
Download the Visual Genome dataset here.
Download the VRD dataset here.
Download the CLEVR dataset here.
@inproceedings{krishna2018referring,
title={Referring Relationships},
author={Krishna, Ranjay and Chami, Ines and Bernstein, Michael and Fei-Fei, Li},
booktitle={IEEE Conference on Computer Vision and Pattern Recognition},
year={2018}
}

Given a visual relationship, we learn to utilize it to difference between different entities in an image. We can localize which person is kicking the ball versus which person is guarding the goal.

We design an iterative model that learns to use predicates in visual relationships as attention shifts, inspired by the moving spotlight theory in Psychology. Given an initial estimate of the ball, it learns where the person kicking it must be. Similarly, given an estimate of the people, it will learn to identify where the ball must be. By iterating between these estimates, our model eliminates other instances and is able to focus on the correct instances.
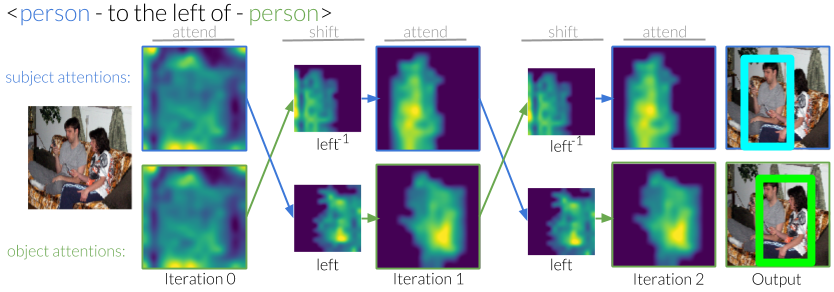

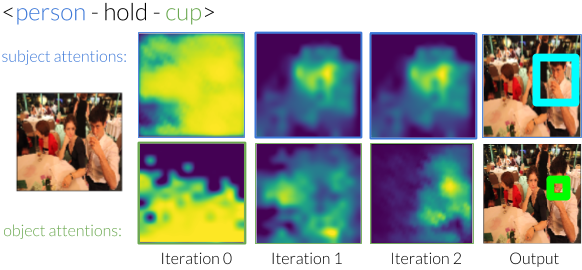
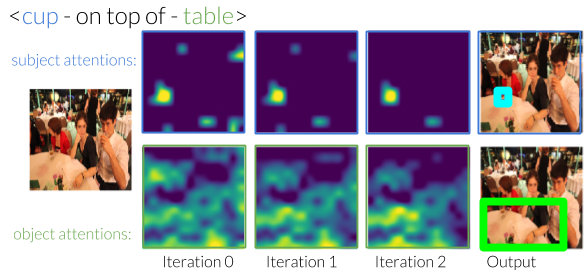
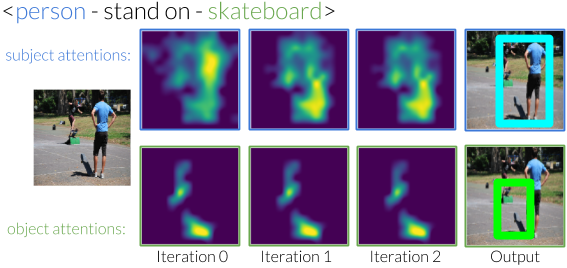

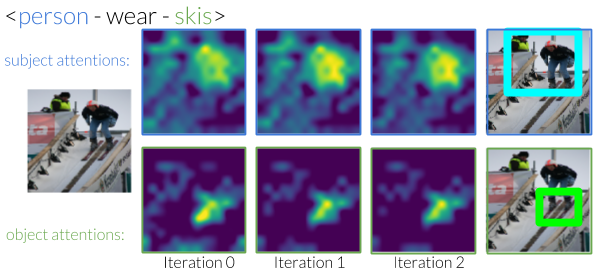
Without any supervision to guide the shifting process, our model generates shifts that are interpretable. For example, when moving attention from a subject that is to the "left of" the object, it learns to shift the attention to the right.





