middle of the row and make the turn at the end of the row.
()
-
Autosteer for Tractors
- (Hardware, Software)
This is a product I developed with a friend of mine who is a farmer. It is a 10 inch touch screen that plugs into John Deere tractors and automatically steers the tractor on a row. See the for a walk through of the product. I designed and sourced fabrication of the cnc machined enclosure, designed and sourced the electronics, modified and configured linux for our needs, and wrote the Qt GUI. One of the larger accomplishments was listening on the CAN bus and reverse engineering the John Deere protocol for commanding the tractor.
()
-
Object Tracking System
- (Hardware, Algorithm)
This was a project to create a simple object tracking system. The system places an led circuit, blinking with a unique code, on each object to be tracked. This has an advantage over fiducial tracking systems, such as ARToolkit, in that the object need only take up a single pixel in the image; so roughly 10 times as many objects can be tracked. By running a Bayesian Filter on the video stream, the identity of a bright pixel can be inferred over time; e.g. "object 5", or "background noise". The image to the left shows the prototype breadboard with two blinking circuits on it, the switches set the code to be blinked. The movie below shows the tracking system in action. A computer displayed one blinking light and one background noise light, a webcam then recorded the screen, and the video was processed. Noise was added to both the background light and the coded light. The filter successfully tracked the identity of the objects ("Nob" for the background light, "Ob" for the coded light), and the phase of "Ob"'s code (since the filter doesn't know when the objected started blinking its code). The hypothesis with the maximum probability is drawn, as is the probability of that hypothesis.
()
-
Object Detection, GentleBoost with Decision Stumps
- (Algorithm)
This was a project for Leslie Valiant's Computational Learning Theory course. I was excited about recent developments in computer vision, namely the work on on object detection by Antonio Torralba et al. PAMI 2007, extended by Morgan Quigley et al. ICRA 2009, GentleBoosting decision stumps of image features. So I decided to implement their algorithm for one of my robots. See the report for details and results, but ignore the comparison to the perceptron with PCA dimension reduction, there are much better algorithms to compare against (I needed something simple to compare against).
(report)
-
Cluster POMDP Solver
- (Algorithm)
This was a project for Harvard's Massively Parallel Computing course. I was seeking a way to leverage computer clusters, specifically Amazon's EC2 (Elastic Compute Cloud), for speeding up online exploration of POMDPs. A POMDP is a powerful framework for representing decision problems where an agent must make a series of decisions in a world whose state is only observable through noisy measurements; examples of this type of decision problem include: missile guidance, robot navigation, human-robot interaction, and high-frequency trading. Unfortunately, finding optimal, or near-optimal, actions for a POMDP is computationally intensive. My thesis surveys a number of approaches for addressing POMDP computation through algorithmic modifications. This project looked at how to throw more computational power at the problem. There are many parallel aspects of POMDP solvers which could be leveraged by a cluster. One of which is the agent's belief. I chose to distribute the agent's belief across the cluster (using MPI) and let each server solve the POMDP for its reduced belief. The solutions were then merged together to find the approximately optimal next action. The main benefit to this approach is that it requires a minimal amount of bandwidth, which is a main limitation of clusters. See the video for a summary of the project and results. See the presentation for the slides from the video. See the report for the details of the project.
(,
presentation,
report)
-
Generative Computer Vision
- (Algorithm)
Current cutting edge object detection algorithms work by scanning across pixels in an image, extracting features around the current pixel, and passing these features to a classifier which determines if the object is at that pixel. If the object is being tracked in a video stream, the output of the classifier is then fed to a filtering algorithm to track the state of the system. This project explored an alternative approach, though extremely computationally intensive. The idea is that we can treat the raw image as measurements for the filtering algorithm. What is needed then is a measurement model which gives the probability of the measured image as a function of the state. The model used here was to generate the full world scene using the graphics card, and assume independent Gaussian noise on each pixel. This idea is mathematically elegant because it extends probabilistic filtering all the way down to the raw image measurements, but it is extremely computationally intensive; to update the filter you need to generate an image for all possible states of the world (often infinite). Thus, this is no where near real-time. Perhaps future processing power or algorithmic modifications will make this feasible. This idea is not new, early computer vision algorithms used a similar "model based" approach. Early approaches failed because of processing limitations and because of their deterministic nature (no probabilistic filtering). The image to the left shows the raw image next to the computer generated image corresponding to the maximum likelihood estimate for the scene. The bottom of the image shows the likelihood function for the position of the cone in world coordinates; the bright region in the lower left hand corner corresponds to the true location of the cone, and the black dot in the middle of this region is the maximum which was used to generate the right camera view.
-
Motor Controller
- (Hardware)
With one of our larger robots, I was sick of wires connecting multiple circuit boards for each motor (usb interface, motor driver, joint encoder), so I designed this motor controller board. The board has an H-bridge that can drive 25 amps at up to 30 volts. There are inputs for wheel encoders or potentiometers. An Atmega324 handles the computation, and interfaces to a central computer via usb. The H-bridge components and microcontroller were chosen such that the motors can be driven above 20KHz, which is beyond the range of human hearing, so the motors will operate silently. The high voltage, high current H-bridge is electrically isolated from the microcontroller and usb circuitry.
-
Fire Alarm Repeater
- (Hardware, Algorithm)
This is a device that listens for the sound of a smoke detector, if detected, it uses an embedded phone modem to connect to a remote server, which then sends me a text message. This was a fun project to experiment with embedded signal filters, and it saved me the monthly charges from a company like ADT. I implemented a band-pass digital filter (Butterworth) on an Atmega168 8-bit microcontroller to detect the roughly 3.3KHz beep generated by smoke detectors. The microcontroller continuously samples the microphone at 8KHz, updating the band-pass filter with each 10 bit sample. All circuitry was incorporated into a printed circuit board (PCB) and enclosed in a laser cut acrylic case. Since the microcontroller does not have a floating point unit, a simple fixed-point math library was written.
-
Humanoid Servo Robot
- (Hardware)
This is a robot I constructed from standard hobby servos. The servo mechanical connections were 3-d printed and the torso and base plates were laser cut from acrylic. There are seven degrees of freedom in the humanoid torso. The wheeled base uses two hobby servos modified for continuous rotation as in the Simple Servo Robot below. The robot is equipped with a wireless web camera which streams images to a laptop. The laptop controls the robot via the RC Transmitter Interface described below.
-
Simple Servo Robot
- (Hardware)
I a needed quick robot to demonstrate an algorithm in a paper. This robot took one day to create. It consists of two standard hobby servos, modified for continuous rotation, hot glued to two rc car wheels and mounted to a piece of acrylic. A third hobby servo raises and lowers a laser-cut acrylic ring. The servos are connected to a standard hobby receiver and the robot is controlled from the laptop via the RC Transmitter Interface described below. The robot is tracked with a standard web camera detecting the colored construction paper. See the video below from the AIPR 2008 paper, for the robot in action.
( -
image -
image)
-
Kalman Filter for an Indoor Helicopter
- (Algorithm)
In support of an indoor helicopter project at the Harvard
Microrobotics Laboratory, I implemented a Kalman filter. The state
space consisted of 16 elements: 7 for the position and orientation of
the helicopter (orientation was represented with a quaternion), 6
for the linear and angular velocities, and 6 for the linear
and angular accelerations. The motion model assumed constant
acceleration (this is the same assumption made in the Kalman filter
used by Stanford's autonomous helicopter). Measurement models were
created for the onboard IMU and vision based position estimate. The
video below shows a simulated helicopter with noisy measurements
filtered to a trajectory consistent with the helicopter's
dynamics. The true helicopter state and the estimated state are
shown. The estimated state is drawn offset from the true state for
visualization. Note that the filter only sees the true helicopter through
the noisy measurements. The vision based position estimate has a
standard deviation of 20cm, but by integrating over time, making use of the IMU
measurements, and the helicopter dynamics, the estimated RMS
position error is on the order of 2-4cm.
()
-
Autonomous Indoor Vehicle
- (Hardware, Algorithm)
This is one of the platforms which I created to support my research
at Harvard. The vehicle has two drive wheels and a rear skid
plate. The robot is equipped with a 2GHz processor, a
laser scanner, a firewire camera, an inertial measurement unit (IMU), wheel encoders, and two
hours of battery life. The frame was laser cut from acrylic. Custom
printed circuit boards (PCBs) were designed to interface the IMU and
wheel encoders with the computer. Here is an early version
of the robot. In the video below, the robot maps and localizes a cluttered
room using the FastSLAM algorithm (the robot starts to move about 20
seconds into the video) (I had not yet fit the parameters of the
motion model and measurement models when this video was taken, but
the hand coded parameters performed reasonably well).
(,
image,
image)
-
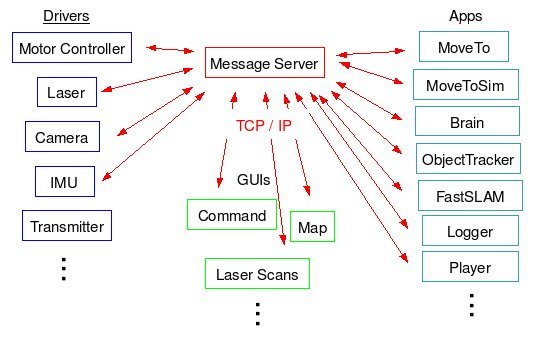
Robot Software Infrastructure
- (Algorithm)
This is an infrastructure for communicating between the various
software components within a robot; it consisting of a software
library and a central messaging server. The architecture was inspired
by Mike Montemerlo's architecture
for Stanford's DARPA Grand Challenge entry, Stanley. Each driver, gui,
and application, is coded as a stand alone application. Each
application can subscribe to messages and publish its own
messages. A library provides the publish, subscribe, and event
generation functions. Internally, the library sends messages over
TCP/IP via a simple message server application. This is a very light
system (less than 1000 lines of code) which provides a strict
interface between software components. This architecture is similar
to Willow Garage's robot
operating system (ROS); Morgan Quigley, the
original architect of ROS, and I were both inspired by the Stanley
architecture. Morgan created what would become ROS and I created
this Infrastructure. I continue to use this for personal use, since
it is light weight and my drivers are already written for it, but I
recommend that others use ROS as it is more robust and has a broad
and active support base.
-
Fast SLAM on a Microcontroller
- (Algorithm)
Neato Robotics was developing a robotic vacuum that would build a map of a home and localize itself within the map. This problem is often called simultaneous localization and mapping (SLAM). I advised them on the FastSLAM algorithm and, along with Vlad Ermakov at Neato Robotics, modified the FastSLAM algorithm to run on an Atmel microcontroller. The vacuum has since been released to positives reviews.
-
Camera Based Localization
- (Algorithm)
For Sebastian Thrun's Statistical Robotics course, I developed a
localization system that turns a 2d video stream into a range
scanner. Monte-carlo localization was then used to localize the
robot within a map, given this range data. See the report and
presentation for details. See the video for a demonstration of the
system; the robot follows an L-bend in a hallway, and turns around
mid way down the next segment.
(report,
presentation,
)
-
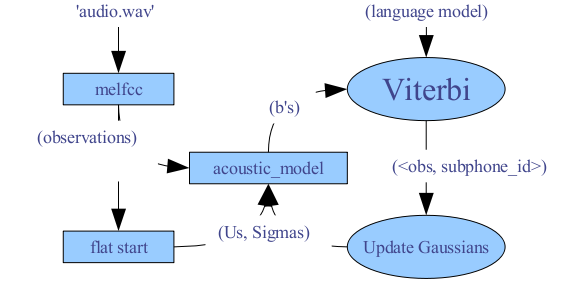
Speech Recognizer for Robot Dog
- (Algorithm)
For Dan Jorafsky's Speech Recognition course, I developed from
scratch a complete speech recognizer for commanding a robot dog,
including software for training the HMM. The acoustic model uses
three subphones per phoneme. A single gaussian is fit for each
subphone. Viterbi decoding is used for recognition and during
training. The image to the left shows the flow for training the
system. See the report for details.
(report)
-
Tracking a Ground Vehicle from a Helicopter
- (Algorithm)
This was a project under Professor Andrew Ng. I developed vision
software to track a ground vehicle in a helicopter mounted video
stream. The video below shows the helicopter autonomously tracking a
remote controlled car using this vision software.
()
-
Carrier Phase Differential GPS
- (Hardware)
Aerobatic control of the Stanford autonomous helicopter required
accurate position estimates. Standard GPS suffers inaccuracies due
to atmospheric conditions which affect the time of flight of the
satellite signals. Differential GPS (DGPS) corrects for these atmospheric
conditions using a reference signal from a base station whose
position is know. Carrier phase DGPS (CP-DGPS) employs a base
station as well, but compares the phase of the raw carrier sine wave
rather than the coded signal on top of the sine wave. This results in
3d position accuracies of a few centimeters, which is what is needed
for aerobatic helicopter control. In this
project, Michael
Vitas and I implemented CP-DGPS using Novatel's superstar II GPS
boards. See Michael's report below for an introduction to CP-DGPS
and for results from our experiments. To support this project I
created a printed circuit board (PCB) for communicating with the
superstar II.
(report)
-
RC Transmitter Interface
- (Hardware)
Because of their low cost and robustness, I have often used standard
hobby remote control (RC) equipment in my robots. On the back of
many RC transmitters is a trainer port, which allows the signals
from one transmitter to be output through another transmitter. This
is a PCB that I designed which allow a computer to send signals
through a transmitter's trainer port.
-
Air Hockey Playing Robot
- (Algorithm)
For Oussama Khatib's Experimental Robotics course, John
Rogers, Archan Padmanabhan, and I created an air hockey playing
robot. We used a Puma 500 robot arm with a paddle as the end
effector, and tracked the hockey puck using a standard webcam. The
arm was force controlled using cubic spline trajectories in
operational space. See the report for a brief description. The video
shows the robot in action.
(report -
)
-
Space-Indexed Dynamic Program
- (Algorithm)
I implemented and evaluated the space-indexed dynamic programming
(SIDP) control algorithm on Stanley, Stanford's autonomous off-road
vehicle. These results were used in the paper that introduced SIDP
(paper).
-
Tracking multiple objects using optical flow and particle filters
- (Algorithm)
For Sebastian Thrun's Introduction to Computer Vision course,
I developed a vision system that tracks multiple vehicles in a
video stream. The algorithm uses optical flow, so no model of the
cars' appearance is needed. The filtering over time is done with
a particle filter (in retrospect this was a gross approximation to the
particle filter, but it worked). See the report for details and the
video for a demonstration.
(report -
)
-
OBD-II Car Interface
- (Hardware)
Since the mid 1980s, most automobiles have been equipped with a diagnostic
port under the driver side dashboard. The main protocol spoken by
this port is called OBD-II. At the time, the diagnostic tools for
connecting to this port were expensive, so I created a board that
would allow me to access and clear my car's diagnostic codes via my
laptop's USB port. This was the first printed circuit board (PCB)
that I designed; it is missing many standard features, such as a
ground plane and decoupling capacitors, but it works well.
-
Autonomous RC Car
- (Hardware)
This is localization and control hardware that I created to support my
undergraduate senior project. Localization: The laser, mounted between the rear
shocks, has a vertical line lens and spins at a known angular
velocity. Three boxes with light dependent resistors (LDR), pictured
in the lower right, are placed in a known location in the
environment. Given the known position of the boxes, the known
angular rate of the laser, and the measured laser arrival delay
between the boxes, the position of the vehicle can be
computed. Control: A small box was mounted to the back of the
transmitter. You can see it propping up the transmitter. The box
contains two digital to analog converters (DACs) that speak I2C. The
DAC outputs were connected to the trigger and wheel potentiometer
outputs in the transmitter. The DAC I2C input was "bit banged" from a
computer's serial port. See the report for details.
(report)































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}