
Shirley Wu
Shirley is working on post-training at Meta TBD Labs.
She was a Ph.D. student at Stanford Computer Science, advised by Jure Leskovec and James Zou. She interned at Microsoft Research, working with Michel Galley and Jianfeng Gao. Previously, she earned her B.S. in Data Science from the University of Science and Technology of China, where she was advised by Xiangnan He. During her undergraduate studies, she also interned at the NExT++ lab at the National University of Singapore, working with Xiang Wang and Tat-Seng Chua.
Her Ph.D. work centered around LLM agents, alignment, and human-agent interactions. Her Ph.D. research focused on advancing the capabilities of LLM agents (self-improvement, knowledge-grounded retrieval, tool use) and aligning these agents with user objectives in the real world (optimizing multiturn collaborations and multiagent / compound systems).
Twitter Scholar PhD Thesis GitHub Linkedin Email: shir{last_name}@cs.stanford.edu
What's
New
[01/2026] I defended my PhD titled Collaborative AI Agents!!
[01/2026]
[01/2026]
[05/2025]
[09/2024]
[09/2024] STaRK, AvaTaR, and GraphMETRO are accepted to NeurIPS 2024!
[05/2024] My talks about STaRK at the Stanford Annual Affiliates Meeting
Research
Topics
-

CollabLLM: From Passive Responders to Active Collaborators
ICML 2025 (Outstanding)
Shirley Wu, Michel Galley, Baolin Peng, Hao Cheng, Gavin Li, Yao Dou, Weixin Cai, James Zou, Jure Leskovec, Jianfeng Gao Problem: LLMs act as passive responders, especially when faced with ambiguity. They don't naturally help users clarify needs or explore options.
Contribution: CollabLLM empowers LLMs to actively seek information from users and collaborate more effectively with humans.
Key Insight: Reward responses based on their long-term impact on the conversation.
-
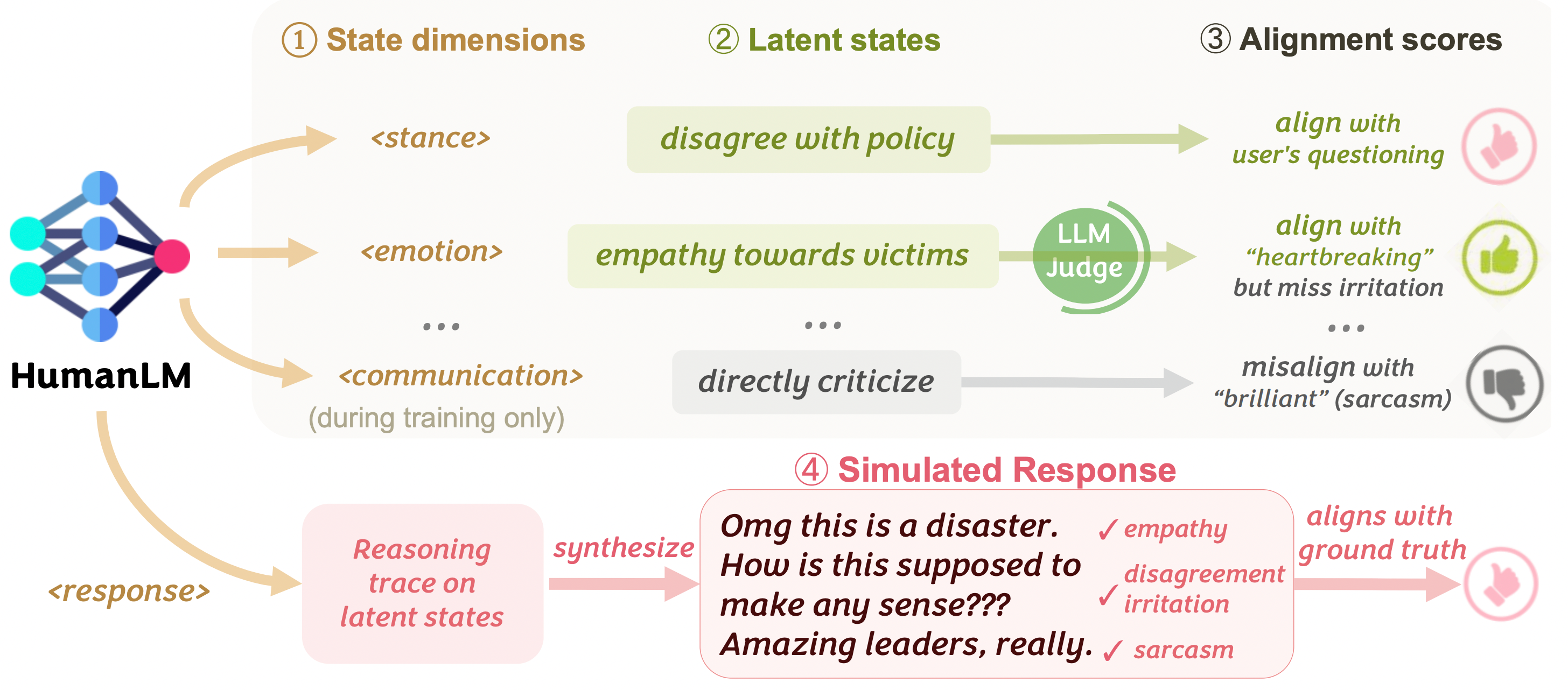
HumanLM: Simulating Users with State Alignment Beats Response Imitation
2026
Shirley Wu*, Evelyn Choi*, Arpandeep Khatua*, Zhanghan Wang, Joy He-Yueya, Tharindu Cyril Weerasooriya, Wei Wei, Diyi Yang, Jure Leskovec, James Zou Problem: Existing user simulators mostly imitate surface-level patterns and language styles.
Contribution: HumanLM builds user simulators that accurately reflect real users
Key Insight: Generate intermediate natural-language latent states aligned with ground-truth responses via reinforcement learning.
-
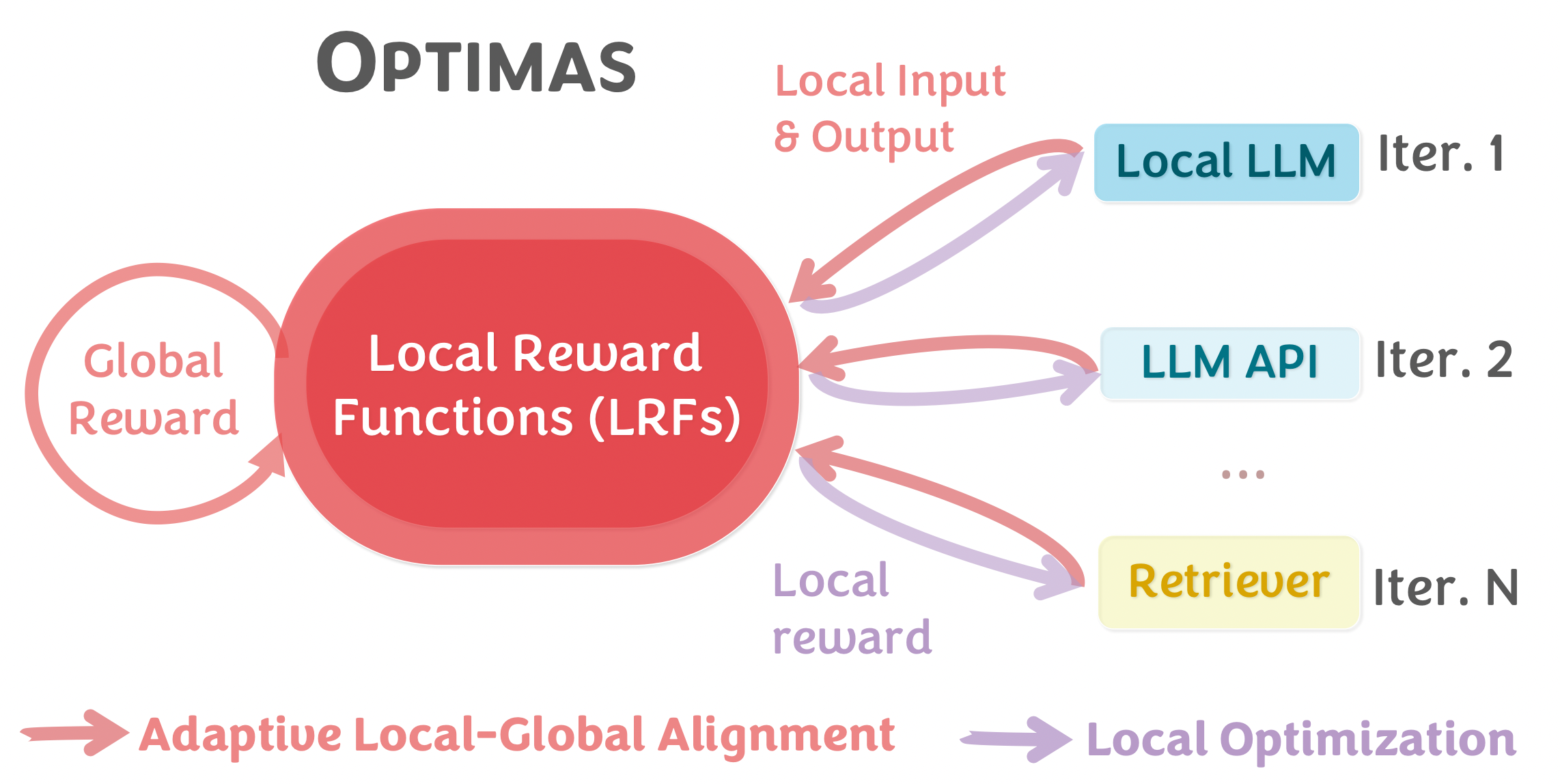
Optimas: Optimizing Compound AI Systems with Globally Aligned Local Rewards
ICLR 2026
Shirley Wu*, Parth Sarthi*, Shiyu Zhao*, Aaron Lee, Herumb Shandilya, Adrian Mladenic Grobelnik, Nurendra Choudhary, Eddie Huang, Karthik Subbian, Linjun Zhang, Diyi Yang, James Zou*, Jure Leskovec* Problem: Compound AI systems integrating multiple AI components lack unified optimization.
Contribution: Optimas provides a unified framework that effectively optimizes compound AI systems by enabling simultaneous tuning of prompts, hyperparameters, model parameters, and model routers.
Key Insight: Globally aligned local reward signals for joint optimization of diverse system components.
-

STaRK: Benchmarking LLM Retrieval on Textual and Relational Knowledge Bases
NeurIPS 2024
Shirley Wu*, Shiyu Zhao*, Michihiro Yasunaga, Kexin Huang, Kaidi Cao, Qian Huang, Vassilis N. Ioannidis, Karthik Subbian, James Zou*, Jure Leskovec* Problem: How do we systematically evaluate systems on complex, semi-structured QA?
Contribution: STaRK is a large-scale retrieval benchmark on Textual and Relational Knowledge Bases.
Why STaRK: Realistic complex queries across diverse domains and accurate ground truth.
-

AvaTaR: Optimizing LLM Agents for Tool Usage via Contrastive Reasoning
NeurIPS 2024
Shirley Wu, Shiyu Zhao, Qian Huang, Kexin Huang, Michihiro Yasunaga, Kaidi Cao, Vassilis N. Ioannidis, Karthik Subbian, Jure Leskovec*, James Zou* Problem: LLMs cannot effectively use external tools.
Contribution: AvaTaR helps LLMs better tackle complex Q&A tasks by improving their ability to leverage tools
Key Insight: Contrastive reasoning to construct instructions for tool usage and multi-stage problems.
-

GraphMETRO: Mitigating Complex Graph Distribution Shifts via Mixture of Aligned Experts
NeurIPS 2024
Shirley Wu, Kaidi Cao, Bruno Ribeiro, James Zou*, Jure Leskovec* Task: Node and graph classification.
What: A framework that enhances GNN generalization under complex distribution shifts.
Benefits: Generalization and interpretability on distribution shift types.
How: Through a mixture-of-expert architecture and training objective. -

Discovering Invariant Rationales for Graph Neural Networks
ICLR 2022
Ying-Xin Wu, Xiang Wang, An Zhang, Xiangnan He, Tat-Seng Chua. Task: Graph classification.
What: An invariant learning algorithm for GNNs.
Motivation: GNNs mostly fail to generalize to OOD datasets and provide interpretations.
Insight: We construct interventional distributions as "multiple eyes" to discover the features that make the label invarian (i.e., causal features).
Benefits: Intrinsic interpretable GNNs that are robust and generalizable to OOD datasets. -

Let Invariant Rationale Discovery Inspire Graph Contrastive Learning
ICML 2022 Sihang Li, Xiang Wang, An Zhang, Ying-Xin Wu, Xiangnan He and Tat-Seng Chua Task: Graph classification.
What: A graph contrastive learning (GCL) method with model interpretations.
How: We generate rationale-aware graphs for contrastive learning to achieve better transferability. -

Knowledge-Aware Meta-learning for Low-Resource Text Classification
EMNLP (Oral) 2021. Short Paper.
Huaxiu Yao, Ying-Xin Wu, Maruan Al-Shedivat, Eric P. Xing. Task: Text classification.
What: A meta-learning algorithm for low-resource text classification problem.
How: We extract sentence-specific subgraphs from a knowledge graph for training.
Benefits: Better generalization between meta-training and meta-testing tasks.
-

Discover and Cure: Concept-aware Mitigation of Spurious Correlation (DISC)
ICML 2023
Shirley Wu, Mert Yuksekgonul, Linjun Zhang, James Zou. What: DISC adaptively mitigates spurious correlations during model training.
Benefits: Less spurious bias, better generalization, and unambiguous interpretations.
How: Using concept images generated by Stable Diffusion, in each iteration, DISC computes a metric called concept sensitivity to indicate each concept's spuriousness. Guided by it, DISC creates a balanced dataset (where spurious correlations are removed) to update model. -

Med-Flamingo: a Multimodal Medical Few-shot Learner
ML4H, NeurIPS 2023
Michael Moor*, Qian Huang*, Shirley Wu, Michihiro Yasunaga, Cyril Zakka,
Yash Dalmia, Eduardo Pontes Reis, Pranav Rajpurkar, Jure LeskovecTask: Visual question answering, rationale generation etc.
What: A new multimodal few-shot learner specialized for the medical domain.
How: Based on OpenFlamingo-9B, we continue pre-training on paired and interleaved medical image-text data from publications and textbooks.
Benefits: Few-shot generative medical VQA abilities in the medical domain. -

Holistic analysis of hallucination in GPT-4V(ision): Bias and interference challenges (BINGO)
Preprint
Chenhang Cui, Yiyang Zhou, Xinyu Yang, Shirley Wu, Linjun Zhang,
James Zou, Huaxiu YaoWhat: A benchmark designed to evaluate two common types of hallucinations in visual language models: bias and interference.
-

Deconfounding to Explanation Evaluation in Graph Neural Networks
Preprint
Ying-Xin Wu, Xiang Wang, An Zhang, Xia Hu, Fuli Feng, Xiangnan He, Tat-Seng Chua Task: Explanation evaluation.
What: A new paradigm to evaluate GNN explanations.
Motivation: Explanations evaluation fundamentally guides the diretion of GNNs explainability.
Insight: Removal-based evaluation hardly reflects the true importance of explanations.
Benefits: More faithful ranking of different explanations and explanatory methods. -

D4Explainer: In-distribution Explanations of Graph Neural Network via Discrete Denoising Diffusion
NeurIPS 2023
Jialin Chen, Shirley Wu, Abhijit Gupta, Rex Ying Task: Explanation generation for GNNs.
What: A unified framework that generates both counterfactual and model-level explanations
Benefits: The explanations are in-distribution and thus more reliable. -

Towards Multi-Grained Explainability for Graph Neural Networks
NeurIPS 2021
Xiang Wang, Ying-Xin Wu, An Zhang, Xiangnan He, Tat-Seng Chua. Task: Explanation generation for GNNs.
What: ReFine, a two-step explainer.
How: It generates multi-grained explanations via pre-training and fine-tuning.
Benefits: Obtain both global (for a group) and local explanations (for an instance). -

Reinforced Causal Explainer for Graph Neural Networks
TPAMI. May 2022
Xiang Wang, Ying-Xin Wu, An Zhang, Fuli Feng, Xiangnan He & Tat-Seng Chua. Task: Explanation generation for GNNs.
What: Reinforced Causal Explainer (RC-Explainer).
How: It frames an explanatory subgraph via successively adding edges using a policy network.
Benefits: Faithful and concise explanations.
Education
Experiences


Univ. of Sci & Tech of China
2018.9 - 2022.7Advisor: Prof. Xiangnan He

Stanford University
2021.3 - 2021.8Advisor: Dr. Huaxiu Yao
Working on Meta-learning and Knowledge Graph.
Class/Conference Services
{kind=link}
{kind=link}