
| |
Figure 1. Role of context in group activities. It is often hard to distinguish actions from each individual person alone (the left image). However, if we look at the whole scene (the right images), we can easily recognize the activity of the group and the action of each individual.
we develop two different approaches to model the person-person interaction. The first approach is
A Latent Structure Based Approach
We introduce an approach that explores person-person interaction in the structure level. Different from most of the previous work in latent structured models that assume a predefined structure for the hidden layer, e.g. a tree structure, we treat the structure of the hidden layer as a latent variable and implicitly infer it during learning and inference.
 |
 |
| (a) |
(b) |
Figure 2. Graphical illustration of the model in (a). The edges represented by dashed lines indicate the connections are latent. Different types of potentials are denoted by lines with different colors in the example shown in (b).
The benefit of using adaptive structures is to exclude irrelevant context. With fixed structures, the model might try to enforce two persons to have certain pairs of action labels (e.g. facing the same direction), even though these two persons have nothing to do with each other. Take “talking” for example, it is common that in one frame, people are talking in two or more groups. It is possible that two people talking in different groups are facing the same direction, this kind of interaction may confuse "talking" with "queuing". In addition, selecting a subset of connections allows one to remove "clutter" in the form of people performing irrelevant actions.
A Contextual Feature Based Approach
Another approach approach enables analyzing human actions by looking at contextual information extracted from the behaviour of nearby people. We still utilize the latent variable framework introduced above. However, one important difference from the structure-level approach is that we don’t consider any pairwise connections between variables h in the hidden layer. Instead we focus on attaching contextual information into feature descriptors x. We develop a novel feature representation called the action context (AC) descriptor.

Figure 3. Illustration of construction of our action context descriptor. (a) Spatio-temporal context region around focal person, as indicated by the green cylinder. In this example, we regard the fallen person as focal person, and the people standing and walking as context. (b) Spatio-temporal context region around focal person is divided in space and time. The first 3-bin histogram captures the action of the focal person, which we call the action descriptor. The latter three 3-bin histograms are the context descriptor, and capture the behaviour of other people nearby. (c) The action context descriptor is formed by concatenating the action descriptor and the context descriptor.
The feature descriptor of the m-th spatio-temporal region is: STm = max (over each dimension) Fi, for all the people located in the region. |
|
The action descriptor of the i-th person: Fi = [S1i,S2i,...,SKi], where Ski is the the score of classifying the i-th person to the k-th action class returned by the SVM classifier. |
Figure 4. How to compute feature descriptor for one spatio-temporal region.
The AC descriptor for the i-th person is a concatenation of its action descriptor Fi and its context descriptor Ci: ACi = [Fi,Ci]. Suppose that the context region is further divided into M spatio-temporal regions in space and time, then the context descriptor Ci is a cocatenation of the descriptos of all the spatio-temporal regions: Ci = [ST1, ST2, ..., STM].
Experimental Results
Baselines



Figure 5. Different baseline structures of person-person interaction. From left to right: No connection between any pair of nodes; Nodes are connected by a minimum spanning tree; Any two nodes within a Euclidean distance epsilon are connected.
Results
We evaluate our proposed method on a benchmark dataset for collective human activities.

Figure 6. Comparison of activity classification accuracies of different methods on the collective activity dataset. We report both the overall and mean per-class accuracies due to the class imbalance.



Figure 7. Confusion matrices for activity classification on the collective activity dataset: (a) global bag-of-words. (b) Structure-level approach. (c) Feature-level approach. Rows are ground-truths, and columns are predictions. Each row is normalized to sum to 1.










Figure 8. Visualization of the classification results and the learned structure of person-person interaction on the collective activity dataset. The top row shows correct classification examples and the bottom row shows incorrect examples. The labels C, S, Q, W, T indicate crossing, waiting, queuing, walking and talking respectively. The labels R, FR, F, FL, L, BL, B, BR indicate right, front-right, front, front-left, left, back-left, back and back-right respectively. The yellow lines represent the learned structure of person-person interaction, from which some important interactions for each activity can be obtained, e.g. a chain structure which connects persons facing the same direction is “important” for the queuing activity.




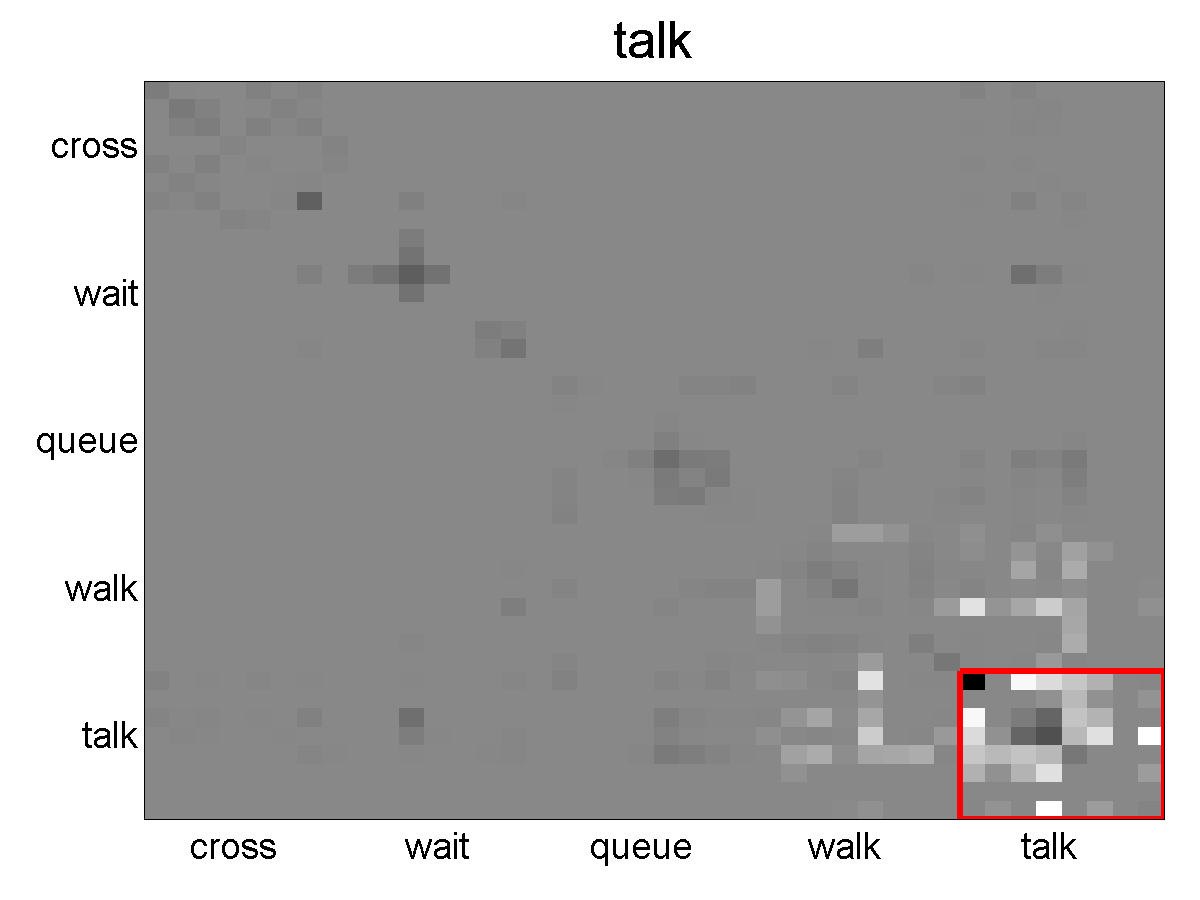

Figure 9. Visualization of the weights across pairs of action classes for each of the five activity classes on the collective activity dataset. Light cells indicate large values of weights. Consider the example (a), under the activity label crossing, the model favors seeing actions of crossing with different poses together (indicated by the area bounded by the red box). We can also take a closer look at the weights within actions of crossing, as shown in (f). we can see that within the crossing category, the model favors seeing the same pose together, indicated by the light regions along the diagonal. It also favors some opposite poses, e.g. back-right with front-left. These make sense since people always cross street in either the same or the opposite directions.
Tian Lan, Yang Wang, Weilong Yang, and Greg Mori. Beyond Actions: Discriminative Models for Contextual Group Activities. Neural Information Processing Systems (NIPS), 2010. [pdf] [poster]
Tian Lan, Yang Wang, Greg Mori, and Stephen Robinovitch. Retrieving Actions in Group Contexts. International Workshop on Sign Gesture Activity (at ECCV), 2010. [pdf]
