

Inferring and Executing Programs for Visual Reasoning
Abstract
Existing methods for visual reasoning attempt to directly map inputs to outputs using black-box architectures without explicitly modeling the underlying reasoning processes. As a result, these black-box models often learn to exploit biases in the data rather than learning to perform visual reasoning. Inspired by module networks, this paper proposes a model for visual reasoning that consists of a program generator that constructs an explicit representation of the reasoning process to be performed, and an execution engine that executes the resulting program to produce an answer. Both the program generator and the execution engine are implemented by neural networks, and are trained using a combination of backpropagation and REINFORCE. Using the CLEVR benchmark for visual reasoning, we show that our model significantly outperforms strong baselines and generalizes better in a variety of settings. Justin
Justin  Bharath
Bharath  Laurens van
Laurens van  Judy Hoffman
Judy Hoffman
 Fei-Fei Li
Fei-Fei Li
 Larry Zitnick
Larry Zitnick
 Ross Girshick
Ross Girshick
 Download paper (arXiv)
Download paper (arXiv)
To appear at ICCV 2017 (Oral)
Method
Our model consists of two components:
The program generator reads the text of the question
and outputs a program that can be executed to answer the question.
The program generator is is implemented as LSTM sequence-to-sequence
model.
The execution engine executes programs on images to answer
questions, implemented as a neural module network [1]. It learns a separate
module for each basic function; these modules are assembled according
to the predicted program, giving a customized neural network
architecture for each question.
Code
Our code is available on GitHub. We provide pretrained models used in the paper as well as instructions for training new models.
CLEVR-Humans Dataset
We collected a dataset of questions about CLEVR images written by people on Amazon's Mechanical Turk.In the paper we use this dataset to show that our model can generalize from the synthetic langauge of the CLEVR dataset to questions using freeform natural language.
The dataset consists of:
- A training set of 17,817 questions
- A validation set of 7,202 questions
- A test set of 7,145 questions
Download CLEVR-Humans (588 KB)
Images for CLEVR-Humans are available in the CLEVR Dataset.
All data licensed under the
Creative Commons CC BY 4.0 license.
 Q:
What shape is the object reflected in the blue cylinder?
Q:
What shape is the object reflected in the blue cylinder?
A: cube
 Q:
What number of cylinders share the same color?
Q:
What number of cylinders share the same color?
A: 2
 Q:
How many objects are not purple and not metallic?
Q:
How many objects are not purple and not metallic?
A: 2
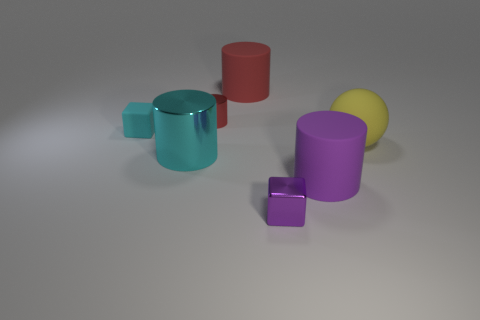 Q:
What color is the object partially blocked by the purple cylinder?
Q:
What color is the object partially blocked by the purple cylinder?
A: yellow