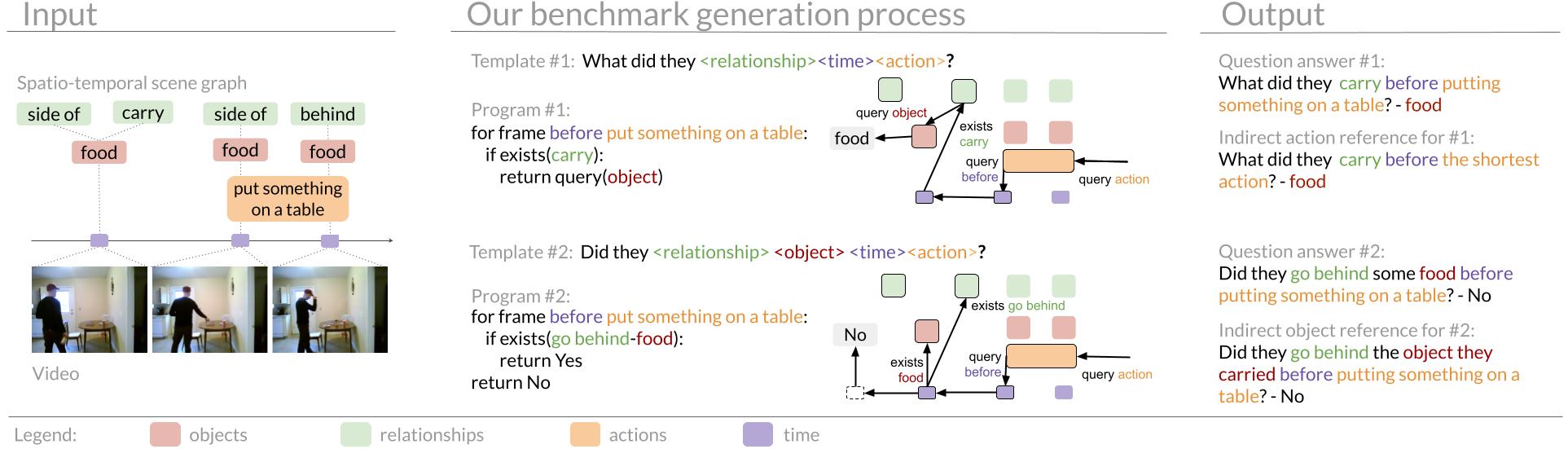
Action Genome Question Answering (AGQA)
Visual events are a composition of temporal actions involving actors spatially interacting with objects.
When developing computer vision models that can reason about compositional spatio-temporal events, we need benchmarks
that can analyze progress and uncover shortcomings. Existing video question answering benchmarks are useful, but they
often conflate multiple sources of error into one accuracy metric and have strong biases that models can exploit, making
it difficult to pinpoint model weaknesses. We present Action Genome Question Answering (AGQA), a new benchmark for compositional
spatio-temporal reasoning. AGQA contains 192M unbalanced question answer pairs for 9.6K videos. We also provide a balanced
subset of 3.9M question answer pairs, 3 orders of magnitude larger than existing benchmarks, that minimizes bias by balancing
the answer distributions and types of question structures. Although human evaluators marked 86.02% of our question-answer
pairs as correct, the best model achieves only 47.74% accuracy. In addition, AGQA introduces multiple training/test splits to
test for various reasoning abilities, including generalization to novel compositions, to indirect references, and to more
compositional steps. Using AGQA, we evaluate modern visual reasoning systems, demonstrating that the best models barely perform
better than non-visual baselines exploiting linguistic biases and that none of the existing models generalize to novel compositions
unseen during training.
AGQA 2.0
We additionally release AGQA 2.0, which incorporates several updates,
most notably employs a stricter balancing procedure to more effectively mitigate language bias.
This benchmark contains 96.85M question answer pairs and a balanced subset of 2.27M question answer pairs.
With the updated balancing procedure, no language-only model performs with more than 51% accuracy on questions with only two answers.