Unsafe in Rust: Syntactic Patterns
Overview
Despite the fundamental role unsafe plays in Rust, we have relatively little
understanding of how it is being used in real codebases. As the community
decides what the exact semantics of unsafe should be, it becomes increasingly
important to have this understanding in order to avoid accidentally diverging
from the expectations of library writers. This post takes a first step in that
direction by laying the basis for syntactic analyses of unsafe in Rust code
hosted on crates.io.
Introduction
Rust is a new systems programming language that seems to promise the world: all the control of C/C++ as well as all of the safety and convenience of your favorite high-level language. At its heart is a statically verified system of memory management - an incarnation of the RAII pattern baked into the type system itself. The compiler enforces a strict system of memory ownership which allows it to automatically and statically determine when memory should be allocated and deallocated. The ownership system (in combination with a few other language features) renders Rust immune to a wide variety of memory-related bugs, such as null pointer dereferences, use after free, buffer overflow, and reading undefined values.
While the Rust ownership model is fairly expressive, it prohibits programmers from writing several necessary constructs. In particular, a number of low level data structures are difficult or impossible to implement within the confines of the ownership model. It’s fairly normal for high-level languages to fail to meet all the needs of their users, and historically many languages have addressed shortcomings like these through Foreign Function Interface (FFI); that is, they allow code generated by other languages to be run from their language. Most often this looks like high-level language X calling C code to handle a data structure or interact with the system.
Rust too allows for FFI, but it isn’t the best tool in the shed for implementing a particularly detailed data structure because Rust also provides another option - unsafe Rust. As is explained in the Rustonomicon, unsafe Rust is perhaps best thought of as an entirely new programming language which is a strict superset of Rust: it allows you to do all the things you can do in Rust, as well as a few other things that are too wild for the compiler to verify. The existence of unsafe is great because it means that essentially any program you’re interested in writing can indeed be written in (possibly unsafe) Rust. For example, the entirety of the Rust compiler1 and all of the Rust standard library are written in Rust (with the help of some carefully encapsulated unsafe code).
The way unsafe works is like this: you use it by declaring that you’d like to
enter the unsafe boundary by applying the unsafe keyword to either a function
or a block. Then, within that function or block you’re able to do a few extra
things, such as dereferencing raw pointers and calling unsafe
functions. That may not sound like a lot of extra power, but believe me it is -
pointers are scary things and unsafe functions include compiler intrinsics that
do crazy things like transmute data from one type to another without any
bit-level conversion.
The Question
So in some sense, unsafe is part of the secret sauce of Rust - it allows
programmers to do all the wild memory-unsafe things they need to do to
implement awesome data structures and interact with the system, but also
requires them to declare that they’re doing so, and encourages them to bundle
up their unsafe code into safe abstractions.
The thing is, sometimes it’s difficult to encapsulate unsafe code inside a safe abstraction. In fact, sometimes its even unclear what that actually means. In a colloquial sense it means that the Rust type system (including the ownership model) is being respected, but this is still difficult to define and even more difficult to verify. In fact, there has lately been a lot of discussion around what the formal model for unsafe should be, without a clear consensus.
In light of the more niche or theoretical ambiguities, it’s worth investigating how unsafe code is currently being used by real-world codebases, that is: “How and why do Rust programs use unsafe code?”
The Strategy
While our guiding question is somewhat nebulous, we can quickly specify to a few starting questions:
- How many crates use
unsafein some way? - What unsafe operations are they performing? Dereferencing raw pointers? Making FFI calls? Mutating global statics?
- What fraction of rust code is unsafe? In terms of blocks? In terms of functions?
The thing is - while we can start by distilling our guiding question ("How and why do Rust programs use unsafe code?") into specific smaller questions, there are a million ways we could do so - our list is by no means exhaustive.
Furthermore, answering questions like these isn’t the easiest thing in the world. To start with, the easiest way to gain access to syntactic or semantic information about a Rust program is to lean on the analysis done by the compiler, requiring you to write a compiler plugin, using the compiler’s driver system. Then you’ve got to sift through the compiler’s data structures in order to extract the information you’re curious about. If you’re interested in more than just the AST (perhaps you want type information, so you can tell when pointers are being dereferenced), then you’ll have to wait until after the compiler’s analysis passes have completed.
So it seems like we’re in for a rough time - to get to our guiding question it seems we need to collect a potentially large set of statistics, and aggregating any one statistic seems like a lot of work.
Fortunately, a lot of the work to collect different statistics is identical -
we compile the same crates, get the same AST, and comb through them looking for
details relevant to unsafe. In fact, the details we’re interested in are
often the same: the unsafe blocks, unsafe functions, and unsafe operations.
So let’s cut out this redundancy! Rather than running a new plugin for each
statistic, I decided to take the compiler’s data structures (specifically the
HIR) and reduce it to an Unsafe Abstract Syntax Tree (or UAST). This tree
encodes the syntactic structure of how unsafe is declared and used in Rust
programs. Specifically, it describes the relationships between contexts
(blocks and functions) that might declare unsafe and operations that use it
(unsafe function calls, pointer dereferences, interaction with mutable statics,
and inline assembly). It also includes information about block sizes, statement
indexes, spans, and snippets.
The result is a much simpler data structure than the original AST, which still captures a lot of the information we’re interested in when analyzing unsafe usage patterns. Furthermore, it makes that information available without having to run the compiler.
As an extra bonus the UAST can be serialized as JSON using rustc_serialize,
and the result is simple and small enough that it can be processed using
command line utilities such as jq.
The Process
- Write a compiler plugin that acts exactly like
rustc, but also builds a UAST from the HIR and dumps the UAST to standard error. - Get a powerful server from Amazon Web Services.
- Download all the crates from crates.io, using
cargo clone. - Try to build them all (unfortunately needing to build dependencies along the way).
- For those that succeed, collect the UASTs, zip them, and download them.
- Analyze using
jq.
Some Results
How Many Crates Use unsafe?
As to how many crates use unsafe, out of 3,638 crates analyzed, 1,048 declared at
least one function or block unsafe. That’s just about 29%, although note that
we’re missing the crates which implement unsafe traits (such as Send or
Sync) without any unsafe functions or blocks. To get how often crates use
unsafe, take a look at this cumulative distribution:
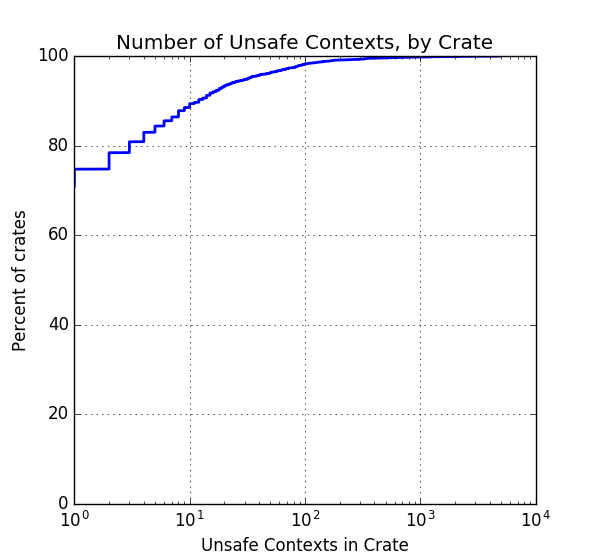
This plot shows, for a given number of unsafe contexts, what percent of
crates use that many or fewer. This relationship between context count and
crate percentage can be used to answer a number of specific questions. For
example, the above statistic (29% of crates use some unsafe contexts) was
determined by noting that the plot’s curve originates at 71% (notice the x axis
is logarithmic). As another example, because the curve crosses 80% at ~3
contexts, we know that 80% of crates declare 3 or fewer unsafe contexts.
We all had our own ideas of how often Rust code uses unsafe, but I at least
found it surprising that around 30% of crates contained unsafe code - I would
have thought it would be fewer. The classic idea is that unsafe code should be
used to build safe abstractions that can be reused again and again. Is this
reuse not happening, or are there just a lot of abstractions that need to be
internally unsafe? An interesting follow-up would be to look at the safe and
unsafe crates in the context of the crates.io dependency graph. Do crates that
use unsafe occupy “fundamental”2 positions in this graph?
How Much unsafe Is There, And Where Does It Come From?
We can also re-investigate how much unsafe code there is from the perspectives of unsafe blocks, functions, and uses, rather than just crates.
Blocks and Functions: Overview
If we go through all the contexts in all the crates and count the number of safe and unsafe contexts we see the following:
| Context Type | Total | Safe | Unsafe | % Unsafe |
|---|---|---|---|---|
| Function | 269,070 | 258,088 | 10,982 | 4.1 |
| Block | 557,118 | 521,547 | 35,571 | 6.4 |
So on the order of 5% of both functions and blocks are unsafe. This provides some insight into the way the safe/unsafe code divide interacts with crate boundaries. If ~30% of all crates use unsafe, but only ~5% of all code is unsafe, it seems that either crates with unsafe code are quite short, or crates with unsafe code also have a lot of safe code. One could do a followup analysis looking at what fraction of code within a crate is unsafe.
Unsafe Uses by Type and Macro Origin
When looking into the different types of unsafe operations that occurred I noticed that a large number of unsafe operations occurred inside code produced by macro expansions, so I displayed the usage counts stratified by not only usage type, but also what type of macro they originated in (if any).
| Source | Deref ptr | Call unsafe Rust function | Call FFI | Use static mut |
Use inline ASM | All uses |
|---|---|---|---|---|---|---|
derive macro |
0 | 12,058 | 0 | 0 | 0 | 12,058 |
| External macro | 3,732 | 9,843 | 161 | 8,841 | 80 | 22,657 |
| Local macro | 801 | 8,176 | 2,087 | 57 | 0 | 11,121 |
| Not a macro | 4,496 | 18,916 | 13,061 | 1,264 | 0 | 37,737 |
| All sources | 9,029 | 48,993 | 15,309 | 10,162 | 80 | 83,573 |
Looking at this table there are a few things to note:
First, by derive macro, I mean that the code was generated by the derive
attribute (TIL that the compiler makes derive work using procedural macros,
and in particular the macro for the PartialEq trait uses an unsafe intrinsic
for performance reasons).
Second, A lot of unsafe operations seem to be generated by macros, especially
external ones. Discounting the operations generated by derive, 33,778 unsafe
operations originate within macros, out of a total of 71,515 unsafe operations.
In terms of percentages, that’s 47% of unsafe operations that originate within
macros, and 32% that originate specifically within external macros. This is a
surprisingly high percentage, but it’s also important to understand some of the
methodology behind the UAST here. Specifically, the UAST determines whether an
operation or context is generated by a macro by asking the compiler whether
that object’s span was generated by a macro (and if so, where that macro was
declared)3. This information actually ends up being fairly course - as
best I can tell the compiler just records whether the tokens in question ever
went through a macro expansion. This means that in a program like this:
fn main() {
let i = 5;
let p: *const i32 = &i;
println!("{}", unsafe { *p } );
}
the *p expression would be registered as “originating inside an external
macro”, even though the programmer typed it themself. Our analysis here could
be much better, and the compiler likely keeps enough information to correctly
categorize the unsafe block in the example above.
Regardless of potential flaws in the analysis, the relationship between macros and unsafe code is interesting. If nothing else it’d be interesting to see which macros are doing all this unsafe code generation.
Furthermore, the interaction between unsafe and closures is especially interesting because historically macro expansion has been a bit more challenging to handle than function calls, and has caused some un-intuitive behavior. Rust has the concept of an “unsafe function” - should it also have the concept of an “unsafe macro”?
My impulse is to say there is no explicit need for them, because they already
exist de facto: if a macro performs unsafe operations which it does not
secure with an unsafe block it provides on its own, then the compiler will
require the programmer to use an unsafe block around the macro invocation.
Blocks by Safety and Macro Origin
I applied the same reasoning to blocks, looking at the sources of the safe and unsafe blocks found in all crate.
| Block Source | Unsafe | Safe | All |
|---|---|---|---|
derive macro |
0 | 83,488 | 83,488 |
| External macro | 7,583 | 189,639 | 197,222 |
| Local macro | 4,751 | 45,923 | 50,674 |
| Not a macro | 23,237 | 202,497 | 225,734 |
| All sources | 35,571 | 521,547 | 557,118 |
One point of interest in this table is the blocks generated by derive
procedural macros. Interestingly, they’re all flagged as safe, despite the fact
that the table before showed that derive produces unsafe operations
sometimes. The reason for this is that there are more than 2 classes of block
safety (safe/unsafe) - the compiler also distinguishes between unsafe blocks
that the programmer provided and unsafe blocks that were generated during
compilation. Currently compiler generated unsafe blocks are flagged as ‘safe’
in the UAST, but if we were to be more precise, the UAST should really have 3
classes of blocks: Safe, Unsafe, and CompilerUnsafe.
The compiler doesn’t directly track whether expressions are compiler generated or not (at least, I haven’t seen anything about this), so we can’t filter out compiler-generated unsafe operations when building the UAST. After the fact we can sort of filter them out by removing all unsafe operations that are not in an unsafe block, but we would still miss those that were generated inside an already-existing user provided unsafe block.
What Style Do Programmers Follow For Unsafe Blocks?
There’s been some discussion around the correct style to use when writing unsafe code. The compiler only requires them to wrap certain operations, but some have argued that large unsafe blocks are better. As an example of the “large” style, consider this (abbreviated) excerpt from cargo:
fn enabled() -> bool {
unsafe {
let me = kernel32::GetCurrentProcess();
let mut ret = 0;
let r = kernel32::IsProcessInJob(me, 0 as *mut _, &mut ret);
assert!(r != 0);
if ret == winapi::FALSE {
return true
}
let job = kernel32::CreateJobObjectW(0 as *mut _, 0 as *const _);
assert!(!job.is_null());
let r = kernel32::AssignProcessToJobObject(job, me);
kernel32::CloseHandle(job);
r != 0
}
}
Notice that while there are a lot of unsafe operations (calling the functions
from kernel32), not everything going on here is strictly unsafe. However,
it’s also true that if someone were to change this code, they should be careful
to understand everything that is going on in order to avoid violating
invariants that make calls to these unsafe functions ‘safe’. Some argue that
large unsafe blocks make this obligation more apparent.
Regardless of which way is best, I was curious which style was more common, so I looked at two metrics:
- Unsafe Block Relative Size: How much of their parent function do unsafe blocks fill (where blocks and functions are sized by the number of statements/final expressions in them and all their child blocks)?
- Unsafe Block Requirement: What amount of code (in terms of statements/final expressions) in an unsafe block actually requires that unsafe block?
Unsafe Block Style by Crate
First I did the analysis by crate. For each crate, I attempted to summarize the unsafe style of the crate by looking at the two statistics listed above. The results are shown as cumulative distributions:


The first graph shows us that in ~80% of crates, blocks tend to fill less than half of their parent (although because total block size can be hard to pin down, 1-to-1 nesting gets marked as 50%). However, the second graph that tells the real story. It shows that the majority of crates (~60%) tend to put unsafe blocks around only the statements and final expressions which require them.
Unsafe Block Style by Block
If we stop splitting the unsafe blocks up by crate, and just look at the distribution of ‘Unsafe Block Requirement’ over all crates, the trend is even more pronounced:

The graph shows that 90% of unsafe blocks are ‘used’ by every statement or final expression in their body, so it seems clear that small unsafe blocks are dramatically more common than large ones.
That being said, the question of style is not entirely answered: perhaps unsafe blocks are most commonly used in one-line functions: this would cause them to simultaneously minimally wrap the unsafe operations and maximally fill their parent function. To answer this question I made a plot which shows the distribution of unsafe blocks across both relative size and requirement.

Notice that while concentration is highest in the upper right, it is higher in the upper left than the lower right, indicating that our earlier analysis is correct: Programmers tend to use small unsafe blocks rather than large ones. Nevertheless, the strong presence on both the upper and right sides indicates that both styles are reasonably popular.
Of course, we could probably do better still - it’d be awesome to find to find a single metric which accurately separates the two styles.
How Important Is FFI In unsafe?
If you’re familiar with Rust, one of the important things you would know about unsafe functions is that all FFI functions (which right now include C functions and system calls) are considered unsafe. One might wonder, “Does FFI make up a substantial portion of unsafe code?” This is somewhat answered by the above table, but I decided to take it one step further and look at how many unsafe blocks/functions only perform FFI, and do no other unsafe operations.
The results were that out of 46,553 unsafe contexts (blocks or functions), 5,484 contain only FFI and 14,007 contain some FFI. That comes out to just under 12% doing only FFI, which, while significant, is not a dominant trend.
Unsafe in Closures?
Unsafe can also interact with closures in an interesting way. For example, consider this function:
fn mk_derefer() -> Box<Fn(*const i32) -> i32> {
unsafe { Box::new(|p: *const i32| *p) }
}
This function produces a closure that does an unsafe thing - dereferencing an
unknown pointer. Yet, Rust provides no way for mk_derefer to precisely
indicate that the closure it returns is unsafe. The best thing to do would be
to mark mk_derefer as unsafe, which sort of gets at the idea, but not quite,
because running mk_derefer will never produce some violation of memory or
type safety, but using the resulting closure may.
At any rate, because this situation is created (on some level) by doing unsafe operations in closures, we’re curious how common unsafe operations are within closures. Some simple numbers:
- There are 783 closures with unsafe operations in them.
- There are 188 crates which have such closures.
- There are 328 closures with unsafe operations in them which are not inside an unsafe block which is in the closure (the unsafe context encloses the closure too).
- There are 100 crates which have such closures.
- There are 35,868 closures in all.
So while closures which do unsafe operations are by no means dominant, they do exist. However, they may not be problematic as our toy example was. Consider the first closure turned up by the third analysis above (taken from Chris Morgan’s anymap):
pub fn insert<T: IntoBox<A>>(&mut self, value: T) -> Option<T> {
unsafe {
self.raw.insert(TypeId::of::<T>(), value.into_box())
.map(|any| *any.downcast_unchecked::<T>()) // <-- This one
}
}
Clearly this is fine - the closure here never escapes, it is just part of
typical Option interactions. This example reminds us though that detecting
problems like mk_derefer is a complex issue - a dataflow question rather than
just a syntactic one.
Some Conclusions
So, in the end, what have we learned?
- A non-trivial number of crates contain unsafe contexts - about 30%.
Probably a few more contain unsafe
impl’s. - A non-trivial amount of code is unsafe - around 5% of blocks and functions.
- Macros introduce a surprising number of unsafe contexts and operations - they account for on the order of 50% of operations / contexts.
- Programmers dominantly just put unsafe blocks around operations that require unsafe - they’re not in the “large unsafe blocks” camp.
- Unsafe is used to do FFI, but not only FFI - about 10% of unsafe contexts exist solely to call FFI, the other 90% do non-FFI unsafe operations.
- Closures may be a tough case for unsafe declarations, but we need better analysis to figure out if any issues arrive in the real world.
It’s also worth repeating that there are some holes in our analysis - we missed
unsafe impl’s, our way of determining which code came from within macros
over-approximates, our heuristics for coding style could be a lot better, and
many more. So these results aren’t set in stone - just a good starting place.
But of course, while interesting, this information is just the beginning of what could be collected. So, the relevant question is:
How can I Get Hacking?
I’m glad you asked!
If you’re curious about some other statistics, such as:
- How often do people ignore the linter and nest unsafe blocks?
- How often do people include unneeded unsafe blocks?
- What are these macros that introduce unsafe code, and why?
- Do any macros produce unsafe operations without wrapping them in unsafe blocks? How are these macros documented?
- How often are safe functions called from unsafe blocks? Internal? External?
- … or any of the other followup questions above …
- … or any of your own questions …
then I encourage you to take the next step. I’ll even promise it will be fairly easy - you won’t have to muck around interfacing with the compiler or waiting several hours to compile all the crates. You’ll even be able to stick to the command line if you don’t want to write Rust programs.
Follow this link to a 15 minute quickstart on how to analyze UnsafeASTs, and keep me posted on what you find out!
Acknowledgements
I by no means did this alone - I’m indebted to Steve Chong, Lucas Waye, and Niko Matsakis for their ideas, inspiration, direction, and questions.
-
This is a small lie, because the Rust compiler uses LLVM as its backend, and LLVM is written in C++. That being said, the entirety of the Rust compiler frontend is written in Rust. ↩︎
-
By fundamental, I mean that lots of things depend of them, and/or they don’t depend on much. ↩︎
-
Furthermore, the compiler doesn’t specifically track what is generated using
derive- that information is determined using a blatant hack. ↩︎