
Compositional Attention Networks for
Machine Reasoning
Drew A. Hudson & Christopher D. Manning
 How should we design a neural network that doesn’t just learn, but also thinks? We are undeniably in the midst of an AI golden age, with machines learning to drive cars, play video games and answer questions, but a closer inspection reveals that contemporary AI may not yet be as smart as it seems. Neural networks suffer from key deficiencies: they rely on vast amounts of data for training, are narrowly designed for particular tasks only, and fail to generalize well to even the slightest changes in settings. In contrast to an artificial system, a child can learn to play a typical iPhone game in a couple of minutes. In contrast to an automated voice assistant, a human won’t get confused when being asked a new question, even if she hasn’t heard a similar one before.
How should we design a neural network that doesn’t just learn, but also thinks? We are undeniably in the midst of an AI golden age, with machines learning to drive cars, play video games and answer questions, but a closer inspection reveals that contemporary AI may not yet be as smart as it seems. Neural networks suffer from key deficiencies: they rely on vast amounts of data for training, are narrowly designed for particular tasks only, and fail to generalize well to even the slightest changes in settings. In contrast to an artificial system, a child can learn to play a typical iPhone game in a couple of minutes. In contrast to an automated voice assistant, a human won’t get confused when being asked a new question, even if she hasn’t heard a similar one before.
While current AI models are remarkably effective at learning direct mappings between inputs and outputs, they do not demonstrate a coherent and transparent “thinking process” that would lead to their predictions. While they shine at intuitive tasks and reactive decision making, they are limited in their ability to explicitly combine pieces of information together in a rational manner to arrive at new conclusions. What deep learning systems are still missing is reasoning.
 To give an example, suppose you have been asked the following: “What is the yellow thing that is right of the small cube in front of the green object made of?”. How would you approach such a question? Well, there are several strategies to go about that, but it’s clear that the question has to be solved in steps – traversing from one object to a related one, iteratively progressing towards the final solution.
To give an example, suppose you have been asked the following: “What is the yellow thing that is right of the small cube in front of the green object made of?”. How would you approach such a question? Well, there are several strategies to go about that, but it’s clear that the question has to be solved in steps – traversing from one object to a related one, iteratively progressing towards the final solution.
This form of structured multi-step reasoning is vital for doing any sort of problem solving task, and is used commonly throughout all aspects of our lives. Indeed, the ability to solve complex problems is one of the hallmarks of human intelligence. Theories of cognitive development suggest that children’s intellect goes through several stages: starting as intuitive thinking that is based on reflexes in early infancy, but then shifting towards more organized and logical planning and reasoning as time passes by. In contrast to current AI systems that mainly excel in imitation, children learn to link between causes and effects, and build abstract and symbolic mental representations of the world that allow them to reason in a structured and cogent manner.
What does it take to build an artificial model that demonstrates such coherent reasoning? How can we make neural networks more capable of accomplishing tasks that require this sort of slower and more deliberate thinking? Traditionally, the concept of reasoning is associated with classic ideas from the fields of logic and philosophy, defined as the formal process of passing from known statements to new inferences. However, more broadly speaking, it can also be considered as any way in which thinking moves from one idea to a related one. And indeed, when we make sense of the world around us, drawing new conclusions based on given information, or making some multi-step plan towards a goal, we don’t rely on strict theorem proving to do so. If we are interested in creating neural networks that can do the same, it thus may be more promising to build them in ways that encourage them to acquire reasoning capabilities organically, through their interaction with the data – from the ground up.

Towards this goal, our recent paper presents the MAC network, an end-to-end differentiable neural network structured for performing sequential concrete reasoning. Our network approaches problems by decomposing them into a series of explicit reasoning steps, each performed by a MAC cell. The MAC cell (standing for Memory, Attention and Composition) is a recurrent cell, similar to a GRU or an LSTM. However, in contrast to these classic architectures, it has two hidden states – control and memory, rather than just one:
- The control state stores the identity of the reasoning operation that should be performed. For instance, locating the green block, looking left to a current object, or performing counting or some logical operation.
- The memory state holds the intermediate result that has been computed in the recurrent reasoning process so far. It iteratively aggregates information from some knowledge source, such as the image, reflecting the outcome obtained by performing the series of reasoning operations up to this point in the process.
The separation between control and memory follows a long tradition that is common both in computer architectures as well as in software engineering. In the most basic terms, a conventional computer operates by serially going through a sequence of instructions: (1) First, the controller fetches and decodes an instruction. (2) Then, information is retrieved from the memory, as dictated by the current instruction. Finally (3) the instruction is executed, taking into account the information that was retrieved, and the cycle repeats.
 This is a useful abstraction, because in contrast to black-box neural networks that learn to approximate direct transformations between inputs and outputs, here we have a universal design that more strongly highlights the computation process itself, rather than just its end result. If we build a neural network based on this design pattern, explicitly structuring it like a small computer, it will serve as a prior that can guide the network to approach problems by decomposing them into steps, providing a better insight into the internal computation that the network undergoes in producing its predictions.
This is a useful abstraction, because in contrast to black-box neural networks that learn to approximate direct transformations between inputs and outputs, here we have a universal design that more strongly highlights the computation process itself, rather than just its end result. If we build a neural network based on this design pattern, explicitly structuring it like a small computer, it will serve as a prior that can guide the network to approach problems by decomposing them into steps, providing a better insight into the internal computation that the network undergoes in producing its predictions.
This is the observation that motivated us in designing the MAC cell. It has an explicit control unit, read unit and write unit, and, just like a CPU, it operates in this cyclic, recurrent manner. Looking at the question, the control unit computes at each step a reasoning operation by selectively attending to some of the question words, and stores that in the MAC’s control state. For instance, the reasoning operation can be “the blue thing” to indicate that the cell should find a blue object, or the words “how many” to indicate that the cell should perform counting. Formally, the operation is represented by computing an attention distribution over the question – a probability distribution over the words that expresses the degree to which the model is looking at each of them.
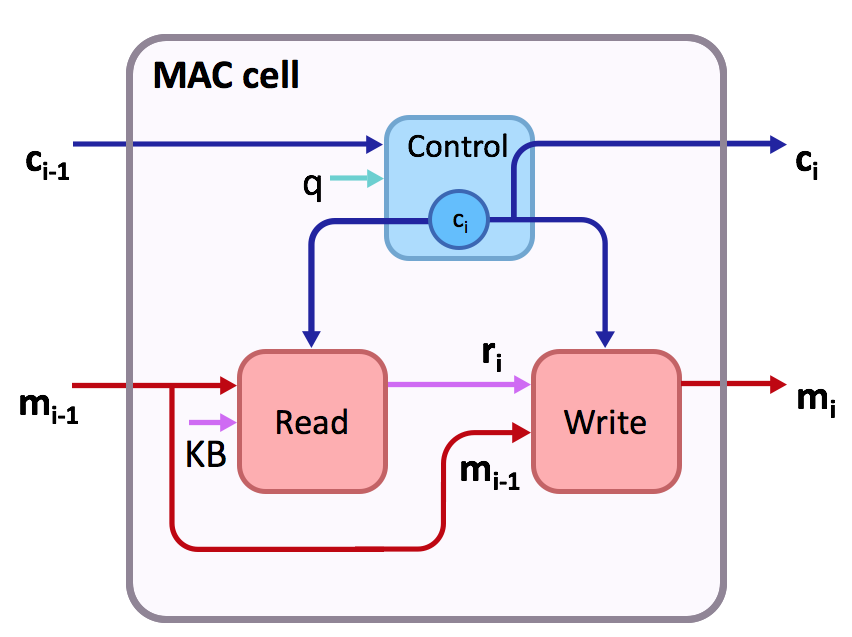 Then, the reasoning operation is performed: the read unit extracts relevant information from some knowledge source, in our case, the image, selectively focusing on some of its regions. Here again, we use an attention distribution over the knowledge base to represent the extracted information. Afterwards, the write unit integrates together the new information that was just extracted with the memory state from the prior step, which stores the previous intermediate result. The outcome of this combination is the new memory state – the result obtained from executing the current reasoning operation, advancing us one more step towards the final answer.
Then, the reasoning operation is performed: the read unit extracts relevant information from some knowledge source, in our case, the image, selectively focusing on some of its regions. Here again, we use an attention distribution over the knowledge base to represent the extracted information. Afterwards, the write unit integrates together the new information that was just extracted with the memory state from the prior step, which stores the previous intermediate result. The outcome of this combination is the new memory state – the result obtained from executing the current reasoning operation, advancing us one more step towards the final answer.
Let’s step through an example of the model in action. Consider again the question presented above: “What is the yellow thing that is right of the small cube in front of the green object made of?”. As we mentioned, a good strategy for dealing with such a question is to compute the answer in steps: looking first at the green cube in the middle of the image, then finding the purple cube in front of it, and finally locating the yellow cylinder, and responding “rubber”. Note that there are no direct references either to the purple cube or the cylinder in the question, which means that in order to identify the relevant objects, we have to perform valid reasoning, transitively finding an object based on its relation to the one we’ve found before. It would be nice if a neural network could learn to do that, returning not just the answer to the question, but also the computation process that leads to it. MAC is capable of doing so:
- As we can see in the figure, the model first attends to the “the green object”, storing the phrase into the control state c1 and the corresponding image patch of the block into the memory state m1.
- Then, MAC attends to the “small cube in front”, storing that operation in c2. Now we get to the nice part: by considering both the previous intermediate result m1, that points to the green cube, and the current reasoning operation c2, that indicates we should look for the small cube in front, MAC “understands” (after enough training) it should look for the small cube in front of the green object, successfully finding the purple cube, storing that into m2. Note how the model doesn’t get confused by the other small cubes in the picture – it looks specifically for the one in front of the green cube, among all other distractors.
- The same case repeats in the next iteration, when the model combines the visual information about the purple cube with the linguistic information about “the yellow thing that is right” of it, correctly locating the yellow cylinder among the other yellow objects, and giving the right answer: “rubber”.

As you can see through the following examples, MAC’s reasoning skills are not limited just to tracking transitive relations between objects. Attention maps over the question and image show how the model coherently reasons over questions that involve counting, comparisons and logical operations:

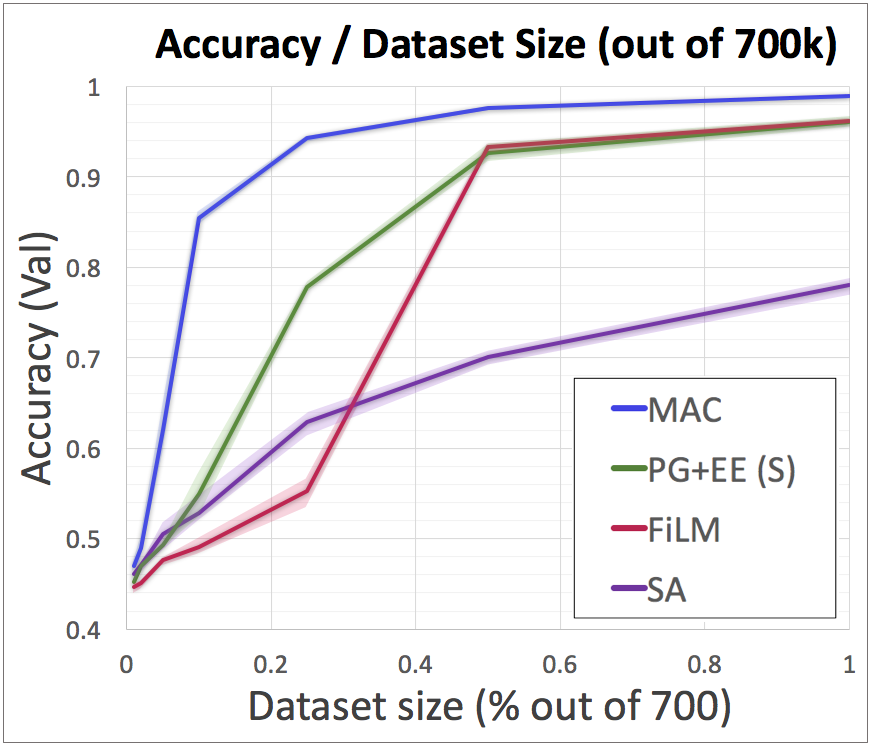 We have performed a variety of experiments to measure MAC performance on the CLEVR task and its associated datasets. One of the most exciting results we achieved was about the ability of MAC to learn much faster and generalize from significantly less data than other recently proposed architectures. In particular, when exposed to just 10% of the CLEVR training set, our model still answered questions with a high accuracy of 86%, whereas the alternative approaches barely performed above the baseline (namely, in the low fifties) when trained with the same settings. See further results in our paper!
We have performed a variety of experiments to measure MAC performance on the CLEVR task and its associated datasets. One of the most exciting results we achieved was about the ability of MAC to learn much faster and generalize from significantly less data than other recently proposed architectures. In particular, when exposed to just 10% of the CLEVR training set, our model still answered questions with a high accuracy of 86%, whereas the alternative approaches barely performed above the baseline (namely, in the low fifties) when trained with the same settings. See further results in our paper!
 A key point about our approach is that we don’t rely on any strong supervision about the reasoning processes that are needed to answer the questions. Rather, MAC can infer them on its own. As we’ve seen above, its computer-like structure helps it in doing so, encouraging the model to address questions by going through a coherent sequence of algorithmic steps: The MAC network composes together a series of “instructions”, each pointing to some question words. It has a recurrent memory structure that the cells interact with when performing each instruction, adapting their behavior to support varied operations while still having one general-purpose architecture. Finally, it uses attention to represent both the reasoning operations as well as their outcomes, resulting in recurrent states that, in contrast to the hidden states of LSTMs and RNNs, have clearer interpretations. Overall, we get a model that leverages Memory, Attention and Composition to support transparent multi-step reasoning.
A key point about our approach is that we don’t rely on any strong supervision about the reasoning processes that are needed to answer the questions. Rather, MAC can infer them on its own. As we’ve seen above, its computer-like structure helps it in doing so, encouraging the model to address questions by going through a coherent sequence of algorithmic steps: The MAC network composes together a series of “instructions”, each pointing to some question words. It has a recurrent memory structure that the cells interact with when performing each instruction, adapting their behavior to support varied operations while still having one general-purpose architecture. Finally, it uses attention to represent both the reasoning operations as well as their outcomes, resulting in recurrent states that, in contrast to the hidden states of LSTMs and RNNs, have clearer interpretations. Overall, we get a model that leverages Memory, Attention and Composition to support transparent multi-step reasoning.
We are excited to explore our model for other tasks and domains, such as textual reasoning, reading comprehension and real-images VQA, and will keep you updated as we achieve new results. Thank you for reading! :-)
________________________________________
p.s. Here are some more examples of the model’s predictions. See how the model correctly handle questions that involve obstructions, object uniqueness, relative distances, superlatives, varied vocabulary.

Q: What is the shape of the large item, mostly occluded by the metallic cube? A: sphere ✓

Q: What color is the object that is a different size? A: purple ✓

Q: What color ball is close to the small purple cylinder? A: gray ✓

Q: What color block is farthest front? A: purple ✓

Q: Are any objects gold? A: yes ✓

Q: What color is the metallic cylinder in front of the silver cylinder? A: cyan ✓

Q: What is the object made of hiding behind the green cube? A: rubber ✓

Q: What is the color of the ball that is farthest away? A: blue ✓

Q:How many matte cubes are there? A: 2 ✓

Q:How many spheres are pictured? A: 4 ✓

Q: How many square objects are in the picture? A: 4 ✓

Q: What object is to the far right? A: cube ✓

Q: Are the yellow blocks the same? A: no ✓

Q: What shape is the smallestt object in this image? A: sphere ✓

Q: What object looks like a caramel? A: cube ✓

Q: Can a ball stay still on top of one another? A: yes (no) ✗

Q: What color is the center object? A: blue ✓

Q: How many other objects are the same size as the blue ball? A: 7 ✓

Q: How many small objects are rubber? A: 2 ✓

Q: What color is the largest cube? A: yellow ✓

Q: What shape are most of the shiny items? A: sphere ✓

Q: What is the tan object made of? A: rubber ✓

Q: Are half the items shown green? A: yes (no) ✗

Q: What color object is biggest? A: blue ✓

Q: Which shape is a different color from the others? A: cylinder ✓
You can find more details and examples in our paper!